
Wikipedia Diskussion:Schreibweise von Zahlen
aus Wikipedia, der freien Enzyklopädie
[Bearbeiten] Zifferngruppierung
[Bearbeiten] Schreibweise von Zahlen
Zur "Schreibweise von Zahlen": auf manchen Seiten sind die Zahlenangaben zumindest missverständlich. Ich schlage daher folgende Empfehlung vor:
- Punkt als Dezimalpunkt
- Komma als Tausender-Trennung
- keine Blanks in Zahlen
HaJo Gurt 17:58, 18. Mai 2003 (CEST)
- Was spricht gegen die im deutschsprachigen Raum geläufige Verwendung von Punkt und Komma? --Kurt Jansson 19:32, 18. Mai 2003 (CEST)
-
- eigentlich nichts, auch blanks in Form von & nbsp ; zur Vermeidung von zeilenumbrüchen find ich i.O. -- Martin 19:42, 18. Mai 2003 (CEST)
-
- Zahlenangaben aus irgendwelchen Quellen (z.B. englisches Wiki) würde ich möglichst nicht von Hand umformatieren wollen - aber in en: steht z.B. 3.5"Disk (bei solch einfachen Zahlen natürlich kein Problem)
- In Handbuch und FAQ gibt es zu "Zahlen" keinen Abschnitt
- Formatierung mit & nbsp ; kompliziert das Editieren HaJo Gurt 21:23, 18. Mai 2003 (CEST)
-
-
- Du willst sagen es ist weniger Arbeit, alle bestehenden Zahlenangaben der deutschen Wikipedia zur englischen Schreibweise zu ändern, damit man danach bei Übernahme von Zahlen aus englischen Artikeln keine Kommas mehr durch Punkte ersetzen muss? :-) --Kurt Jansson 21:38, 18. Mai 2003 (CEST)
-
-
- & nbsp ; finde ich nicht in Ordnung. Leerzeichen zwischen Ziffern sollten wenn das notwenig ist von der Software durch & nbsp ; ersetzt werden und nicht im Artikel selbst. Also: ist das ein Bug? --Nichtich 00:09, 28. Mai 2003 (CEST)
-
-
- Also ich seh das Problem momentan nicht ganz. Was haben Leerzeichen zwischen Ziffern verloren? Oder geht's um den Anschluß einer Einheit an die Zahl und dortige Verwendung von & nbsp ; ? Da wird man allerdings Probleme haben, das automatisch durch die Software machen zu lassen. --Warp 00:18, 28. Mai 2003 (CEST)
-
- Auf keinen Fall Komma als Tausendertrennzeichen. Das führt zu Missverständnissen, heißt 19,123 jetzt neunzehn oder neunzehntausend? Im Deutschen ist die Regel eigentlich eindeutig, dass das Koma das Dezimaltrennzeichen darstellt, auch wenn die angelsächsische Darstellung immer häufiger anzutreffen ist. Am Besten ist als Tausendertrennzeichen ein schmales nichttrennbares Leerzeichen (19 123), das lässt sich allerdings derzeit mit Wiki-Syntax noch nicht schreiben. Im Augenblick verwende ich immer 19'123, das ist zwar auch nicht schön, aber wenigsten kann es nicht zu Missverständnissen führen. - WeißNix 23:39, 29. Mai 2003 (CEST)
-
- Naja, das könnte auch eine mißglückte Uhrzeit oder Gradangabe oder sonstwas sein. Ich halte es noch immer für die beste Idee, in der deutschen Wikipedia Deutsch zu verwenden. Ausnahmen bestätigen die Regel ;-) Tausendertrennzeichen machen sowieso erst ab 7 Ziffern Sinn (1234 | 12345 | 123456 | 1.234.567) und dann ist es auch eindeutig. --Nichtich 00:15, 30. Mai 2003 (CEST)
-
-
- Eine andere Alternative ist, einfach normale nichttrennbare Leerzeichen ( ) zu nehmen. Da Leerzeichen in der Proportionalschrift generell nicht so groß sind, sieht das gar nicht so schlecht aus: 1 000 000. Was macht die Wikipedia eigentlich aus \, im <math>,-Modus (TeX-Mathe-Thinspace)? Mal sehen:
 Aha, in der Vorschau wird zumindest ein Bild eingeblendet - nicht so ideal. --212.183.119.237 19:47, 12. Jun 2003 (CEST)
Aha, in der Vorschau wird zumindest ein Bild eingeblendet - nicht so ideal. --212.183.119.237 19:47, 12. Jun 2003 (CEST)
- Eine andere Alternative ist, einfach normale nichttrennbare Leerzeichen ( ) zu nehmen. Da Leerzeichen in der Proportionalschrift generell nicht so groß sind, sieht das gar nicht so schlecht aus: 1 000 000. Was macht die Wikipedia eigentlich aus \, im <math>,-Modus (TeX-Mathe-Thinspace)? Mal sehen:
-
-
-
-
- Noch besser   : 1 000 000. Allerdings gibt das wieder mehr kryptischen Code auf den Editseiten, für jemanden, der diese Sysntax nicht kennt. Die beste Lösung wäre eigentlich eine Softwarelösung, die das automatisch einfügt. Aber da haben wir glaube ich viel drängendere Probleme in der Wikipedia. - WeißNix 21:30, 12. Jun 2003 (CEST)
-
-
-
-
-
-
-   hat den Nachteil, dass es auf Mozilla 1.2/Linux (zumindest bei mir) nicht korrekt dargestellt wird. Da Netscape 6 auf Mozilla beruht, vermute ich denselben Bug auch für Netscape. Nun ist das zwar klar ein Software-Bug (vielleicht auch ein Fehler im verwendeten Zeichensatz), aber da Mozilla (und erst recht Netscape, falls das Problem dort auch besteht) m.E. nicht gerade ein exotischer Browser sit, halte ich eine Nichtunterstützung für keine gute Idee. BTW, Mozilla zeigt bei mir die Buchstabenkommbination
-
-
-
TH
SP
-
-
-
-
- (in der Größe eines Zeichens für alle vier Buchstaben) für den thinspace an. --212.183.119.144 21:59, 12. Jun 2003 (CEST)
-
-
-
Aus meiner Sicht darf es keine Zweifel an einer Zahlenangabe geben- und wenn sie manuell umformatiert werden muß, so wie jeder x-beliebige fremdsprachige Artikel ja auch Wort für Wort übersetzt werden muß. Die im deutschen Sprachraum allgemein gebräuchlichen Zahlenformate sind u.a.: "Komma" für Dezimaltrenner, "Punkt" für Tausender-Trenner, "Hochomma" (') für Gradzahlen (geometrisch), "Anführung" (") für Sekunden-Angaben (geometrisch), "°" für Gradzahlen (geometrisch und Temperatur), "Doppelpunkt" (:) für Trennung von Stunden und Minuten. Dies sollten wir im Handbuch vorschreiben und anwenden. --Michael 22:24, 12. Jun 2003 (CEST)
Weil es auch in diesem Zusammenhang passt: Die Artikel mit "1 E6 m²" und ähnliches, die in letzter Zeit auftauchen: Die Schreibweise "1E6" (übreigens ohne Abstand) dürfte nur von einer Minderheit aller potentiellen Leser überhaupt verstanden werden. Ich würde vorschlagen, dass die Richtlinien die Vermeidung solcher "Computerzahlen" empfehlen sollten (insbesondere in Titeln). --212.183.119.183 15:26, 13. Jun 2003 (CEST)
Ich halte die Verwendung des Punkts (oder Kommas) als Tausendertrennzeichen für problematisch. Man weiß bei Zahlen wie 1.234 oft nicht, ob jemand hier unter Missachtung der deutschsprachigen Schreibregeln einen Punkt als Dezimaltrenner verwendet hat oder tatsächlich 1234 meint. Schreibweisen wie 1 234 oder 1'234 sind da eindeutiger. (Bei letztere Schreibweise besteht auch keine Verwechslungsgefahr mit Grad-/Minutenangaben: Es sind immer drei Ziffern, die folgen, während bei Minuten entweder keine Ziffern folgen oder die Sekundenangabe, die maximal zweistellig ist.) -- 3247 17:50, 26. Sep 2003 (CEST)
Die Schreibweise mit geschütztem schmalem Leerzeichen als Tausenderkennzeichen, sagt mir am meisten zu. Aus technischen Gründen würde ich zunächst ein geschütztes Leerzeichen empfehlen, dies bei allgemeiner Verbreitung ordentlicher Browser ersetzen. In Zahlenwüsten/Tabellen kann man auch einen Punkt nehmen. Das Komma als Dezimalzeichen ist beizubehalten. Wo kann man denn so allgemeine Sachen diskutieren? Gibt's eine vielgelesene Abstimmungsliste oder so was? Mir ist es wichtig eine allgemein getragene Festlegung zu haben, sonst wird der Richtlinienartikel alle Monate geändert und man hat Artikel mit einem Punkt als Dezimaltrenner gemischt mit normalen Artikeln. (DIN 5008 bezieht sich auf den Büro- und Verwaltungsbereich - wir wollen keine Amtsschreiben verfassen und unser Ergebnis soll auch nicht möglichst gut per OCR zu erfassen sein.) --Lutz 12:09, 21. Mär. 2008 (CET)
[Bearbeiten] Widerspruch: Das entspricht weder Duden noch DIN 5008
Zur Gliederung von Zahlen wird kein Punkt mehr verwendet. Statt 1.234,567.89 sollte es m. E. also 1 234,567 89 heißen, wobei man ein geschütztes Leerzeichen verwenden sollte ( ).
Nach DIN 5008 wird bei einstelligen Uhrzeiten stets eine führende Null verwendet, also 08:15 und nicht 8:15
- Mag ja sein, dass es nicht der DIN entspricht. So ein Pech aber auch. Wir schreiben trotzdem so. Weil's praktischer ist. Ätsch. Uli 19:08, 30. Okt 2003 (CET)
- Wie auch immer wir uns nach ausgiebiger Diskussion entscheiden werden, ob &bsp; oder Trennpunkt, möchte ich hier mal festhalten, daß der Duden zwar eine wichtige Referenz ist, aber (Genauso übrigens wie DIN-Normen) absolut keine gesetzliche Bindungswirkung entfalten. Das wollte ich mal in aller Deutlichkeit feststellen, nachdem in letzter Zeit ständig darauf herumgeritten wird, was der Duden alles zu Textformatierung sagt (ob sinnvoll und praktikabel oder nicht). -- Sansculotte 20:01, 30. Okt 2003 (CET)
- DIN 5008 hat ohnehin die ursprüngliche deutsche Schreibweise der Uhrzeit (mit Punkt) zugunsten der englischen (mit Doppelpunkt) aufgegeben. Nach Duden war früher 08:15 Uhr falsch, heute wird es akzeptiert, weil es so in DIN 5008 steht, aber 8.15 Uhr ist (nach Duden) nach wie vor die übliche Schreibweise. Geht man nach dem Duden, darf man also bei 8.15 Uhr (klassische Schreibweise) die führende 0 weglassen, bei 08:15 Uhr (angelsächsische Schreibweise, DIN 5008) dagegen nicht. Dass der Duden nicht gesetzlich bindet ist natürlich richtig. -- 3. Jun 2005
- Also in der Geschäftswelt habe ich noch NIE eine Trennung durch ein Leerzeichen gesehen. Der Punkt ist in Deutschland Standart. 83.124.34.33 21:43, 29. Dez 2005 (CET)
- Einige Leute schreiben führende Nullen auch in "ausgeschriebenen" Daten z.B. 06. Juni 2007. Dabei wird laut Duden und Norm bei ausgeschriebenen Monatsnamen die Null fortgelassen, weil es dann leichter lesbar ist. Lieber Ulrich.fuchs, ich persönlich lasse bei Datum und Uhrzeit auch oft die führenden Nullen weg. Alte Anzeigetreiber-ICs kannten noch keine automatische Nullenunterdrückung - aus jener Zeit stammen wesentliche Teile der DIN 5008-Norm! Aber seit gut dreißig Jahren beherrschen die ICs das Ripple-Blanking (automatische Nullenunterdrückung) und die meisten Digitaluhren stellen die Uhrzeit daher ohne führende Null dar, z.B. 8:15 bzw. 8:15:06. Sollen hingegen Manipulationen in Schriftstücken erschwert werden, sind führende Nullen anzuraten.Joli Tambour 00:00, 25. Sep. 2007 (CEST)
- DIN 5008 bezieht sich auf den Büro- und Verwaltungsbereich - wir wollen keine Amtsschreiben verfassen und unser Ergebnis soll auch nicht möglichst gut per OCR oder sonstiger automatischer Texterfassung zu erfassen sein. Ich schreibe '6.6.2008' '9:02 Uhr', weil ich überflüssige Nullen überflüssig finde. Der Punkt in der Uhrzeit hat mich schon immer irritiert, wohl weil er einem Dezimalpunkt gleicht. Ohne 'Uhr' sieht es so nackt aus. Das Datum als 2008-06-06 mag logischer und mal kurz nützlich gewesen sein, als die Rechner noch zu doof waren, 'unser' Datum zu lesen und danach zu sortieren. Solange es nicht in allgemeiner Schrift verbreitet ist, würde ich es nicht in der Wikipedia pushen. In Tabellen oder so weiche ich von obigen Punkten ab. In der Wikipedia orientiere ich mich gerne an Vorgaben zwecks Vereinheitlichung. --Lutz 12:09, 21. Mär. 2008 (CET)
[Bearbeiten] Tausendertrennung durch Leerzeichen!
In der Einleitung heißt es, es sei "hierzulande" üblich, mit Punkten zu trennen und das aber 7 Stellen zu tun. Das hat sich wohl jemand aus den Fingern gesogen. Denn laut DIN 5008 (sog. "Sekretärinnen-Norm" (-: ) sollen Tausenderstellen im Deutschen nicht mehr durch Punkte, sondern durch kleine Leerzeichen, die im Web durch normale Leerzeichen ersetzt werden, umgesetzt werden. Daher sollte "15 000" statt "15.000" oder "15000" verwendet werden. Siehe auch: "Duden - Regeln für die Textverarbeitung" ( http://www.duden.de/service/download/textverarbeitung_duden1.pdf ), sowie Webtypografie. Auch die genannten sieben Stellen halte ich für sehr anzweifelbar, unüblich und willkürlich. Tatsächlich kann (!) bei vierstelligen Zahlen der Punkt wegfallen, also 1000 statt 1 000 82.82.117.235 17:56, 20. Nov 2003 (CET)
- Kleine Anmerkung: In der Schweiz trennt man übrigens nicht mit Leerzeichen, sondern mit einem Apostroph, also 15'000 statt 15 000. Ich empfehle aber, dass auch Schweizer hier lieber gegen ihre Natur Leerzeichen verwenden. 82.82.117.235 17:59, 20. Nov 2003 (CET)
-
- Schön, dass wir hier auf die DIN sch... Wir nehmen Punkte, und Du akzeptierst das jetzt mal gefälligst. Uli 18:14, 20. Nov 2003 (CET)
- Nein!
Siehe auch Diskussion:Schweiz Filzstift 15:40, 23. Feb 2004 (CET)
- Nein!
- Schön, dass wir hier auf die DIN sch... Wir nehmen Punkte, und Du akzeptierst das jetzt mal gefälligst. Uli 18:14, 20. Nov 2003 (CET)
- An Deinem Beitrag kann man klar den Nachteil von Leerzeichen sehen, schau Dir diesen Screenshot an:
 Leerzeichen als Tausendertrenner werden umgebrochen
Leerzeichen als Tausendertrenner werden umgebrochen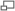
- Dort wird die 15.000 mit Leerzeichen durch den Umbruch getrennt. Das ist nicht gut. Von allen Benutzern zu verlangen, dass sie verwenden. Daher halte ich den Punkt als Tausendertrenner für die beste Lösung, dass mit den ab 7 Zeichen finde ich sehr willkürlich. 12345 und 123456 finde ich persönlich auch schon schwer erfassbar. -- Dishayloo 12:54, 20. Mai 2004 (CEST)
-
- Das glaube ich Dir auch ohne Screenshot ... Wikipedia-Links mit Leerzeichen werden durch dem Zeilenumbruch genauso getrennt - sollen da deswegen Punkte oder Unterstriche eingefügt werden ? ... Hafenbar 17:22, 27. Mai 2004 (CEST)
-
-
- Warum? Wenn der Link ein Leerzeichen enthält, dann deshalb, weil ein neues Wort beginnt, und da darf ein Umbruch erfolgen. Die Tatsache, dass beide Wörter zum selben Link gehören, ist hierfür unwesentlich. Zahlen sollten aber normalerweise nicht umbrochen werden, egal ob im Link oder anderweitig. --Ce 18:13, 4. Jul 2004 (CEST)
-
-
-
- Noch ein Gedanke: Vielleicht ließe sich ein Software-Feature einbauen, das in nicht-vorformatiertem (also ohne Leerzeichen am Anfang der Zeile) Text den Umterstrich (_) durch einen ersetzt. Dann könnte man die Zahlen als 1_048_576 schreiben, sie würden als 1 048 576 (ohne Umbruch) erscheinen, und alle wären (hoffentlich) glücklich. --Ce 18:21, 4. Jul 2004 (CEST)
-
-
-
-
- Viel einfacher wäre natürlich, wenn die Wikipedia Zahlen mit Leerzeichen generell nicht trennen würde. Das würde einiges vereinfachen. Naja und wenn man mal Zahlen hat, die explizit getrennt werden sollen, etwa in mathematischen Artikeln, kann dafür eine eigene Umgebung geschaffen werden. Mit dieser Lösung werden Normaluser bedient, die nicht darauf achten wollen, unübliche Sonderzeichen (etwa Unterstrich) einzufügen und gleichzeitig können fortgeschrittene User ihren Zeilenumbruch haben, wenn sie möchten. --Cerno 15:10, 8. Sep. 2007 (CEST)
-
-
-
-
-
-
- Dafür! Was regelbasiert laufen kann, da sollte man sich keine Gedanken zu machen müssen. --Lutz 12:09, 21. Mär. 2008 (CET)
-
-
-
Eine Möglichkeit für Trennung mit Weißraum stelle ich hier vor. --Quilbert 問 18:03, 26. Mär. 2008 (CET)
[Bearbeiten] Sperrung eine Unverschämtheit
Nur weil einem Benutzer die in Deutschland gültigen Normen nicht passen, kann er doch nicht allen Wikipedianern eine Pseudo-Norm aufzwingen. Ich weigere mich, mich an diesen Artikel mit bewusst die Normen und den Duden ignorierenden Regeln, zu halten. 82.82.117.235 18:15, 20. Nov 2003 (CET)
- das verstehe ich auch nicht - diese Schreibweise mit dem Leerzeichen wurde schon 1972 empfohlen (DDR), seit wann es Gesetz ist weiß ich nicht Marcela 18:35, 20. Nov 2003 (CET)
-
- Ich gebe zwar den anderen Diskutierenden Recht, dass es sich um eine Norm handelt und an Normen muss man sich nicht zwanghaft halten. Ich frage mich aber, wenn es schon eine Norm gibt, die alles – seit Jahren erfolgreich mit der Leerzeichen-Schreibweise – haarklein regelt, warum man dann in Wikipedia eine eigene Regelung schaffen will. Viele hier haben sich nun an die DIN-Norm gewöhnt, verwenden sie beruflich, und in Wikipedia sollen sich sich auf den seit Jahren nicht mehr üblichen Punkt umstellen? Ich weiß auch, dass viele den Punkt noch verwenden. Aber man kann sich doch jetzt nicht an denen orientieren, die die Rechtschreibung nicht beherrschen. 82.82.117.235 18:49, 20. Nov 2003 (CET)
-
-
- zumal es diesmal keine Diskussion über die neue Rechtschreibung ist *bg* Marcela 18:51, 20. Nov 2003 (CET)
-
-
-
-
- :-) Die Frage ist aber nun, wie weiter vorgegangen werden soll. Uli hat die Seite nun gesperrt. Da kann man noch so gegen anargumentieren, ändern können wir da jetzt nix. Das einzig sinnvolle ist eine Abstimmung, würde ich sagen. Nachfolgend kommt sie: 82.82.117.235 19:05, 20. Nov 2003 (CET)
-
-
Rechtschreibung und Sprachgebrauch sind oft eine sehr subjektive Sache und etwas dass man nur sehr schwer (oder gar nicht durch Vorschriften fassen und reglementieren kann. Die DIN 5008 ist - wie Du schon sagst - eine Norm für Sekretärinnen, für offiziellen Schriftgebrauch. Ich habe schon in vielen Büros gearbeitet und bis jetzt trotzdem nur eins kennengelernt, in dem man überhaupt wußte, daß es so etwas gibt. Das ist ähnlich wie mit der Rechtschreibung: jeder legt sich seine eigenen Regeln zurecht (machen ja die großen Verlage auch, die einen nutzen die alte Rechtschreibung, die anderen die neue, manche haben Eigene...). Es kommt gar nicht darauf an, ob man sich jetzt bewußt an irgendwelche Vorschriften hält, oder es bewußt nicht macht. Wichtig ist IMHO, daß wir, die Wikipedia (sag ich jetzt mal so) uns halt auf etwas allgemeinverbindliches einigen.
Meine Meinung zu DIN 5008, schmalem Leer, der Nichtdarstellbarkeit desselben und der Alternativen dazu (entweder ganzes Leer oder keines) habe ich ja im Zusammenhang mit den Abkürzungen (s.a. z.T. etc.) ja schon gesagt (auch wenn in Webtypographie vielleicht eine anderen Meinung geäußert wird). Am Ende ist es schlicht eine Frage der Praktikabilität (Trennung mitten in der Zahl/Wort bei Leerzeichen, keine Suchmöglichkeit bei Verwendung von ) und des Geschmacks (Hochkomma, Komma, Punkt, Leer). Langer Rede kurzer Sinn: dann stimmen wir halt ab, aber dann halten wir uns auch bitte an das Ergebnis. -- Sansculotte 19:44, 20. Nov 2003 (CET)
[Bearbeiten] Abstimmung Tausendertrennzeichen
Sollen in Wikipedia die aus der DIN 5008 und dem Duden üblichen Leerstellen (welche auch immer man da nun nimmt (s. Diskussion) ließe sich ggf. später nochmal abstimmen) oder die von Uli vorgeschlagenen Punkte, die man vor einigen Jahren noch benutzt hat, verwendet werden? (mit drei Tilden abstimmen)
- Variante "Leerstelle (2 500 000,00)": 82.82.117.235, Guillermo, fristu, Hafenbar, Wotan, Julian Mehnle, Lutz
- Variante "Punkt (2.500.000,00)": Sansculotte, tsor, Grrrubber, Sdg, Dishayloo, Hella, Ralf, DaB., Ichs Meinung
- Wieso muss denn über alles abgestimmt werden? Das Ergebnis ist sowieso nicht verbindlich. --zeno
-
- Weil wir sonst diese lästige Diskussion noch tausendmal führen müssen und ständig gegenseitig unsere Abkürzungen oder Zahlen editieren. Und wenn mir noch ein paar mal diese DIN vor die Nase gehalten wird, dann fahre ich wahrscheinlich auch wie Uli aus der Haut. Sansculotte 19:55, 20. Nov 2003 (CET)
-
-
- Abstimmen sieht doch so schön nach Demokratie aus. Zustimmung zu: Sprach-DINs sind i.d.R. zum aus der Haut fahren. --Sdg 19:59, 20. Nov 2003 (CET)
-
-
-
-
- Ich sehe es ähnlich. Sobald abgestimmt ist, ist die Sache vom Tisch und die zeitraubende Diskussion beendet. Schön, dass schon so viele mitmachen. 82.82.117.235 19:57, 20. Nov 2003 (CET)
-
-
-
-
-
-
- au fein :-) wenn schon die DIN nicht mehr gilt, ist ja die neue Rechtschreibung erst recht nicht mehr aktuell Marcela 20:07, 20. Nov 2003 (CET)
-
-
-
-
- Ich habe für DIN gestimmt denn: Warum um Himmels Willen sollen wir gegen Duden und DIN handeln? Das soll jetzt aber keine neue Diskussion anzetteln, ist nur meine Meinung -- tsor 20:16, 20. Nov 2003 (CET)
-
-
- DIN 5008 bezieht sich auf den Büro- und Verwaltungsbereich - wir wollen keine Amtsschreiben verfassen und unser Ergebnis soll auch nicht möglichst gut per OCR zu erfassen sein. Die automatische Sortierung durch EDV-Anlagen wird hier anders umgesetzt. -1000-02-01 ist bis 2001 nach der Norm die einzige richtige Schreibweise für ein Datum gewesen (so wie ich es verstanden habe). Wenn sich das verbreitet, können wir es einführen - bis dahin möchte ich, dass die Artikel gelesen werden können ohne zu stolpern. --Lutz 12:09, 21. Mär. 2008 (CET)
-
Die Sperrung ist keine Unverschämtheit, sondern hier wird permanent versucht, Verfahren zu ändern, die seit zwei Jahren gut funktionieren. Im übrigen von einem anonymen User, der hier mehrfach darauf aufmerksam gemacht worden ist, warum bestimmte Formatierungen hier auf Einfachheit und nicht auf typografische Korrektheit ausgelegt sind. Wenn dann ohne Diskussion allgemein im Konsens gefundene und bewährte Regeln einfach abgeändert werden, so ist das Vandalismus, und den lassen wir hier nicht zu.
Nochmal zur Begründung, warum wir die Regel so haben wie sie ist und warum sie - allen ad-hoc-Abstimmungen zum Trotz - so bleiben muss, wie sie ist: Die Wikipedia lebt davon, dass die Artikel auch von Anfängern bearbeitet werden können, die von HTML noch nie was gehört haben. Und ein 12.031.000 im Quelltext können die sowohl lesen wie bearbeiten, ein 12 & nbsp ; 031 & nbsp ; 000 dagegen nicht und ein 12 031 000 (mit richtigen Leerzeichen verbietet sich wegen des Zeilenumbruchs. Also bleibts bei den Punkten, Punktum. Uli 20:43, 20. Nov 2003 (CET)
- Einspruch. Das Argument ist nachvollziebar, aber nicht schlüssig. Wenn Wikipedia bei der Darstellung von Zahlen bei Leerzeichen grundsätzlich nicht trennte wäre das Problem mit den nbsps aus dem Weg. Eine zusätzliche Umgebung, die das Trennen explizit erlaubt, kann eingeführt werden für Sonderfälle, um die sich sowieso eher erfahrene Wikipedianer kümmern würden. Ich bin der Meinung, dass (auch um Streit zu vermeiden), eine Anlehnung an gewisse allgemeingültige Vorschriften (DIN, Duden) sinnvoll ist. --Cerno 15:18, 8. Sep. 2007 (CEST)
- es gibt genausowenig oder -viele Leute die die neue Rechtschreibung nicht beherrschen... Ich muß nach DIN und SI schreiben, das schreibt mein Beruf vor. Und so hab ich es vor 30 Jahren in der Schule gelernt Marcela 20:48, 20. Nov 2003 (CET)
-
- Ach, da hat man das heutige Datum als 2008-03-21 geschrieben? --Lutz 12:09, 21. Mär. 2008 (CET)
- Ulis Argumente - Einfachheit, Zeilenumbruch - überzeugen mich. Ich habe daher mein Votum geändert, bin nun also auch für die Schreibweise "12.031.000" (mit Punkten). Da sieht man es wieder: Wenn man mir alles schön erklärt, dann verstehe ich es manchmal sogar... ;-) -- tsor 20:59, 20. Nov 2003 (CET)
-
-
- Dass Anfänger vielleicht Probleme mit mit haben, sehe ich ja noch ein. Aber auch Anfänger können 1 000 000 mit normalen Leerzeichen schreiben, so wie sie es sonst ja auch tun, wenn sie sich an die Norm des DIN oder den Duden, der das Gleiche sagt, halten. Meine Meinung über die Sperrung habe ich inzwischen abgemildert. Eine Unverschämtheit war es nicht, ich hätte die Seite nicht ändern brauchen, eine Diskussion hier hätte genügt. Ich möchte nochmal an das Argument der Eindeutigkeit erinnern. Ist 1.234 nun eine versehentlich englische geschriebene Zahl (1 Komma 234) oder Eintausendzweihundert34? Leerzeichen sind da eindeutig. Ich hoffe im Übrigen, dass ein demokratisches Abstimmungsergebnis geachtet wird, und nicht nur, wie beim Datum, dann, wenn man nicht unterliegt. Sonst bräuchte man gar nicht mehr abstimmen. Wenn Tsor sich von Ulis Argumentation überzeugen lässt, dann ist das sein gutes Recht. Das heißt aber noch nicht, dass die anderen Abstimmenden nicht zählen oder? Ich hoffe es beteiligen sich noch welche an der Abstimmung, so dass sich ein eindeutiges Ergebnis abzeichnet. 82.82.117.235 22:09, 20. Nov 2003 (CET)
-
-
-
-
- ??? hat 82.82.117.235 auch einen Namen ??? Marcela 22:12, 20. Nov 2003 (CET)
-
-
-
-
-
-
- Hat er: Jan 82.82.117.235 22:28, 20. Nov 2003 (CET)
-
-
-
-
-
-
- Extreme Anfänger schreiben nicht und später können sie . --Lutz 12:09, 21. Mär. 2008 (CET)
-
-
Die Abstimmung hier mit fünf sechs Leutchen scheint mir zwar nur begrenzt sinnvoll, habe aber trotzdem mal mitgemacht. Ansonsten bin ich gegen Pedanterie. Ich habe festgestellt, dass es hier Leute gibt, die in irgendwelchen Artikeln Webseite oder Homepage ändern in Webpräsenz o.ä. weil sie meinen, Homepage sei nur die Startseite usw. und das alles entspreche nicht der Fachterminologie. Schon richtig. Und eine Lampe ist (fachsprachlich) eine Leuchte. Aber man sollte auch überlegen, was wann angebracht ist. Eigentlich wär's mir egal, ob Leerzeichen oder Punkt - aber wenn Zahlen durch Leerzeichen auf mehrere Zeilen umgebrochen werden, dann finde ich das ein verdammt starkes Argument. Grrruß Grrrubber
So, jetzt noch meine Meinung:
Punkte als Tausendertrennzeichen haben in online Texten, bei Zahlen, die möglicherweise per "cut and paste" weiterverarbeitet werden nichts aber auch gar nichts verloren ! Übertragen in einen anderen Text, eine andere Applikation wird daraus ganz schnell mal ein Bruch ... Hafenbar
- Und was wird aus dem Leerzeichen hier in der Wikipedia? Ein Zeilenumbruch? Punkte als Tausendertrennzeichen mögen nicht optimal sein, aber Leerzeichen sind definitiv Mist. Was ist mit der (wars Schweizerische) Variante: Hochkomma (1'234'567,890) -- Dishayloo [ +] 18:43, 4. Jul 2004 (CEST)
- Hochkomma finde ich selbst als Schweizer ungeeignet in der Wikipedia. Zu ungewohnt. -- lbreuss August 2006
Kein Tausendertrennzeichen verwenden, wäre mein radikaler und pragmatischer Vorschlag. Klar suboptimal, aber alles andere hat auch seine Nachteile und stört Leute, die für die anderen sieben Varianten sind. Bevor wir uns den Mund fusslig diskutieren: Wie gross ist das Problem überhaupt, wieviele Zahlen in Wikipedia betrifft denn das? -- lbreuss August 2006
[Bearbeiten] Technische Unmachbarkeit
Es ist schlicht und einfach technisch nicht befriedigend möglich, auf der Wikipedia Leerzeichen als Tausendertrennzeichen zu verwenden, völlig unabhängig davon, ob diese DIN-Norm eigentlich übernommen werden sollte und ob Leerzeichen eigentlich besser aussähen.
- Möglichkeit 1: einfache Leerzeichen verwenden. Dies führt aber zu unerwünschten Zeilenumbrüchen. Dies hat der anonyme Benutzer anscheinend nicht verstanden, wie seine Antwort an Uli vom 20.11.2003, 22:12 zeigt.
- Möglichkeit 2: verwenden - zwar keine Zeilenumbrüche mehr, allerdings wird der Wiki-Quellcode stark entstellt, was absolut inakzeptabel ist.
- Möglichkeit 3:   verwenden - ebenso unleserlich im Quellcode, außerdem wie bereits gesagt inkompatibel mit sehr verbreiteten Browsern.
- Möglichkeit 4: non-breaking space per Alt 0160 eingeben (unter Windows) oder aus der Zeichentabelle kopieren, statt es als HTML-Entity zu schreiben - Beeinträchtigt zwar nicht die Übersichtlichkeit des Wiki-Quellcodes, ist jedoch für den nicht-eingeweihten Benutzer nicht transparent, d.h. es ist nicht erkennbar, dass es sich nicht um ein normales Leerzeichen handelt. Ergebnis: neue Benutzer überschreiben die non-breaking spaces mit normalen Leerzeichen, wenn sie eine Zahl ändern.
- Möglichkeit 5: Die Wikipedia-Software erweitern, so dass Zahlen automatisch formatiert werden, entsprechend einer Einstellung, die für die Wikipedia jeder Sprache gesetzt wird. Dies erfordert, dass Zahlen im Quelltext über alle Wikipedias hinweg einheitlich geschrieben werden. Beispiel: man müsste in der deutschen Wikipedia 1234567.89 schreiben, damit die Software 1 234 567,89 anzeigt. Außerdem gibt es "Kollateralschäden" in Form von Ziffernfolgen, die keine Zahl darstellen, z. B. Binärfolgen.
- Möglichkeit 6: Zahlen durch neues, spezielles Wiki-Tag markieren und von Wikipedia-Software automatisch umformatieren lassen. Macht den Quellcode der Seiten nicht gerade einfacher und ist ein Schritt in die Richtung, dass die Wiki-Syntax sich einem Zustand annähert, in dem um jedes Wort ein XML-ähnliches Tag gesetzt werden muss, das die Art des Worts beschreibt. Dazu kommt, dass du die Benutzer der nicht-deutschen Wikipedias überzeugen müsstest und die Wikipedia-Software selbst ändern müsstest, da du mit hundertprozentiger Garantie niemanden finden wirst, der das für dich macht.
Ich hoffe, dass das Thema damit erledigt ist. Ich habe nicht abgestimmt, weil die Abstimmung aufgrund der technischen Unmachbarkeit hinfällig ist. Vom nicht Achten eines "demokratischen Abstimmungsergebnisses" würde ich hier nicht sprechen. Wenn du willst, darfst du aber gerne eine Abstimmung darüber eröffnen, ob jedem Mann das Recht gewährt werden sollte, Kinder zu kriegen. --Head 00:27, 21. Nov 2003 (CET)
- Möglichkeit 7: Zahlen mit Leerzeichen von der Wikisoftware grundsätzlich nicht umbrechen lassen. Zusätzlich eine Umgebung einführen, die trennen explizit erlaubt. Dieses Wiki-Feature dürfte auch für die anderssprachigen Wikipedias brauchbar sein, oder nicht? --Cerno 15:24, 8. Sep. 2007 (CEST)
- Danke Head, für die ausführliche Darlegung der Alternativen! Hast mich überzeugt. Dann halt Punkte (Als Schweizer wäre ich eigentlich für 1'234'000 und gegen das Recht, das jedem Mann gewährt wird Kinder zu kriegen). --Sdg 08:43, 21. Nov 2003 (CET)
- Ich wäre sehr für Variante 6, z.B. $4562413,5146 km$. Zwischen den beiden Dollarzeichen, die auch anderswo für Variablen stehen allerdings zu Problemen bei Währungsangaben führen könnten, würde sowohl Punkt als auch Komma durch den lokal üblichen Dezimaltrenner ersetzt und die Zahlen gruppiert. Statt U+00A0 (NBSP) ließe sich in der Ausgabe auch CSS ("white-space: nowrap") oder Tagsoup-HTML ("nobr") verwenden.
- Ich glaube außerdem kaum, dass es nur in der deutschen Wikipedia dieses Problem gibt; überall wo es um I18n geht taucht es auf. Von daher zieht das Argument, dass es niemand implementieren wollen würde, nicht, schließlich lässt sich zumindest in der englischsprachigen Wikipedia inzwischen auch ein Datumsformat aussuchen. Crissov 07:45, 3. Mär 2004 (CET)
Ich finde den letzten Vorschlag schon sehr gut. Ich wäre ohnehin dafür, dass sich die Wikisyntax nicht noch weiter von XML entfernen sollte, sondern vielmehr wieder annähert. Warum beispielsweise diese komplizierte Tabellensyntax statt tabel-Elementen, die zumindest die HTML-Profis ja schon beherrschen. Stern 11:58, 9. Jul 2004 (CEST)
- Möglichkeit 8: ADA-Notation für Zahlen: 3,141_926_535, 16_777_216, 613_566_756,571_428 (Der vorstehende, nicht signierte Beitrag stammt von 213.68.175.4 (Diskussion • Beiträge) 13:11, 26. Jun 2008 (CEST))
[Bearbeiten] Nochmals zur Tausendertrennung
Wenn (siehe obige Diskussion) in der Wikipedia als "technisch bedingte Notlösung" der Punkt Zur Gliederung von längeren Ziffernfolgen in Dreierblöcke verwendet werden soll, sollte das im Artikel auch entsprechend dargestellt werden, denn: Die Schreibweise von Zahlen sollte in der deutschen Wikipedia dem hierzulande üblichen Format folgen, also Kommas zur Dezimaltrennung und Punkte zur Tausendertrennung.(Zitat aus Artikel) ist definitiv falsch !
Wer sich mal über "das hierzulande übliche Format" informieren möchte, sei auf "meinen" Artikel Schreibweise von Zahlen verwiesen ... Hafenbar 21:05, 10. Mai 2004 (CEST)
Hallo Hafenbar, die Diskussion um das 'hierzulande üblich' ließe sich ewig führen, nur weil in der DIN 1333 Leerzeichen zur Tausendertrennung vorgeschlagen werden, heißt das noch nicht, dass auch die Mehrheit der Deutschen, Österreicher und Schweizer so schreibt... Dasselbe gilt übrigens auch für die DIN 5008 und die 'Neue Deutsche Rechtschreibung'. Wie auch immer, nach langer, kontroverser Diskussion neigte sich der Kompromiß zum Punkt als Tausendertrenner und ich halte es ehrlich gesagt für überflüssig und Verschgeudung von Zeit und Nerven, derartige Diskussionen alle Vierteljahre neu zu starten. Entschuldige, wenn ich das so deutlich sage. -- Sansculotte 21:13, 10. Mai 2004 (CEST)
- Dann sollte das aber auch so im Artikel stehen, dass für die deutschsprachige Wikipedia (und nur hier?) den Autoren eine Schreibweise nahegelegt wird, die bewußt bestehende Normen und den Duden ignoriert ... (nebenbei schlägt die DIN 1333 nicht nur Leerzeicher vor, sie verbietet ausdrücklich den Punkt: "Die Verwendung von Punkten zur Gliederung ist wegen der verschiedenen Verwendung von Komma und Punkt im europäischen bzw. amerikanischen Bereich als Gliederungszeichen nicht zulässig") ... Die Schweizer benutzen übrigens Hochkomma zur Tausendertrennung, soviel zu "hierzulande" ... Hafenbar 22:08, 10. Mai 2004 (CEST)
-
- Ob die DIN für Normalsterbliche maßgeblich ist, wage ich mal zu bezweifeln. Wie der Name sagt, ist es eine Industrienorm. Wir haben also die Wahl, uns daran zu halten oder nicht. Natürlich hat die Norm gute Gründe, den Punkt zu verbieten. Eingebürgert hat sich bei uns aber der Punkt, auch häufig in der Wikipedia zu finden. Ich würde unbedingt darauf achten, Missverständnisse zu vermeiden, aber sonst den Punkt zu verwenden. Leerzeichen, soweit sie nicht als geschrieben werden, verbieten sich von selbst, denn umbrochene Zahlen sind ganz unakzeptabel. Punkte möglichst erst ab sieben Ziffern (dann gibt's mindestens zwei Punkte) oder wenn klar ist, dass es kein Komma sein kann (z. B. die Stadt hat 5.223 Einwohner, aber niemals 5.223 Einwohner/Kilometer²!) --Hubi 14:20, 12. Mai 2004 (CEST)
-
- Ich seh gerade noch was. Ich hab in meinen Benutzereinstellungen Blocksatz eingestellt. Dann zieht der Browser selbst  , natürlich auch auseinander, was zu nahezu unleserlichen Zahlen führt (z. B. so: 12 000 000 - simuliert).
- Auch das spräche für den Punkt und die Beibehaltung der bisherigen Regelung trotz Duden/DIN-Argument. --Hubi 14:29, 12. Mai 2004 (CEST)
-
-
- 1) Eine DIN-Norm hat nichts mit Indusrienorm zu tun.
- 2) Selbstverständlich "muss" sich Niemand an Normen + den Duden halten, (auch nicht die Industrie).
- 3) Dafür, dass sich bei "uns"(was heißt das?) der Punkt als Trennzeichen "eingebürgert" hat warte ich immer noch auf irgendeine Form von Beleg. So habe ich den Eindruck, das hier nur einzelne Personen ihre persönlichen Gewohnheiten als den Standard darstellen.
- 4) An "Beachten sollte man, dass eine Tausendertrennung erst ab sieben Ziffern sinnvoll ist" hält sich meiner Erfahrung nach keiner.
- 5) Mir geht es doch gar nicht darum, in der Wikipedia unbedingt Leerzeichen einzuführen (bitte meine obigen Postings nochmals genau lesen - Möglicherweise ist es sinnvoller, auf eine Tausendertrennung vollkommen zu verzichten), Sondern nur darum, die Punktnotation nicht als den im deutschen Sprachraum gültigen + korrekten Normalfall darzustellen ! ... Hafenbar 15:44, 15. Mai 2004 (CEST)
-
-
-
-
- Tipp des Tages (Projektportal 26. Mai 2004)
Bei langen Zahlen - ab 5 Ziffern vor dem Komma - werden in der Wikipedia ...
auf der verlinkten Seite Wikipedia:Schreibweise von Zahlen liest man dagegen:
Beachten sollte man, dass eine Tausendertrennung erst ab sieben Ziffern sinnvoll
Aber es geht noch weiter:
Tipp des Tages (Projektportal 26. Mai 2004)
... Die Verwendung von HTML-Entities (Thinspaces etc.) ist nicht erwünscht, um die Artikelquelltexte leicht lesbar zu halten.
auf der verlinkten Seite Wikipedia:Schreibweise von Zahlen wiederum:
... Zwischen Zahl und Einheit kann man, um unschöne Zeilenumbrüche zu vermeiden, ein setzen
DEN Tip hätte ich mir doch für den 1. April aufgehoben ;-) ... Hafenbar 18:32, 26. Mai 2004 (CEST)
- Tipp des Tages (Projektportal 26. Mai 2004)
-
-
-
-
-
-
- Der originale Tipp war anders, aber Uli musste es ja unbedingt wieder in seinem Sinne umm(odel|urkse)n. Die ursprüngliche Motivation war, dass jemand meinte, in Kalorien unbedingt 9300 kcal durch 9.300 kcal ersetzen zu müssen. Das finde ich wegen der Verwechslungsgefahr mit 9,300 kcal kontraproduktiv. Davon ist jetzt nichts mehr drin. Zu Ulis Kommentar beim ummodeln sag ich mal nichts. --Hubi 08:19, 27. Mai 2004 (CEST)
-
-
-
-
-
-
-
-
- Motivation war, dass jemand meinte, in Kalorien unbedingt 9300 kcal durch 9.300 kcal ersetzen zu müssen. Das finde ich wegen der Verwechslungsgefahr mit 9,300 kcal kontraproduktiv. .. deckt sich auch mit meinen Erfahrungen und sehe ich genauso.
Wenn denn eine Tausendertrennung nötig erscheint, soll eine Gliederung (durch Punkte - wenn das die technisch einzig machbare Methode ist) erst bei Zahlen mit mindestens 7 Ziffern (im ganzzahligen Teil) erfolgen ... so ungefähr könnte ich mir das vorstellen ... Hafenbar 16:56, 27. Mai 2004 (CEST)
- Motivation war, dass jemand meinte, in Kalorien unbedingt 9300 kcal durch 9.300 kcal ersetzen zu müssen. Das finde ich wegen der Verwechslungsgefahr mit 9,300 kcal kontraproduktiv. .. deckt sich auch mit meinen Erfahrungen und sehe ich genauso.
-
-
-
-
...warum bestimmte Formatierungen hier auf Einfachheit und nicht auf typografische Korrektheit ausgelegt sind. — Uli
- Was ich nicht verstehe, ist, wieso die Variante mit den Punkten einfacher sein soll als die mit den Spaces, und warum ungewollte Zeilenumbrüche der Space-Variante stärker gegen die typografische Korrektheit verstoßen sollen als die seit Jahrzehnten veraltete Punkt-Variante. Im Übrigen wäre die Idee von Ce, Unterstriche automatisch durch non-breaking Spaces zu ersetzen, auch international, d.h. für alle Wikipedias, sinnvoll, denn bei der Unterstrich-Schreibweise handelt es sich um eine in verschiedener Software und Programmiersprachen bereits gängige Konvention, z.B.:
$ perl -e 'print 1_234_567.89, "\n";' 1234567.89
- (DIN bedeutet übrigens keineswegs Deutsche Industrienorm, sondern steht einfach nur für Deutsches Institut für Normung, ähnlich wie das ISO in den Bezeichnungen der ISO-Normen für den Namen der International Standardization Organization steht.) — Julian Mehnle 05:07, 21. Aug 2004 (CEST)
[Bearbeiten] <number> Tag/Element?
Ich bin die ganze Zeit am Überlegen, ob man zumindest komplexere Zahlen nicht (optional) mit <number>-Tags umgeben (können) sollte, also nicht Zahlen wie 10, 20, 30, aber z.B.
<number>10.000.000</number> <number>3,2⋅10<sup>23</sup></number>
Die Software könnte <number> zunächst einfach ignorieren, aber später dann Punkt durch   (Dudengerecht) und sdot durch middot (je nach Browser) ersetzen, evtl. sogar mit Benutzereinstellungen (Schweizerdarstellung, dudengerechte Darstellung, As-Is, immer middot verwenden etc.). Neue Benutzer würden/könnten Zahlen einfach wie bisher eingeben, die Tags kann man ja evtl. später nachtragen. Oder ist das jetzt überkandidelt? --Hubi 11:31, 9. Jul 2004 (CEST)
Ach ja, evtl. könnte ich für −3,2·1023 statt
−3,2·10<sup>23</sup>
einfach
<number>-3,2*10^23</number>
schreiben, und die Software generiert −3,2·1023 :-) --Hubi 11:45, 9. Jul 2004 (CEST) oder noch einfacher:
<number>-3.2e23/number> (übliche Schreibweise in Programmiersprachen (außer nichtenglisches VBA), Anzeige entsprechend der Locale) (Der vorstehende, nicht signierte Beitrag stammt von 213.68.175.4 (Diskussion • Beiträge) 13:16, 26. Jun 2008 (CEST))
- Vielleicht eine gute Idee: aus <number>10000</number> würde dann je nach Einstellung automatisch 10.000 oder 10'000. Zumindest mal eine Überlegung wert. Möglicherweise ist es aber bei der Bearbeitung hinderlich für Neulinge. Was meint Ihr: hätte man das schnell raus? Gibt es schon ein W3C-Element zum Formatieren von Zahlen statt "number"?Stern 11:49, 9. Jul 2004 (CEST)
-
- Ein Neuling dürfte ja auch erstmal nur 10000 schreiben. --Hubi 11:58, 9. Jul 2004 (CEST)
-
-
- nicht die verkehrteste Idee - je weiter die Wikipedia ist, desto eher können wir auch kompliziertere Sachen einführen - aber ich würde das nicht ernsthaft (d. h. als "muss"-Variante) verfolgen bevor wir nicht zwei- oder dreihunderttausend Artikel haben, oder? In technischen Artikeln ist die Quelltextsyntax eh kompliziert, da stört es nicht wirklich ... - ich finde, diesen Vorschlag an die Entwickler zu geben, wäre ganz gut! Aber erst, wenn wir ihn ausgearbeitet haben -- Schusch 12:52, 9. Jul 2004 (CEST)
-
-
-
-
- Ich würde hier lieber eine kürzere Schreibweise sehen, immer <number>...</number> einzutippen ist ja doch ein ziemlicher Aufwand für ein doch recht häufig genutztes Feature (das geht gegen das Wiki-Prinzip!). Die bereits vorgeschlagenen Dollarzeichen fände ich nicht schlecht. Außerdem ließe sich so auch eine etwas größere Freiheit in der Zahlschreibweise im Source erreichen, z.B. könnte man dann im Source gleichwertig $1.234 567*10^3$, $1,234 567·10<sup>3</sup>$ oder $1.234567e3$ schreiben, und heraus kämme z.B. immer 1,234 567·103 (1,234 567·10<sup>3</sup>) (oder auch sdot statt middot bzw. nbsp statt thsp). --Ce 13:58, 9. Jul 2004 (CEST)
-
-
-
-
-
-
- Ich denke wir sollten solche Vorschläge zusammen mit den Entwicklern ausarbeiten. Ich erinnere mich, dass kürzlich in der deutschsprachigen Wikipedia-Mailingliste der meiner Ansicht nach sehr vernünftige Vorschlag, den Unterstrich "_" als geschützen Blank auszugeben, von einem Entwickler umgehend vom Tisch gefegt wurde, ohne dass ich seine Argumente hätte nachvollziehen können. Was "10_000" oder "4_km" oder "z._B. " im Quelltext bedeutet, hätte jeder sofort verstanden. Die Konsequenzen von "<number>" oder "$" (Fehlinterpretationen?) überschaue ich jedenfalls nicht. Ferner schwebt ja auch noch die Option im Raum, alles auf Unicode umzustellen, wie es offenbar in der französischen WP schon geschehen ist. Angeblich wären damit manche Probleme (oder alle?), die wir hier diskutieren, gelöst. Knifflig, finde ich. --Wolfgangbeyer 01:47, 10. Jul 2004 (CEST)
-
-
-
-
-
-
-
-
- Hallo Wolfgang, das war eher so gemeint, daß ich von den Entwicklern erstmal keine wesentliche Initiative erwarte, d. h. als erstes sollten wir mit einem relativ konkreten Vorschlag an sie herantreten - wo tritt man denn eigentlich an sie heran? (Verbesserungsvorschläge?) -- Schusch 15:54, 15. Jul 2004 (CEST)
-
-
-
-
-
-
-
-
-
-
- Nur ein Dollarzeichen würde vielleicht manche bestehenden Artikel durcheinanderbringen, müsste man auf jeden Fall kontrollieren. Natürlich könnte man softwartechnisch über reguläre Ausdrücke sinnvolle Patterns erkennen (z. B. $10,2$) und nur diese als Zahl formatieren. Folgen wie 20 $ ließe man unverändert Verdoppelung des Dollarzeichens ($$10,2$$) würde die möglichen false positives weiter verringern. <number> würde meines Erachtens wahrscheinlich gar keine false oder sehr wenige bestehende Artikel durcheinander bringen, die leicht zu finden wären. Daher hatte ich ursprünglich daran gedacht. <number> ist aber weit unpraktischer als $ oder $$.
-
-
-
-
-
-
-
-
-
-
-
- Sollte das Feature zur Verfügung stehen und in "de" aktiviert werden, sollten wir auf jeden Fall wissen, ob und welche Artikel betroffen sind und diese gegebenenfalls korrigieren können. Da hilft es, wenn man vor einer möglichen Implementierung schon wüsste, was auf einen zukommt.
-
-
-
-
-
-
-
-
-
-
-
- Neben dem Problem, bestehende Artikel möglichst nicht zu verhunzen muss das ganze natürlich implementiert und danach beim Speichern eines Artikels auch geparset werden, was zusätzliche Rechenzeit benötigen wird. Meinem Gefühl nach ist beides aus technischer Sicht nicht so das große Problem, aber natürlich kenne ich die Interna nicht genau genug.
-
-
-
-
-
-
-
-
-
-
-
- Vielleicht könnte jemand, der die Datenbank runtergeladen hat, mal nach $...ziffer...$, $$ und <number> suchen? Danach könnte man dann jedenfalls für die de-Wikipedia entscheiden, was nach unserer Meinung am Besten ist und vielleicht mit einem konkreten Vorschlag an die Entwickler rantreten. Ich weiss auch nicht, wie man das macht, aber es meines Wissens nach gibt doch eine Feature-Request, eine Mailingliste und Benutzer, die schon mal was mit Entwicklung zu tun gehabt haben (Gwicke, Eloquence?) --Hubi 10:02, 16. Jul 2004 (CEST)
-
-
-
-
-
-
-
-
-
-
-
-
- ja, ich weiß, die Diskussion dümpelt ... :-) aber trotzdem geht mir das immer wieder im Kopf rum - habt ihr schon mitbekommen, daß man in der englischen Wikipedia eine Auswahl treffen kann, welchen Datumsformat man gerne hätte? Also zwischen May, 12th 1968 oder 12th May 1968 ... nur mal so als Info -- Schusch 23:54, 27. Jul 2004 (CEST)
-
-
-
-
-
-
-
-
-
-
-
-
- Die MediaWiki Software hat, wie ich gesehen habe, eine Klasse DateFormatter, die über Defaultsettings aktiviert werden kann. Soweit ich gesehen habe, betrifft es Datumseingaben zwischen [[...]] bzw. auch zwei [[...]] [[...]], die nach einem Edit über reguläre Ausdrücke in ein internes Format gewandelt (z. B. [[1930]] [[November 30]] oder [[1930-11-30]] nach [[30 November]] [[1930]] (internes Format)). Beim Ausgeben kann dann das interne Format in eine benutzerspezifisches gewandelt werden. Etwas englischlastig, da z. B. BC (before christ) hart im Code steht, bei Verwendung von Unicode ist es ungetestet etc.
-
-
-
-
-
-
-
-
-
-
-
- Man müsste also an ähnlicher Stelle eine Klasse NumberFormatter einfügen, was wohl machbar wäre. Die Kommentare im Quellcode sprechen von 14maligem (!) Parsen des Texts. Da DateFormatter englischlastig ist und derzeit von der dt. Wikipedia nicht so verwendet werden kann, stände einem NumberFormatter nicht mehr so viel im Wege (zusätzliches Parsen wäre machbar). DateFormatter tut sich etwas leicht, da das Datum zwischen [[ ]] eingeschlossen sein muss, wo es leicht als solches erkannt werden kann, wir aber evtl. $ oder $$ verwenden wollen. Die Auswirkungen sind da noch unbekannt. --Hubi 10:32, 28. Jul 2004 (CEST)
-
-
-
-
-
[Bearbeiten] Warum Tausenderzeichen erst ab fünf Ziffern?
Hallo, auch auf die Gefahr hin, eine längst ausdiskutierte Debatte neu aufzumachen: warum soll der Punkt als Tausendertrennzeichen erst ab fünf Ziffern verwendet werden? Eine Verwendung bereits ab vier Ziffern ist erstens konsistenter (was sich z.B. in Tabellen zeigt, in denen vier- und fünfziffrige Zahlen auftauchen; wenn die Zahlen rechtsbündig gesetzt sind, sieht es seltsam aus, wenn nur die fünf- oder mehrziffrigen Zahlen mit Punkt gesetzt sind) und macht es zweitens möglich, auf den ersten Blick zu unterscheiden, ob es sich um einen natürlich nicht mit Tausenderpunkt zu trennende Jahreszahl oder um etwas anderes handelt.
Um beide Punkte zu illustrieren:
Einwohnerzahl 1850 900 Einwohnerzahl 1850 900 Einwohnerzahl 1900 6000 vs Einwohnerzahl 1900 6.000 Einwohnerzahl 1950 9999 Einwohnerzahl 1950 9.999 Einwohnerzahl 2000 12.500 Einwohnerzahl 2000 12.500
Ich würde mich freuen, wenn die derzeitig auf dieser Seite beschriebene Praxis entweder geändert oder gut begründet würde. -- TillWe 23:06, 19. Dez 2004 (CET)
- Keine Ahnung. Ich setzte immer einen Punkt schon nach 4 Zeichen. Sollte geändert werden. --DaB. 23:25, 19. Dez 2004 (CET)
- Deine schöne Illustration zeigt, dass es in der Wikipedia keine Regeln geben kann, höchtens Richtlinien. Selbstverständlich darf jeder einen Punkt setzen, wenn er dies für richtig hält. Andererseits sind Regeln notwendig, da es ohne sie zu sehr vielen Edit-Wars käme.
- Wieso eigentlich Punkte? Wären 0,9 · 10³ und 12,5 · 10³ nicht viel besser? :)
- Man sollte „Regeln“ in der Wikipedia nicht immer stur befolgen. Sei mutig!
- Wenn Fragen, wie warum sollte der Punkt als Tausendertrennzeichen erst ab fünf Ziffern verwendet werden auftauchen, muss die „Regel“ natürlich besser formuliert werden. Dafür ist’s für mich aber heute zu spät. --Blaite 23:40, 19. Dez 2004 (CET)
-
- Hier ist mE die Verwendung in Tabellen bzw. Listen streng von der Verwendung im Text zu unterscheiden. Bei Tabellen ist klar, dass die Formatierung Punkte immer erzwingt. Angaben in Texten sollten
- 1. leicht lesbar
- 2. flüssig lesbar
- 3. unmissverständlich
- sein. Vier Ziffern sind leicht zu identifizieren, fünf auch, sechs manchmal nicht mehr, sieben gar nicht. Ab sieben Ziffern erhält man die schöne Eigenschaft, dass zwei Trennzeichen vorhanden sind, die Verwechslungsgefahr mit dem Dezimaltrennzeichen verwendet. Im Engl. werden ja Kommas für Tausender verwendet, so dass man manchmal nicht ganz sicher ist. 1,000 und 1.000, ist eins oder 1000 gemeint? 1,000,000 ist die engl. Schreibweise für 1 Million. Wegen der Unmissverständlichkeit (3.) wäre ich für zwingende Tausendertrennzeichen erst ab sieben Ziffern, bei fünf wenn keine Zweideutigkeiten auftreten(1.) , bei vier gar nicht (2.). Bleibt nur noch, ob für fünf u. sechs Ziffern eher empfohlen wird oder eher nicht. Wegen 1. eher empfohlen. --Hubi 07:20, 21. Dez 2004 (CET)
Ich finde es auch inkonsistent, wenn nur im Text keine Punkte gesetzt werden. Zumindest der Ausnahmefall "Tabellen" sollte jedenfalls explizit genannt werden. Was mir bei der (sonst manchmal so ausgeprägten ;-)) Deutschtümelei in der Wikipedia nicht ganz klar ist, ist das Beharren auf der Verwechslungsgefahr mit angelsächsischen Kommas. Warum nicht einfach zwingende Punkte ab vier Ziffern? -- TillWe 16:56, 21. Dez 2004 (CET)
Und warum nicht den Zwang, erst ab fünf Ziffern Punkte zu verwenden? :) -- Daniel FR Hey! 17:02, 21. Dez 2004 (CET)
- Wenn in einem Text steht "Die Bevölkerung wuchs innerhalb weniger Jahrhunderte von 8000 auf 1.000.000", dann ist auch hier die Abweichung von der Regel störend. Als Gegner von unnötigen Ausnahmen insbesondere, wenn sie auch noch auf Grenzen postulieren, die völlig Geschmackssache sind, würde ich generell für den Punkt plädieren und lediglich Jahreszahlen als Ausnahme gelten lassen. --Wolfgangbeyer 21:13, 21. Dez 2004 (CET)
- Nehme mein Plädoyer für generellen Punkt wieder zurück. Hatte die Verwechselungsgefahr mit dem Komma insbesondere bei Angaben mit Einheiten wie z. B. 9.234 kcal übersehen. Tendiere doch eher zu Hubis Sicht. --Wolfgangbeyer 23:11, 21. Dez 2004 (CET)
- ohne im Duden nachzuschauen (duck :-): dort steht meines Wissens: normalerweise ab fünf Ziffern Tausenderpunkt, ab vier nur in Tabellen, wenn keine Verwechselungsgefahr ... (aber ich wäre gegen eine strenge Regelung - es gibt einfach zuviele Anhänger eines Tausenderpunktes schon bei vier Ziffern hier in der Wikipedia ...) -- Schusch 23:17, 21. Dez 2004 (CET)
Ich gebe mich geschlagen -- die DUDEN-Richtlinien für den Schriftsatz sehen wohl tatsächlich vor, dass erst ab fünf Ziffern Tausenderpunkte zu setzen sind (ich verstehe zwar immer noch nicht, warum, aber wenn's schon halbamtlich ist ...). Ich würde trotzdem vorschlagen, darauf hinzuweisen, dass Tabellen konsistent und mit Punkt auch bei kleineren Zahlen zu setzen sind. -- TillWe 00:11, 22. Dez 2004 (CET)
Sehr gut, Tillwe! Dieses Problem wäre z.B. unter Gemeinden_des_Kantons_St._Gallen ersichtlich. Generell Punkt/Hochkommata nach fünf Zeichen, nur wenn das Tabellenlayout es "verlangt", schon ab vier Zeichen. --Filzstift ○ 07:33, 22. Dez 2004 (CET)
- Das hat nichts mit Deutschtümelei zu tun. Ich will, dass in der WP möglichst alles unmissverständlich ist. Dass bei sieben Ziffern (1000000) Leseschwierigkeiten bestehen (ist das jetzt 10000000 oder 1000000), erzwingt eine Tausendergruppierung. Standards wie DIN/neuere Duden empfehlen teilweise (schmale) Leerzeichen, was die Gefahr eines hässlichen Zeilenumbruchs und auseinandergerissenem Aussehen bei normalem Space nach sich zieht.   verbietet sich wegen der möglichst einfachen Editiermöglichkeiten der WP. Punkt und Komma sind auch in manchen Zeichensätzen (PDA) nicht leicht zu unterscheiden, sollten also nur (!) bei Eindeutigkeit oder ganz geringer Verwechslungsgefahr (Tabellen) verwendet werden. Naturwissenschaftler wie ich sind aufgrund von intensiver Computerverwendung, Programmiersprachen wie Fortran/C sowie intensivem Konsum englischsprachiger Literatur gewöhnt, Punkt und Komma als synonym anzusehen, wenn nichts auf das Gegenteil hindeutet. Vier/Fünf Ziffern sind (wie bei vier/fünf) Streichhölzern) leicht zu erkennen (1000 oder 10000), die Gruppierung ist also unnötig. Fast wäre ich geneigt, die schweizer Lösung mit Apostroph zu empfehlen (1'000). Dort besteht absolut keine Verwechslungsgefahr, halte ich für sehr gut, aber leider ist's weder DIN noch Duden. Scheidet also wohl aus, obwohl's mE die beste Lösung wäre. Schließlich noch eine Häufigkeitsüberlegung. In der WP und anderswo treten Zahlen wie 1,234 (eine Stelle+3 Nachkommastellen) wohl relativ häufig auf, etwa Einheitenumrechnung etc. Das Komma auf dem Apple hier ist nur ein Mini-Strich, ich weiß also nicht, sind bei 1.234 jetzt 1234 (für Schweizer: 1'234) oder vielleicht 1,234 gemeint. Zahlen wie 12,345 (zweistellig und drei Nachkommastellen) sind schon viel seltener und 123,456 kommen fast niemals vor, da man so genaue Angaben (0,001%) wohl eher in wissenschaftlicher Schreibweise findet. Will man die Lesbarkeit erhöhen, braucht's den Punkt bei vier Ziffern keinesfalls, die Verwechslungsgefahr halte ich für immens. Eine Empfehlung für fünf/sechs reicht mE, da im Einzelfall entschieden werden kann, wobei das Augenmerk auf Unmissverständlichkeit gerichtet ist --Hubi 08:20, 22. Dez 2004 (CET)
-
- Als Schweizer habe ich mit den DIN/Duden-Regelungen schon meine grösste Mühe, ist 1.234 denn nun eins komma zwei drei vier (so wie es in der Schweiz interpretiert wird) oder tausendzweihundertvierunddreissig (DIN)? Und wer gewöhnt ist, englische Texte zu lesen, interpretiert zusätzlich 1,000 als Tausend. Da kann man endlos diskutieren. --Filzstift ○ 08:42, 22. Dez 2004 (CET)
-
- ah, eine Lücke :-) – Zuschlagen! Hatte ich schon gesagt, das ich Hochkommata auch prima finde? Dann hole ich das jetzt nach – wir folgen ja auch nicht in allem der DIN etc. Wollen wir das nicht zumindest als Empfehlung aufnehmen? -- Schusch 12:02, 22. Dez 2004 (CET)
Also ich finde 1.000 sollte nur verwendet werden um in Tabellen eine Untereinanderreihung gleicher Werte zu ermöglichen. (Für alle, die, wie ich, gerade Bahnhof verstanden haben:
50
1.000
500.000
1.000.000
↑.↑↑↑.↑↑↑
Millionen, Hunderttausender, Zehntausender, Tausender, Hunderter, Zehner, Einer geht nicht ganz so toll…)
Ansonsten sind 50000 genausotoll verständlich! – Ichs Meinung. ☏ 19:34, 2. Jan 2005 (CET)
- Die Trennung in Dreiblocken ab der vierten Ziffer ist (sei es durch Punkt, Leerzeichen oder helvetisches Hochkomma) ist so sehr allgemein verbreitet und zudem so sinnvoll, daß die Richtlinie "erst ab fünf Ziffern", die in der Wikipedia gelten soll, mir recht unsinnig und verwirrend vorkommt. Uka 11:15, 27. Sep 2006 (CEST)
[Bearbeiten] tausendertrennung 2005, die erste
gudn tach!
dieses jahr hat sich bisher noch keiner zu den trennzeichen geaeussert, aus den alten langen diskussionen geht allerdings noch kein ergebnis hervor. es werden bloss die zwei gespaltenen lager deutlich: auf der einen seite die leute, die sich an normen/standards halten wollen und auf der anderen seite diejenigen, welche sagen, dass die normen (technisch) nicht webtauglich seien.
ein guter kompromiss waere imho die von Julian Mehnle und Ce genannte unterstrich-variante.
bis sowas allerdings (vielleicht) mal realisiert wird, sollte man sich eine loesung ueberlegen, die mind. temporaer ok ist. aber halt! warum _ueberlegen_? das haben schon andere getan und herausgekommen sind din-, duden- und si-normen, die diesbzgl. dasselbe aussagen: grundsaetzlich leerzeichen.
wenn einige wikipedianer der meinung waeren, dass man irrationale zahlen in der wikipedia abschaffen sollte, weil sie nicht webtauglich seien, wuerde man dann π einfach auf 3 festsetzen (obwohl wir das schon seit ein paar tausend jahren eigentlich nicht mehr tun)? ich denke nicht. und aus einem aehnlichen grunde habe ich nun folgenden vorschlag:
im artikel sollte explizit die essenz von Schreibweise von Zahlen und Tausendertrennung stehen: grundsaetzlich leerzeichen (mit ausnahmen z.b. bei den schweizern)
(wenn nicht diese langen diskussionen existierten, wuerde ich's jetzt einfach welbst aendern.) --seth 20:43, 27. Jun 2005 (CEST)
- Also - nicht nur Wikipedia hält sich nicht an die "keine Leerzeichen"-Strategie, sondern auch durchaus seriöse Quellen wie tagesschau.de usw. Vom Prinzip her ist auch nicht Leerzeichen gleich Leerzeichen, sondern alle Normen die mir bekannt sind, sprechen von schmalen Leerzeichen ( ), nicht von "normalen". Schmale machen für die Lesbarkeit des Artikels und auch so sehr viel mehr Sinn als volle, da - mein Lieblingsbeispiel - 4 200 Watt-Birnen auch für 4 Stück 200 Watt Birnen stehen kann, 4 200 Watt-Birnen eher nicht. Nur kann halt derzeit noch nicht jedes OS/jeder Browser/jeder Zeichensatz kleine Leerzeichen, weshalb diese unpraktikabel sind. Das wäre normkonform, ansonsten ist das volle Leerzeichen eine sowohl zweideutige als auch im Klar- und Quelltext schlechter lesbare Annäherung an die Norm, der gegenüber die Punkttrennung was die Lesbarkeit betrifft vorzuziehen ist. Insofern ist die günstigste Variante für den Moment, alles zu lassen wie es ist. Wenn thinsp mal weiter verbreitet richtig interpretiert werden kann, kann man drüber diskutieren, ob man die Punkte durch thinsp (nicht nbsp) ersetzt.
- Übrigens - ich dachte eigentlich, dass das (kleine) Leerzeichen Standard bei Wikipedia sei und musste im Nachhinein Fehler korrigieren, insofern bin ich nicht aus Prinzip gegen Leerzeichen; nur sind Leerzeichen aus inzwischen vielfach dargelegten Gründen derzeit halt nicht praktikabel. Die Punktvariante ist (im Gegensatz zur Unterstrichvariante) weder komplett ungebräuchlich noch schlecht lesbar, also alles i.O. --afromme 15:56, 30. Aug 2005 (CEST)
-
- Nur als Hinweis: Die Birnen zu 200 Watt schreibt man 200-Watt-Birnen. (Das Missverständnis wird dadurch aber auch nicht aufgelöst.) -- Paul E. 16:42, 13. Nov 2005 (CET)
- bei den Schweizern sind Leerzeichen erlaubt, nur eben nicht Punkt als Trennzeichen. Wenn man aufs Leerzeichen einigen würde, dann wären alle Deutschen und Schweizer glücklich und eine (aus meiner Sicht) deutsche Eigenart würde wegfallen ;) --Filzstift ✑ 22:59, 27. Jun 2005 (CEST)
-
- Punkte wo Punkte gebühren, Hochkommas bei den Schweizern. Wozu eine neue Diskussion? Leerzeichen sind einfach untauglich, weil sie Zeilenumbrüche bewirken könnten. Was ist das für eine Unterstrich-Variante? 15_553? Hässlich! Eindeutig: Für die Regelung mit Punkten (und Hochkommas für die Schweizer) – Ichs Meinung. ☏ 2. Jul 2005 19:26 (CEST)
-
-
- gudn tach Jan, in den alten diskussionen waerst du fuendig geworden. 1. statt leerzeichen verhindern umbrueche. 2. _-variante bedeutet, dass beim editieren unterstriche (_) verwendet werden, die jedoch als (thin) non-braking spaces dargestellt werden.--seth 2. Jul 2005 22:04 (CEST)
-
-
-
-
- ist aber leider auch nicht normgemäß, sondern nur   - womit ich sehr gut leben könnte, was aber nix bringt, weil's ohne Kurzlinks asozial zu tippen ist (vom Quelltextlesen abgesehen) und (wichtiger) nicht bei jedem einwandfrei dargestellt werden kann --afromme 15:56, 30. Aug 2005 (CEST)
-
-
-
-
-
- Habe mir Erlaubt, das sichtbar zu machen.
- Ansonsten: Im Quelltext sieht das aber auch nicht schön aus, wenn zwischen Ziffern steht, und in WP gilt immer noch, dass der Quelltext so lesbar wie möglich sein sollte (War das nicht auch einer der Hauptgründe für die Umstellung auf Unicode? Man berichtige mich, liege ich falsch). Wenn das die Unterstrichvariante sein soll, dann nehme ich das hässlich zurück. (Ich weiß jetzt nicht, wie einfach die entsprechende Softwareänderung ist) Aber: Meines Wissens sind wir doch in diesen Diskussionen zu einem Ergebnis gekommen, nämlich die Punkte da zu lassen, wo sie sind, oder? Warum das Ganze neu aufrollen?? – Ichs Meinung. ☏ 22:01, 10. Jul 2005 (CEST)
-
-
-
-
-
-
- ...weil man's versuchen kann... Beliebte Taktik, ich trau mich aber nicht, Beispiele zu nennen ;-) --afromme 15:56, 30. Aug 2005 (CEST)
-
-
-
-
-
-
-
- Ich halte das Tippen von für zumutbar, zumal es im Printwesen ja auch üblich ist. Ansonsten wollte ich mal erinnern, dass eine Tausendertrennung erst ab fünf Stellen üblich ist - ich sehe hier viele Tausenderpunkte bei vierstelligen Zahlen. Die Punkteregelung ist für mich zweite Wahl, da es keine deutsche Standard-Orthografie ist und die Zahlen dadurch einen gewissen IT-Touch bekommen. Wikipedia sollte allerdings maximale Usernähe anstreben, also muss die Sprache die Priorität vor der Technik haben. -- Hunding 09:47, 11. Jul 2005 (CEST)
-
-
-
-
-
-
-
-
- Im 'Printwesen' sind Punkte z.T. ebenso üblich; plus: im Printwesen sind die normgerechten schmalen Leerzeichen darstellbar und durch automatische Formatierung auch einfügbar. Trifft beides hier nicht zu. --afromme 15:56, 30. Aug 2005 (CEST)
-
-
-
-
-
-
-
-
-
- Zumutbar isses, aber nicht unbedingt sofort durchschaubar. »üblich« ist ein schlechtes Wort in dem Zusammenhang: Du siehst ja, dass 1.500 auch irgendwo »üblich« ist ;-). Ansonsten: Ändere doch die Zahlen mit Punkt in vier aufeinanderfolgende Ziffern. Wer hindert dich daran? Ich tu’s auch gerne, wenn mir so was über den Weg läuft – Ichs Meinung. ☏ 17:53, 11. Jul 2005 (CEST)
-
-
-
-
-
-
-
-
-
-
- im artikel wird gesagt, dass die schreibweise in der wikipedia dem "ueblichen" zahlenformat angepasst sei. ebenfalls gleich zu beginn wird zu Schreibweise von Zahlen verlinkt, wo steht, was (nach din und duden) richtig und was falsch sei. in der wikipedia selbst sehe ich immer haeufiger, dass das din-normierte zahlenformat genutzt wird. (ich selbst benutze es ebenfalls.) in diesem artikel wird nirgendwo gesagt, dass die deutschsprache wikipedia sich ueber diese normen hinwegsetzen will, was einen in den irrtuemlichen glauben versetzen koennte, dass der punkt als tausendertrennzeichen auch ausserhalb der wikipedia das richtige zu verwendende zeichen waere. und der link "siehe auch: schreibweise deutschland..." fuehrt die punkt-setzung noch mehr ad absurdum.
- aus diesen gruenden, werde ich jetzt den artikel an die din-norm anpassen.--seth 23:39, 16. Aug 2005 (CEST)
-
-
-
-
-
-
-
-
-
-
-
-
- ...bitte auf die DIN-Norm-gemäßen schmalen Leerzeichen achten! Leerzeichen allein machen noch keinen Sommer! (Sorry, wenn ich so drauf rumreite, aber kleine Leerzeichen sind super und vereinfachen die Lesbarkeit, normale Leerzeichen machen Zahlen z.T. zweideutig und verschlechtern die Lesbarkeit, weil in einer Zahl damit mehrfach Abstände vorkommen können, wie man sie eigentlich zwischen zwei getrennten Worten u.ä. findet.) --afromme 15:56, 30. Aug 2005 (CEST)
-
-
-
-
-
-
ich aenderte den artikel ab; DaB. revidierte die aenderungen (ohne auf diese diskussion und meine argumente einzugehen); benutzer:Hadhuey revidierte dann die aenderungen von benutzer:DaB. mit dem hinweis, dass auf die wikipedia-ausnahmen explizit hingewiesen werden sollte. DaB. revidierte erneut und wieder ohne auf diese diskussion bzw. die argumente einzugehen. ich werde deswegen nun versuchen die von benutzer:Hadhuey vorgeschlagenen aenderungen durchzufuehren. --seth 23:02, 19. Aug 2005 (CEST)
- Wer keine History lesen kann, ist selber schuld. Ich habe jedesmal begründet, warum ich revertet habe. Es wurde monatelang über einen Kompromiss gestritten, da kann soetwas nicht einfach mal geändert werden (siehe auch http://www.ru-info.de/wikiremote.jpg ;-)). Auch im Chat war man sehr ungehalten (um es milde zu formulieren). Übrigends war Hadhuey anwesend.
- Allerdings kann zumindest ich mit der letzen Version sehr gut leben :-). --DaB. 00:12, 20. Aug 2005 (CEST)
-
- gudn tach! ich antworte abschnittsweise... die history hatte ich gelesen, aber da wurde nicht mal rudimentaer was zu meinem (zu der zeit) letzten kommentar hier in der diskussion gesagt. vor allem zu dem punkt, dass der artikel missverstaendlich geschrieben war.
- ueber einen kompromiss wurde gestritten, aber eine einigung gab es nicht. zwischen zahlen und einheiten sowie zwischen zahlen und dem multiplikationspunkt (exp.-schreibweise) sollen nbsp.s gesetzt werden, aber als tausendertrennzeichen sind sie ploetzlich zu unleserlich im quellcode? sogar soo unleserlich, dass man es fuer notwendig erachtet, sich ueber inter- und nationale normen hinwegzusetzen?
- wer sich nicht halten kann, der sollte es lernen. ;-)
- die aktuelle version gefaellt mir besser als die alte, aber immer noch nicht gut. aber soo wichtig, dass ich da jetzt viel kampfenergie reinhaenge, ist es mir auch wieder nicht. es gibt wichtigeres. die tatsache, dass ich mittlerweile in schon sehr vielen artikeln die norm-konforme schreibung gesehen habe, laesst mich zu dem schluss kommen, dass es vielen schreibern ohnehin nicht bewusst oder egal ist, was in _diesem_ artikel steht. jedenfalls werde ich deswegen selbst auch weiterhin die din-konforme schreibung verwenden und damit nicht das gefuehl haben, gegen eine wikipedia-interne konvention verstossen zu haben, da von der existenz einer solchen keine rede sein kann.--seth 02:07, 20. Aug 2005 (CEST)
-
-
- zwischen zahlen und einheiten sowie zwischen zahlen und dem multiplikationspunkt (exp.-schreibweise) sollen nbsp.s gesetzt werden, aber als tausendertrennzeichen sind sie ploetzlich zu unleserlich im quellcode? Ja. Zahl und Maßeinheit gehören nicht so "dicht" aneinander wie die Stellen eben dieser Zahl, sondern sind - schon durch's Format Ziffern vs. Buchstabe - eh "getrennt zusammen". 12 400 t-Gewichte liest sich dagegen anders als 12.400 t-Gewichte. Übrigens sagen - wenn wir schon drauf rumreiten wollen - alle Normen, dass sowohl als Tausendertrennzeichen wie auch als Trennzeichen zwischen Zahl und Maßneinheit ein "schmales Leerzeichen" eingesetzt werden sollte, was wegen mir voll okay wäre, weil es im Gegensatz zum vollen Leerzeichen nicht die Zahl auseinanderreißt und mehrdeutig macht. Warum schmale Leerzeichen, die ich persönlich sofort befürworten würde - mit dem Bonus, dass sie 100% normkonform sind - zumindest im Moment nicht praktikabel sind, wurde ja schon ausführlich dargelegt. Und so lang das so ist, sind Punkt wie auch nbsp; faule Kompromisse, von denen 12.400 gegenüber 12 400 der eindeutig lesbarere (im Klar- wie im Quelltext) und im deutschen Sprachraum unzweideutigere ist. Wiederhole ich mich?--afromme 15:56, 30. Aug 2005 (CEST)
-
[Bearbeiten] Tausender zum x-ten
In Wikipedia:Schreibweise von Zahlen wird behauptet, die Tausendertrennung wäre erst ab fünf Ziffern sinnvoll, in anderen Texte lese ich "ab 7 Ziffern". Das erscheint mir als typographische Konvention wenig sinnvoll, da es in Tabellen arg blöd aussähe, "Tausend" ohne Trenner, "Eine Million" aber mit Trennern unterienander zu schreiben. (Auch die Verwendung von Dezimaltabulatoren wäre damit ja eines Teils ihrer Sinnhaftigkeit beraubt.) Habe ich da etwas übersehen oder sollten wir uns auf eine Einheitliche Schreibung für alle Zahlen größer als 999 einigen? -- RainerBi ✉ 07:53, 15. Feb 2006 (CET)
- Hier geht es um Fließtext. In Tabellen sollte natürlich Konsistenz Vorrang haben. Sollte man evtl. ergänzen. -- H005 09:13, 15. Feb 2006 (CET)
-
- steht doch schon drin:
- "Beachten sollte man, dass – abgesehen von selbstverständlich einheitlich zu haltenden Tabellen und Auflistungen – eine Tausendertrennung erst ab fünf Ziffern sinnvoll ist" -- seth 20:42, 15. Feb 2006 (CET)
Ja, ich habe die vorhergehende Diskussion überflogen, aber mir erscheinen die Argumente nicht sehr logisch. Und die Diskussion auch noch nicht beendet. Gerade Jahreszahlen werden leicht mit anderen Zahlen verwechselt. Bei 1900ern denkt man ja noch automatisch an die Jahreszahl, aber bei 2000ern fehlt noch die Gewöhnung. Schlecht finde ich auch, dass Fließtext und Tabellen uneinheitlich sind. Warum soll eine Zahl mit Punkt in der Tabelle lesbar sein und nicht auch im Fließtext ? MfG, --J. Patrick Fischer 13:19, 10. Mär 2006 (CET)
- Vierstellige Zahlen halte ich grundsätzlich ohne Punkt für besser lesbar. In normalem Text sind die Zahlenwerte nur selten so nah beeinander, dass die Inkonsistenz der Punktuierung stören würde - anders als in Tabellen. Es gibt natürlich Ausnahmen: Wenn ich z. B. schreibe: "An der TU Hintertupfingen sind 12.345 männliche und 5678 weibliche Studierende immatrikuliert.", dann würde ich auch hier der Konsistenz Vorrang geben und "5.678" schreiben. Umgekehrt würde ich in einer Tabelle, die nur maximal vierstellige Zahlen enthält, nirgends Tausenderpunkte setzen. Wie immer gilt: Keine Regel ohne Ausnahme. Sachverstand und Stilgefühl sollten Vorrang haben vor in Stein gemeißelten Gesetzen. -- H005 13:34, 10. Mär 2006 (CET)
- Sowohl Patrick als auch H005 haben recht.Es kommt hier sehr auf den Zusammenhang und auch auf persönliche Vorlieben an. Am meisten stört mich dabei eigentlich, wenn irgendwer in "meinen" Artikeln sämtliche Zahlen umformatiert (die ich oft differenziert mit Blick auf den Kontext formatiere), mit dem Hinweis auf die in WP:SVZ festgelegten "Regeln". Ich bin der Meinung, dass dies einer der Fälle ist, wo wir ohne Regeln glücklicher wären. Wenn es aber eine Regel geben muss, dann ist es besser, wenn sie einheitlich ist und Punkte ab vier Ziffern vorsieht. --ThePeter 13:50, 10. Mär 2006 (CET)
Ein Beispiel für einen Artikel in dem beide Versionen existieren, ist der Artikel über Åland. Die Verwendung des Punktes bei den Aufzählungen ist logisch nach der Regel und sinnvoll. Das fehlen des Punktes im restlichen Artikel folgt der Regel, aber ich empfinde das als uneinheitlich. --J. Patrick Fischer 15:56, 10. Mär 2006 (CET)
Ich habe die Regeln einmal etwas deutlicher als das formuliert, was sie sind: Regeln, keine Gesetze. Ich vermute, dass alle damit einverstanden sind. Sonst: Revert und Ausdiskutieren. -- H005 16:51, 10. Mär 2006 (CET)
- Die Formulierung ist gut, allein... Das Problem mit verschiedenen Schreibweisen innerhalb eines Textes löst sie nicht. ;-) --J. Patrick Fischer 22:18, 11. Mär 2006 (CET)
- Mir gefiel dir vorige, schärfere Formulierung „Tausenderpunkt erst ab fünf Ziffern“ weitaus besser. An Zahlen wie „1.234“ kann ich mich nur schwer gewöhnen. Die sehen einfach hässlich aus. Für Tabellen sollte auch nur dann eine andere Regelung gelten, wenn die Zahlen rechtsbündig ausgerichtet sind (könnte man vielleicht noch als Kriterium erkennen). Die Formulierung mit dem Textzusammenhang ist mir zu schwammig. --jpp ?! 21:21, 14. Mär 2006 (CET) PS: Und, ja, ich würde schreiben „an der TU Hintertupfingen sind 12.345 männliche und 5678 weibliche Studierende immatrikuliert“ und finde das weitaus eleganter.
- Nach einer Diskussion habe ich es mir nun erlaubt, das Weglassen des Punktes bei vierstelligen Zahlen wieder als den Standardfall anzuführen, mit der Ausnahmeregelung bei direktem Bezug zu mehr-als-vierstelligen Zahlen. Die vorherige Formulierung war schwammig und mehrdeutig.--MKI 16:03, 25. Mär 2006 (CET)
-
- Hallo Leute! Ich bin dafür, schon bei vierstelligen Zahlen einen Tausenderpunkt zu setzen. Der Artikel Mülldorf (Version von 20:31, 22. Mai 2006) enthielt die Passage „1969 hatte Mülldorf 3852 Einwohner [...], 2002 dagegen 8757 [...]. Ein besonders hohes Wachstum ist zwischen den Jahren 1969 und 1975 zu erkennen (1815 zugezogen), [...] sowie zwischen 1985 und 1990 (2402 zugezogen)“. Sowas ist deutlich besser lesbar, wenn man es so schreibt: „1969 hatte Mülldorf 3.852 Einwohner [...], 2002 dagegen 8.757 [...]. Ein besonders hohes Wachstum ist zwischen den Jahren 1969 und 1975 zu erkennen (1.815 zugezogen), [...] sowie zwischen 1985 und 1990 (2.402 zugezogen)“. Dann ist nämlich gleich auf den ersten Blick klar, was Jahres- und was Einwohnerzahlen sind. MfG Stefan Knauf 18:18, 23. Mai 2006 (CEST)
[Bearbeiten] Weg vom Punkt als Tausendertrennzeichen...
Ich weiss, dieses Thema wurde schon 100x durchgekaut, doch es ist für mich immer noch sehr unbefriedigend.
Als Schweizer interpretiere ich die meisten Zahlenwerte in der de-WP fast stets falsch. Z.B. bei "370.000" lese ich immer "370 komma 000" und diese Tatsache hat mich schon häufig verwirrt (à la: "Was? 'nur' 370??? Ich dachte es seien viel mehr..."). Zudem: Bei Werten wie "23.675,345" muss ich schon sehr genau schauen um das Komma vom Punkt zu unterscheiden und nach 2-3 Überlegen kapieren, dass es nicht 23, aber auch nicht 23 Millionen (für Schweizer "Laien" sind Punkt und Komma häufig dasselbe), sondern 23 Tausend sind.
Es wäre das einfachste, wenn eine "länderneutrale" Form eingeführt werden könnte. Hochkommata geht wohl nicht, da es in D wohl nicht die Norm ist. Bleibt nur noch das geschützte Leerzeichen. Viele Artikel haben heute schon -Zeichen, welche in allen möglichen Arten eingesetzt werden, so dass diese auch für "dumme" geläufig ist (im Gegensatz zu früher, wo das -Zeichen verteufelt wurde). Daher sehe ich kein Problem, wenn man den Einsatz des geschützen Leerzeichens noch auf die Tausendertrennzeichen erweitert wird. --Benutzer:Filzstift ✑ 12:20, 22. Nov. 2006 (CET)
- Hallo Filzstift! Geschützte Leerzeichen haben aber den Nachteil, dass sie genau wie normale Leerzeichen aussehen, welche allerdings schon als Trennzeichen zwischen Wörtern benutzt werden, was z.B. bei Angaben wie „65 536-Farben-Bildschirmen“ oder „6 150-PS-Motoren“ missverständlich ist. Übrigens würde ich Schriftarten, in denen Punkte wie Kommata aussehen, nicht nur wegen der Zahlendarstellungen nicht benutzen... MfG Stefan Knauf 23:23, 1. Dez. 2006 (CET)
Das Problem besteht vor allem darin, dass die WP hier wieder einmal eine eigene, nicht normgerechte Schreibweise unterstützt. In Deutschland ist es 100%ig normwidrig, einen Punkt als Tausendertrennung zu benutzen. Das bedeutet: Schüler bzw. Schülerinnen, welche den Punkt zur Tausendertrennung benutzen, bekommen dies in 99% der Fälle als Fehler angerechnet. Eine Berechnung kann also als numerisch falsch bewertet werden, obwohl sie richtig gerechnet wurde. Wieder einmal haben sich in der WP Personen durchgesetzt, welche keinerlei Rücksicht auf Schüler bzw. Schülerinnen nehmen, obwohl diese einen großen Anteil an der WP-Leserschaft haben, wenn auch nicht unbedingt als Autoren. Ich werde daher Tausender niemals mit dem Punkt, sondern immer mit "nbsp" oder blank (bei "nowrap") trennen. Bei schweizbezogenen Seiten nur nach deren Norm. Ich empfehle allen anderen Usern, ebenfalls normgerecht vorzugehen. Augiasstallputzer ☺ 08:52, 22. Dez. 2006 (CET)
- Zunächst mal etwas Grundsätzliches: Auch ohne Meinungsbild dürfen so wesentliche Inahlte im Wikipedia-Namensraum nicht geändert werden, ohne vorher auf der Diskussionsseite einen gewissen Konsens hergestellt zu haben, erst recht nicht, wenn es hier bereits Diskussionen zu diesem Thema gab, die ein klar anderes Ergebnis hatten. Und noch dazu markiert man eine solche Änderung nicht als "Nur Kleinigkeiten wurden geändert."
- Zum Thema: Ein geht überhaupt nicht, denn neben den oben beschriebenen unschönen Zeilenumbrüchen ist es einfach viel zu breit. Da käme nur ein   in Frage, aber das wird leider vom IE nicht richtig dargestellt.
- Dass diese Schreibweise in Schulen als falsch gilt, halte ich für unerheblich. Als Schüler wird man ständig irgendwo von der Norm abweichende Schreibweisen finden, in zeitungen wimmelt es auch von Rechtschreibfehlern, FAZ und Springe schreiben gar bewusst alles falsch - ein Schüler muss damit klarkommen, dass es solche Differenzen gibt. -- H005 10:58, 22. Dez. 2006 (CET)
- 1. Ohne MB darf ich grundsätzlich mal alles, was nicht gegen die vier Grundregeln oder WP:WPNI verstößt und keinen Schaden verursacht. Diese Grenzen sind eingehalten.
- 2. Deine Auffassung gegenüber Schülern - ich bin kein Schüler - finde ich geradezu arrogant. Wer gibt dir das Recht, Schüler so geringzuschätzen ? Immerhin greifen diese oft auf die WP als Informationsquelle zurück, seltener auf Zeitungen.
Augiasstallputzer ☺ 12:31, 22. Dez. 2006 (CET)
-
- Ohne MB darf ich auch alles, z. B. deine Änderung zurücksetzen, weil ich nicht damit einverstanden bin. Des Weiteren schließe ich mich H005s Argumenten an. --jpp ?! 12:44, 22. Dez. 2006 (CET) PS: Im Gegensatz zu dir traut H005 Schülern zu, mit unterschiedlichen Regeln umgehen zu können. Also schätzt eher du sie gering.
- Augiasstallputzer, du solltest eigentlich lange genug dabei sein, um zu wissen, dass eigenmächtige inhaltliche Änderungen von Richtlinien hier nicht gern gesehen sind. Diese Richtlinien sollen den Konsens der Wikipedianer widerspiegeln und nicht persönliche Präferenzen. Eigentlich eine Selbstverständlichkeit - muss man denn für alles hier schriftliche Regeln niederschreiben?
- Zu den Schülern kann ich mich Jpp nur anschließen. Du hältst sie offensichtlich für unfähig, solche Unterschiede zu erkennen und damit umzugehen. -- H005 15:06, 22. Dez. 2006 (CET)
Also eigentlich wäre das doch mal ein Grund, bei der W3C eine Locale-abhängige Schreibweise einzuführen. Heisst, XML/HTML-Tags, die die Tausendertrennung/Dezimaltrennung beschreiben und je nach der Locale-Einstellung in jedem Land anders aussehen.
Also zum Beispiel: 23&th;000&dp;00
Oder ist sowas evtl. schon irgendwo in der Diskussion?
Oder auch Wiki-Tags: <wiki-th /> und <wiki-dp />
Meinungen? -- Anhi 14:01, 22. Dez. 2006 (CET)
- Die englische Wikipedia hat so etwas ja schon für Datumsschreibweisen realisiert. Wie sie das aber hinbekommen hat, weiß ich nicht. Ich glaube, dass das irgendwie mithilfe der Wiki-Software umgesetzt wurde, denn es ist eine Wikipedia-Benutzereinstellung unabhängig von den Vorgaben des Betriebssystems. -- H005 15:12, 22. Dez. 2006 (CET)
Wie ist das denn mit   (» «) und IE7? Wenn der das kann, sollte man vielleicht noch mal über jene als Tausendertrennzeichen nachdenken, oder? -- Pemu 03:31, 27. Dez. 2006 (CET)
-   erzeugt leider nicht nur auf alten IE's Probleme. Im Übrigen find ich einen geraden Apostrophen als Tausenderkennzeichen gar nicht so übel. Ich hab ihn selbst schon in handschriftlichen Aufzeichnungen benutzt, auch damals in der Schule, als Internet und Wikipedia noch in weiter Ferne lagen. :-) Vielleicht bin ich auf die Idee gekommen, weil ich dies auf irgend einem alten Taschenrechner mal gesehen hatte. Ich fand das jedenfalls ungemein praktisch und bekam dafür auch nie einen Fehler angestrichen. Wobei mein Tausendertrenn-Apostroph sehr sehr klein war und eigentlich nur ein hochgestelltes Pünktchen. Also vielleicht so: 12·345·678·900. Verwechslungen mit Komma, Punkt oder sonstwas war ausgeschlossen und das auch noch beim Nachlesen nach mehreren Jahren. Leider entspricht so ein Tausenderkennzeichen nun gar keiner Norm. :-(
- Ich wäre sehr dafür, dass Zahlen nur logisch formatiert werden, also im Wikitext einfach
<num>1234567890.1666</num>geschrieben wird, und dann generiert die Wikisoftware, abhängig von den gewünschten Nutzereinstellungen, daraus dann die Tausender- und Dezimaltrennzeichen, die jede Einzelne haben will. Bei TeX-Formeln klappt das ja auch schon ganz gut. Ich halte das für die sauberste Lösung (logisch statt physische Formatierung) und die einzige, mit der jede das angezeigt bekommt, was sie will. --RokerHRO 12:57, 3. Jan. 2007 (CET)
-
- Dafür! --Lutz 12:09, 21. Mär. 2008 (CET)
[Bearbeiten] Tausender-Trennzeichen und Barrierefreiheit
Da ich ein neues, in meinen Augen recht bedeutendes Argument vorlege, öffne ich deshalb einen neuen Abschnitt auf dieser Seite. Hier geht es nicht um persönliche Vorlieben oder die Einhaltung von Regeln, sondern um den Zugang zur Wikipedia für behinderte Menschen, also die Barrierefreiheit der Wikipedia:
Ein Punkt als Tausender-Trennzeichen halte ich für Leseprogramme, die von Sehbehinderten verwendet werden, für unverständlich - vor allem wegen der Verwechslung mit dem englichen Dezimalzeichen, das ja ebenfalls und korrekt ein Punkt ist. 14.000 würde von einem solchen Programm also als 14 "Komma" 000 gelesen werden. Auch Programme, die den Sinn und Inhalt eines Textes verstehen sollen (semantisches Web), werden 14.000 entsprechend interpretieren. Mein Vorschlag ist daher, auf Tausendertrennzeichen zu verzichten.
Gute Browser können Zahlen übrigens sowieso in der vom Benutzer gewünschten Formatierung, zum Beispiel mit einem Punkt oder einem Leerzeichen nach jeweils drei Ziffern (von rechts gezählt) darstellen. Nachdem HTML nie zur Formatierung von Texten, sondern zur Auszeichnung der Textbestandteile mit Informationen auf ihre Bedeutung im Text vorgesehen war, halte ich es insgesamt für falsch, Zahlen in HTML-Texten formatieren zu wollen. (Der vorstehende, nicht signierte Beitrag stammt von 84.151.225.208 (Diskussion • Beiträge) 2007-01-13 22:36:06)
- Ist das eine Vermutung von dir und kennst du solche Programme, die diesen Fehler machen? Das ist nämlich für Programm ganz leicht zu erkennen, das der Punkt nicht für ein Satzende steht. Und es gibt verm. hunderte/tausende Webseiten auf denen der Punkt als Zahlentrennzeichen fungiert (also müssen die Programme darauf traniert sein, sowas zu erkennen).
- Der Tausenderpunkt ist auch keine Textauszeichnung, sondern Teil der Textes. --DaB. 22:40, 13. Jan. 2007 (CET)
-
- Es geht nicht um die Verwechslung Punkt als Trennzeichen-Satzpunkt, sondern um die Verwechslung Punkt als Tausender-Trennzeichen-Punkt als Dezimalzeichen. Da der Punkt als Dezimalzeichen stets im Englischen (u.a. Standard für internationale Computerprogramme) und oft auch im Deutschen (z.B. 2.4 m) als Dezimalzeichen verwendet wird, ist die Gefahr einer falschen Interpretierung - nicht für menschliche Benutzer, sondern für Computerprogramme - groß.
- Der Tausenderpunkt ist zwar Teil des Textes, aber nicht inhaltlicher, sondern formatierender Teil. Eine Zahl heißt zum Beispiel 14000; sie wird lediglich als 14.000 oder 14 000 oder auch als 14000 (hier Schreibweise der Zahl, vor dem Strichpunkt die Zahl selbst) dargestellt.
--84.151.225.208 23:02, 13. Jan. 2007 (CET)
- Ich hielte das eher für eine Schwäche einer solchen Lesesoftware denn für eine der Wikipedia, denn Tausenderpunkte sind auf deutschsprachigen Webseiten gang und gäbe.
- Sie sind es auch auf englisch-sprachigen, dort aber als korrektes Dezimalzeichen. Und auch im Deutschen wird der Punkt (genauso) falsch als Dezimalzeichen verwendet, z.B. 2.4 m. --84.151.225.208 23:02, 13. Jan. 2007 (CET)
- Nach wie vor denke ich, dass eine Änderung der Wikisoftware, die Zahlen in Abhängigkeit von den Benutzereinstellungen anzeigt (das müsste übrigens auch ohne
<num>-Tags gehen), die optimale Lösung wäre. Aber wie kann man so etwas "pushen"? -- H005 22:51, 13. Jan. 2007 (CET)
-
- Wie schon geschrieben: Das muss nicht Aufgabe der Wiki-Software sein, das sollte eher im Browser geschehen. --84.151.225.208 23:02, 13. Jan. 2007 (CET)
-
-
- Dann sende Patches an den FF, Opera und IE ;). Vielleciht hast du ja Glück und es wird eingebaut. Bis dahin sollte alles so bleiben, wie es ist. --DaB. 23:04, 13. Jan. 2007 (CET)
-
-
-
- Ja, das wäre schön, wenn alle Browser das machten - halte ich aber für recht utopisch, eine änderung der Wiki-Software ist da weitaus realistischer. -- H005 17:27, 14. Jan. 2007 (CET)
-
Programmfehler ist das falsche Argument, denn die Zahl 123.456 kann nur im Kontext richtig interpretiert werden. Eine Lesehilfe soll nicht den Textinhalt erschliessen. Lesehilfen haben lediglich Syntaxregeln zu befolgen. Es wäre schon viel geholfen, wenn Punkt und Komma nur als Dezimalzeichen verwendet würden. Befremdent wirkt auch, dass Wikipedia auf proprietäre Software und deren Unzulänglichkeiten rücksicht nehmen soll. Einerseits wird also verlangt weil Browser xy das nicht kann die Schreibregel anzupassen, andererseits ist man nicht bereit zugunsten der Barrierefreiheit Kompromisse einzugehen. -- visi-on TWW 11:50, 28. Feb. 2007 (CET)
- Das hat vielleicht auch einfach etwas mit Mehrheitsverhältnissen zu tun. Warum sollte man für Benutzer, die IE benutzen (immerhin die weite Mehrheit), absichtlich die Darstellung verschlechtern, damit in einigen Randfällen Screenreader besser klar kommen? Ich finde es durchaus sinnvoll, solche Fragen pragmatisch statt dogmatisch zu beantworten. sebmol ? ! 12:06, 28. Feb. 2007 (CET)
[Bearbeiten] mehr als drei Nachkommastellen
Wie formatieren wir denn Zahlen mit mehr als drei Nachkommastellen?
- Trennen wir jeweils drei Ziffern durch ein Leerzeichen wie in Kreiszahl? („3,141 592 653“)
- Oder trennen wir jeweils drei Ziffern durch einen Punkt wie vor dem Komma? („3,141.592.653“)
- Oder trennen wir garnicht? („3,141592653“)
- Oder legen wir das lieber nicht fest?
--jpp ?! 14:13, 27. Apr. 2007 (CEST)
- nach DIN (vor und nach Dezimaltrennzeichen (Komma)
- Wikipedia (
<!--schweizbezogen-->Hochkomma statt Punkt), nach Duden "veraltet" - Wikipedia formatnum: 3,141592653589793238462643383279502884197169399375105820974944592307816406286208998628034825342117
- gute Frage! faktisch nicht festgelegt.
-- visi-on 12:13, 8. Mai 2007 (CEST)
-
- Mit Formatnum kannte ich nicht, macht bei mir im obigem Fall auch nichts.
- Noch Mal als Beispiel: {{formatnum:123456789.123456789}} macht 123.456.789,123456789 und
- das falsche {{formatnum:123456789,123456789}} macht 123.456.789.123.456.789.
- --Lutz 12:09, 21. Mär. 2008 (CET)
[Bearbeiten] Zahlenschreibweise zum x-ten
Meiner Meinung nach darf das Problem von Tausendertrennzeichen und Dezimaltrennzeichen nicht unabhängig voneinander betrachtet werden. Zahlen sollten 1. leicht lesbar sein (deshalb überhaupt Tausendertrennzeichen) und 2. eindeutig verständlich (deshalb ein Dezimaltrennzeichen, das nicht mit einem Tausendertrennzeichen verwechselt werden kann). In der vorstehenden Diskussion habe ich zur Kenntnis genommen, dass 1. je nach Land Punkt oder Komma als Dezimaltrennzeichen verwendet werden und 2. je nach Land und Schreibnorm Punkt, Komma, Leerzeichen, schmales Leerzeichen oder Hochkomma/Apostroph als Tausendertrennzeichen. Weiter sind die Gründe dargelegt worden, warum für Wikipedia ein Leerzeichen ungünstig ist. Die vorgeschlagene Regel, die zwischen "schweizbezogenen" und anderen Texten unterscheidet empfinde ich ebenfalls als unglücklich. Die deutschsprachige Wikipedia sollte auch für englischsprechende Leser verständlich sein; und dies geht mit einer einigermassen einheitlichen Schreibweise besser. Mein Vorschlag lautet deshalb: ein tiefstenhendes Zeichen (Punkt oder Komma nach freier Wahl) als Dezimaltrennzeichen, und ein hochstehendes Zeichen (' oder ähnliche Zeichen) als Tausendertrennzeichen. Diese Schreibweise führt nicht zu Verwechslungen, da ' nirgends als Dezimaltrennzeichen verwendet wird. --P ev 02:34, 29. Apr. 2007 (CEST)
- pragmatisch: die Schweizer Hochkommaregel. wer hats erfunden? ;-) :-) ... und wir werden weiterhin an unseren Gewohnheiten festhalten! Evtl. sollten wir doch wiedermal ein Meinungsbild abfragen. Die plausiblen Argumente für den Tausendertrennpunkt, habe ich in der bisherigen Disskusion vermisst.-- visi-on 12:38, 8. Mai 2007 (CEST)
- Das Hochkomma ist außerhalb der Schweiz völlig unüblich, denn normalerweise wird (außerhalb von Wikipedia) in professionell gesetzten Texten die noch bessere Variante mit schmalen Leerzeichen verwendet. Der Tausender-Punkt und die Unterscheidung zwischen "schweizbezogen"/"nicht schweizbezogen" erscheint mir daher verglichen mit einer für Nicht-Schweizer auffälligen, vom Inhalt ablenkenden Hochkommaschreibweise als das kleinere Übel. Noch eher zumutbar wäre das geschützte Leerzeichen, das HTML-Neulinge abschreckt und den Quelltext verschandelt. Eine Optimierung der Lesbarkeit für englischsprachige Leser kommt überhaupt nicht in Frage. Verständlich genug ist die Zahlenschreibweise für nicht deutschsprachige Leser allemal. --80.129.117.38 13:38, 8. Mai 2007 (CEST)
- Ein anderer Vorschlag: Ein "_" in einer Zahl im Quelltext wird vom Interpreter-Teil der MediaWiki-Software in ein schmales geschütztes Leerzeichen oder, falls das zu Browser-Problemen führt, in ein normales geschütztes Leerzeichen umgewandelt. --80.129.117.38 13:54, 8. Mai 2007 (CEST)
-
- Wozu so kompliziert? Wenn du in die Wiki-Software eingreifst, kannst du auch Leerzeichen zwischen Ziffern entsprechend interpretieren. Was dann in der HTML-Source drin steht dürfte egal sein. Das Spezialzeichen kann in jeder gewünschten Breite gargestellt werden.
- 123 456
<span style="font-size:50%" > </span> - 123 456
<span style="font-size:200%" > </span> - 123 456
-
- Mein Vorschlag wäre immernoch die Parserfunktion formatnum entsprechend anzupassen. Für den Tausendertrennpunkt spricht nur die Gewohnheit. Er kann aber fehlinterpretiert werden und ist nicht Barrierefrei. Auch das Hochkomma ist im Übrigen Gewohnheitsrecht, kann aber nicht fehlinterpretiert werden.-- visi-on 15:20, 8. Mai 2007 (CEST)
-
-
- Das trifft genau den Punkit: ist einfach zu schreiben und kann nicht fehlinterpretiert weden. Die weiter unten behauptete Verwechslungsmöglichkeit mit dem Minutensymbol etc. halte ich für gesucht; ob Minuten überhaupt in Frage kommen, dürfte aus dem Kontext immer klar werden, und einfaches Anführungszeichen oder Apostroph haben innerhalb einer Zahl nichts zu suchen, es sei denn als Tausendertrennzeichen. Bei einer Zahl wie 123.456,789 weiss ich in einem mir fremden Fachgebiet nie was sie bedeutet da ich die Grössenordnung meist nicht kenne (und auf die Grössenordnung kommt es doch in erster Linie an). 123'456,789 dagegen interpretiere ich ohne Weiteres als 'etwas über Hunderttausend', auch wenn mir an sich das Dezimalkomma fremd ist.--P ev 17:00, 8. Mai 2007 (CEST)
-
-
-
-
- Nur sind solche Zahlen sehr selten, für die darf ein hoher Leseaufwand eingeplant werden zugunsten einer weniger auffälligen Typographie sehr häufig vorkommender Zahlen (vier- bis neunstellige ganze Zahlen). Eine Fehlinterpretation ist nicht möglich, da spätestens beim Auftreten von Komma und Punkt in der deutschsprachigen Wikipedia klar ist, dass das Komma das Dezimaltrennzeichen ist. Und der Lesefluss oder die schnelle Auffassung kann auch dann gestört sein, wenn der Kontext eine eindeutige Interpretation ermöglicht, daher ist diese Verwechslungsmöglichkeit des Hochkommas eben schon von Bedeutung. Wohlgemerkt reden wir hier überhaupt nur von kleinen Vor- und Nachteilen. --80.129.117.38 18:08, 8. Mai 2007 (CEST)
-
-
-
-
-
-
- Der verzweifelte Versuch ein unglücklich gewähltes Tausendertrennzeichens ...
-
-
-
12'345 kann nie als Minute gelesen werden und wenn nach 12.345 kein Komma folgt kann es auch nur ein wenig mehr als ein Dutzend bedeuten, denn hier schreiben auch deutschsprachige Schweizer. Da ist das Beispiel von den 4 200 Watt Birnen schon eher irritierend, aber letztlich doch noch verständlich. -- visi-on 18:43, 8. Mai 2007 (CEST)
-
-
-
-
-
- Ich habe gerade in dem Artikel Dezimaltrennzeichen gelesen, dass auch in der Schweiz das Komma als Dezimaltrennzeichen verwendet wird, nur bei Geldbeträgen der Punkt. Wenn das stimmt, verstehe ich den Einwand, es irritiere die Schweizer, überhaupt nicht mehr. --80.129.116.52 13:36, 10. Mai 2007 (CEST)
-
-
-
-
-
-
-
-
-
-
- Ganze Generationen wurden mit dem Dezimalpunkt geknechtet. Die Schweiz ist bestenfalls ein sowohl als auch Land. Dem Schweizer ist es bis auf Währungsbeträge egal was da steht. Er schreibt Punkt und sagt Komma. Das rechtfertigt aber nicht ein Dezimaltrennzeichen als Tausendertrennzeichen zu verwenden. Das ist auch die Kernaussage der inzwischen angepassten ISO-Norm. Die Briten trennen sich von ihrem Tausenderkomma und irgendwann dann auch noch die Deutschen vom Tausenderpunkt. Das Hochkomma steht nicht unter Denkmalschutz. -- visi-[[Benutzer
-
-
-
-
-
Diskussion:Visi-on|on]] 20:48, 10. Mai 2007 (CEST)
- Leerzeichen im Quelltext ist auch eine gute Möglichkeit, aber mit dem kleinen Nachteil, dass das im Quelltext umgebrochen wird und vermutlich hier und da auch Zahlen nebeneinanderstehen, die nicht enger aneinandergerückt werden sollen (das sollte aber ohnehin vermieden werden). Die Breite des normalen geschützten Leerzeichens (" " oder " ", seit HTML 3.2) sollte besser nicht geändert werden, denn es wird ja auch anderswo verwendet. Die Browser-Probleme mit dem schmalen geschützten Leerzeichen (" " oder " ", seit HTML 4.0), sofern sie überhaupt noch gravierend sind, gibt es wahrscheinlich auch mit style-Befehlen. Das formatnum ist auch ein wenig abschreckend für Neulinge und etwas unschön im Quelltext, und es verbraucht beim Seitenaufruf (noch etwas mehr als mein Vorschlag) ein bisschen zusätzliche Rechenkapazität. Es ist richtig, dass es sich bei dem Hochkomma nur um eine Gewohnheit handelt. Aber die kann Wikipedia nicht ändern, zumal die Lösung auch davon abgesehen noch nicht ganz optimal ist (Verwechslung mit Minutensymbol, einfachem Anführungszeichen oder Apostroph, "cut-and-paste" zur Zahlenverarbeitung ist erschwert). Wenn es einen hochgestellten Punkt geben würde, könnte ich mich damit eher anfreunden, da er fast als schmales Leerzeichen gelesen werden kann und keine Verwechslung mit anderen Zeichen möglich ist. --80.129.117.38 16:08, 8. Mai 2007 (CEST)
- cut and paste ist nur mit Leerzeichen einigermassen kompatibel zum Rest der Welt. Im Allgemeinen müssen so oder so die Trennzeichen rausgefiltert werden. Jede Zeichenfolgenmanipulation kostet etwas. Entweder man kennzeichnet zu formatierende Zahlen im Text (tags / parserfunction) oder man schliesst Zahlenfolgen durch tags von der automatischen Formatierung aus. Ich habe nur nicht unbedingt den Nerv auf diese Softwareänderung zu warten. Nur ist ein nonbrakable space zu allen anderen spaces sagt HTML nur etwas über die breite der Darstellung aus. Entsprechend interpretiert das auch jeder Browser anders und brechen den Text an ungewollten Stellen um. Von mir aus darf es auch ein ungestyltes sein.-- visi-on 16:48, 8. Mai 2007 (CEST)
-
- Eine Änderung aller betroffenen Zahlen auf eine neue Konvention dürfte aber in jedem Fall einige Zeit dauern. Ein normales " " wäre sicher ok, wenn die schmalen Leerzeichen zu technischen Problemen führen (bedauerlich, denn es ist die Aufgabe von HTML, das möglichst effizient zu handhaben). Ich bin davon ausgegangen, dass nur bei normalen Leerzeichen ein Umbruch erlaubt ist und die Abkürzung "nbsp" nur den Sinn dieses Zeichens erläutert, aber es mag sein, dass dies nicht stimmt. --80.129.117.38 18:08, 8. Mai 2007 (CEST)
thin space heisst nur dünnes Leerzeichen, von nonbrakable steht nichts. -- visi-on 18:43, 8. Mai 2007 (CEST)
- Dem Artikel Schmales Leerzeichen entnehme ich, dass es auch ein geschütztes schmales Leerzeichen, " ", gibt. Demzufolge hast Du wahrscheinlich recht (die Aussage "Per Definition ist an einem schmalen Leerzeichen nie ein Zeilenumbruch erlaubt" ist anscheinend falsch). Es ist semantisch etwas fragwürdig in Unicode, nicht HTML definiert. --80.129.116.52 13:36, 10. Mai 2007 (CEST)
-
- Irgendwann ist das sicher mal verbindlich und unmissverständlich definiert. Abwarten bis das Geschützte Leerzeichen &nnbsp; in HTML definiert ist. Bis dahin sind die Alternativen Hochkomma oder .-- visi-on 20:48, 10. Mai 2007 (CEST)
[Bearbeiten] Trennzeichen (Punkt) immer bei vierstelligen Zahlen (außer Jahreszahlen)
- „Ein Tausendertrennzeichen wird in der Regel erst ab fünf Stellen gesetzt.“
Ich bin der Meinung, dass vierstellige Zahlen immer mit dem Trennzeichen Punkt getrennt werden sollten, wenn es sich nicht um eine Jahreszahl handelt. Man kann dann zügig erkennen, ohne den jeweiligen Satz zu lesen, dass es sich nicht um eine Jahreszahl handelt. Außerdem habe ich bisher nahezu immer diese Version &ndash mit Punkt – bei vierstelligen Zahlen (nicht Jahreszahlen!) gesehen, dass dort ein Punkt gesetzt wurde. – Despairing ♠, 16:42, 9. Aug. 2007 (CEST)
- weiter oben wurden schon mehrere diskussionen dazu gefuehrt. wenn du nach "vierstellig" suchst, wirst du die stellen finden. -- seth 00:05, 10. Aug. 2007 (CEST)
[Bearbeiten] "Punkt als Tausender-Trennzeichen, die Zwoohundertdritte!"
Ja, ich weiss, die Diskussion wird seit Anno Tobak geführt (und ich habe sie fast ganz durchgelesen!), aber weder ist die Sache wirklich gelöst, noch ist die "Lösung" befriedigend - wie der Artikel Acre zeigt. Zuerst geglaubt, den hätte jemand aus dem Englischen übersetzt ohne ihn an die deutschsprachigen Zahlenschreibkonventionen anzupassen - dann festgestellt, dass die Trennung von Tausendern mit Punkt Wikipedia-Praxis ist - und das obwohl alle offiziellen Schreibkonventionsverzeichnisse etwas anderes sagen (vergl.hier vs. hier). Staun! Ich bin Schweizer, aber ich kann mit beidem, Komma und Punkt als Dezimaltrennzeichen umgehen, einfach weil bei uns beides verwendet wird. Ich lese oft englischsprachige Texte - und kann mit der v.a. US-amerikanischen Praxis der Tausenderschwellen-Markierung durch Punkt umgehen. Aber die Aussage im (wie gesagt deutschsprachigen) Artikel "1 Acre = 4.046 m²" hat mich dann doch ins Rotieren gebracht: ist ein Acre jetzt also 4 Komma irgendwas m² oder gut 4 Tausend m²? Beides ist möglich, und Klärung bringt nur die Suche im Artikel nach einer Zahl, die die Verwendung von Punkt und Komma definiert: Weiter unten steht dann tatsächlich: "1 Acre = 4.046,8564224 m²" (Und sagt mir damit: versteh den Punkt in der Zahl als Tausendertrennzeichen). Wird diese irritierende Praxis dann im Text wenigstens konsequent durchgehalten (nämlich vielleicht, weil es um ein US-amerikanisches Thema geht und man deshalb die entsprechende Zahlenschreibung pflegen möchte)? Natürlich nicht: "3 Acre = 12 140 m²". Hmm... Und wer garantiert mir, verunsicher wie ich bin, dass die Zahl 43 in "1 Acre =43.560 ft²" als 43 Tausend zu lesen ist - möglicherweise wurde dieser Abschnitt ja von jemandem verfasst, der zur Dezimaltrennung Punkte benutzt. Fazit: Ich muss alle Angaben im Kopf rechnerisch überschlagen um mich zu versichern, dass ich die Zahlen richtige lese. Eine Enzyklopädie soll möglichst leserfreundlich i.e. klar verständlich sein. Dass sie einfach zu SCHREIBEN sein müsste, hat niemand verlangt. Und solange sowohl Punkt als auch Komma im deutschsprachigen Raum als Dezimalzeichen in Gebrauch sind, ist es ungünstig, dem einen dieser Zeichen im selben Kontext (steht zwischen Ziffern, steht auf der Grundlinie) eine zweite, völlig andere Bedeutung zuzuweisen. Sonderregelungen der Wikipedia nützen da nichts. Denn die können nur das Verfassen reglementieren. Nicht das Verstehen. Die Wiki hat aber mehr Leser als Verfasser. Ich bin deshalb dafür, dass die derzeitige "Regelung" (Punkt markiert Tausendergrenze) geändert wird. nouly 20:53, 24. Nov. 2007 (CET)
- Wenn du die Diskussion gelesen hast: Wieso nimmst du dann nicht Stellung zu den Gegenargumenten? Deine Argumente sind nicht neu. Die derzeitige Regelung wird von niemandem als befriedigend angesehen, sondern als derzeit noch notwendiges Übel. Sobald die Software von Wiki und allen gängigen Browsern das Einfügen schmaler, nicht umbrechender Leerzeichen in Zahlen unterstützt, ist das Problem gelöst. Da vor allem Schweizer Anstoß am derzeitigen Zustand nehmen, hier noch ein Zitat aus Peter Gallmann, Graphische Elemente der geschriebenen Sprache, 1985, S. 227: „Auch die Schweiz fährt ein Sonderzüglein: Aus auch mir als Schweizer nicht bekannten Gründen werden hierzulande Währungsbeträge (§ 1016) nicht mit Dezimalkomma, sondern mit Dezimalpunkt abgetrennt: 98.75 Fr. (aber: 98,75 DM; 98,50 S)“ Mit Logik hat das nichts zu tun, sondern nur mit Lesegewohnheit. Die ist in der Schweiz wegen des möglichen Dezimalpunkts ein wenig anders als in Österreich und Deutschland, wo nie ein Dezimalpunkt verwendet wird, aber noch häufig ein Tausenderpunkt. Der Artikel Acre kann übrigens verbessert werden, indem überall noch eine Nachkommastelle angegeben wird. Auch die Anwendung von „Ein Tausendertrennzeichen wird in der Regel erst ab fünf Stellen gesetzt“ schafft hier bereits Abhilfe. --80.129.78.172 21:30, 24. Nov. 2007 (CET)
- Schon mal Vorlage:FormatNum angeschaut? Das Tausendertrennzeichen durch <small>&nsbp;</small> ersetzen und die Sache ist gegessen. Wie bereits gesagt, in Schönheit sterben kann man immernoch. Die schweizerische Sortentrennung ist im übrigen im internationalen Bankwesen (London, New York, Tokio, Zürich) nicht so unerklärlich. Und dass es auch im deutschsprachigen Raum nicht zu Verwechslungen kommt stellt man halt das englische Tausendertrennkomma hoch. Man passt sich halt an ;-) -- visi-on 22:15, 24. Nov. 2007 (CET)
- Verzeih, ich wusste nicht, dass die derzeitige Regelung nicht als definitiv erachtet wird. Was ich gelesen habe, hat einen anderen Eindruck gemacht. Falsch gelesen. Dass mein Argument nicht neu ist - macht es dieser Umstand wertlos? Und wenn wir warten auf eine bessere Lösung: warum dann nicht mit der Interimsregelung "wir setzen keine Tausendermarkierung"? Warum mit der Regelung "Wir setzen Punkte"? Ersteres wäre weit weniger verwirrend. Stellung zu nehmen zu "Pro-Punkt"-Argumenten, die in den Jahren 2003 - 2006 hier deponiert wurden, bedeutet, ins selbe Fahrwasser, mit den selben Fronten zu geraten. Besser, die alten Argumente vorerst in der Vergangenheit ruhen zu lassen - ja, auch weil ich finde, dass sie zu einer schlechten Lösung geführt haben - wie interimistisch die auch immer sein mag. Aber bitte: Keines der "pro-Punkt" Argumente hat mich so überzeugt, dass sich damit der Status Quo entschuldigen lässt. Jedes der Kontra-Argumente ist eine Variante der Aussage "Der Punkt in der Zahl macht die Zahl ambivalent: verschiedene Lesarten sind möglich". Das finde ich überzeugend. Und das ist meine Erfahrung (und die wollte ich mit meinem obigen Beitrag mitteilen; als Argument, sozusagen). nouly 00:15, 25. Nov. 2007 (CET)
- @Visi-on: Tausenderapostroph oben, find ich auch. nouly 00:15, 25. Nov. 2007 (CET)
- Zahlendarstellung ist eben ein internationales Problem, mit dem die Schweiz schon etwas früher konfrontiert wurde. Eigentlich hätten es sich die Normungsgremien einfach machen können und die schweizerische Lösung übernehmen können. Auch die Wikipedia könnte, wenn man sich schon an keinen Standard hält. Als Tausendertrennzeichen ist weder Komma noch Punkt geeignet.-- visi-on 01:09, 25. Nov. 2007 (CET)
- @Visi-on: Tausenderapostroph oben, find ich auch. nouly 00:15, 25. Nov. 2007 (CET)
[Bearbeiten] Stand dieser Diskussion darstellen!
Ich will diese ewig lange Diskussion jetzt nicht neu anfangen, sondern darauf hinweisen, dass es ein besch... Zustand ist, dass man sich hier ewig durcharbeiten muss, um zu erfahren, was Sache ist. Wenn man die Empfehlungen liest, fragt sich zunächst jeder, der sich mit der Frage auskennt, warum Wikipedia sich mal wieder eine Extrawurst brät und sowohl alle außerhalb gültigen Konventionen ignoriert als auch die Empfehlungen von Organisationen, die sich unabhängig von Konventionen lang und breit mit der Frage beschäftigt haben, was sinnvoll ist. Die Frage wird nicht beantwortet. Mancher landet dann zwangsläufig hier. Ich zitiere aus dem letzten Abschnitt:
(Jemand stellt sehr gut fundiert mit Beispielen dar, warum die jetzige Regelung ausgesprochen schlecht ist, weist auch auf die gültigen Normen, Empfehlungen usw. hin und insbesondere auf die Tatsache, dass der Leser der Maßstab ist und nicht der Autor.)
Antwort: ...Die derzeitige Regelung wird von niemandem als befriedigend angesehen, sondern als derzeit noch notwendiges Übel. Sobald die Software von Wiki und allen gängigen Browsern das Einfügen schmaler, nicht umbrechender Leerzeichen in Zahlen unterstützt, ist das Problem gelöst....
Rückantwort: Verzeih, ich wusste nicht, dass die derzeitige Regelung nicht als definitiv erachtet wird. Was ich gelesen habe, hat einen anderen Eindruck gemacht. Falsch gelesen....
Gelesen hat der Autor mit den Empfehlungen, der "Vorderseite" dieser Diskussion, verlinkt. Er hat nicht falsch gelesen und nicht er müsste sich entschuldigen. Es steht nirgends, dass die Regeln vorläufig sind. Ist das überhaupt allgemeiner Konsens oder Einzelmeinung? Was ist denn jetzt eigentlich mit den " "? Werden die wirklich immer noch nicht von den aktuellen Browsern unterstützt? Bricht irgendeiner tatsächlich am " " um? Das wär mir völlig neu. Oder warum sonst sollte ich sie nicht verwenden, wenn ich mir die Mühe machen will? Was spricht gegen " " als vorläufige Lösung? Warum braucht man erst neue Wiki-Software?
Es muss meines Erachtens dringend auf die "WP:Schreibweise..."-Seite, was der Stand hier ist. So kurz gefasst wie möglich natürlich. Aber dann würde hier auch nicht immer die gleiche Diskussion anfangen. Vor allem die Vorläufigkeit und die konkrete Bedingung für die endgültige Regelung sollte genannt werden.--Lax 17:56, 7. Mär. 2008 (CET)
- " " wird bis ms-ie 6.0 falsch dargestellt (als kaestchen oder ueberbreites leerzeichen). wenn uns das egal ist, spricht afaics nichts mehr gegen thinsp. -- seth 23:19, 20. Mär. 2008 (CET)
-
-
- geringfuegige beeintraechtigungen der lesbarkeit des codes sind kein wichtiges kriterium, das wurde in anderen diskussionen immer wieder betont. sonst duerften wir in anderen faellen auch keine nbsp; verwenden und auch kein tex.
- ja, der punkt ist ziemlich bekannt, aber eben nicht standardkonform (duden, iso, ...).
- thinsp ist auch ausserhalb der wikipedia zu finden, z.b. [1], aber nicht haeufig. thinsp hat jedoch anscheinend den nachteil, gar nicht unbedingt geschuetzt zu sein. firefox behandelt es zwar so, opera jedoch nicht. damit ist thinsp wohl eher wieder vom tisch. :-( -- seth 12:28, 21. Mär. 2008 (CET)
- nbsp wird von MediaWiki in vielen Fällen inzwischen selbständig gesetzt, so zum Beispiel bei Prozentzahlen (da ist also kein nbsp mehr notwendig zwischen Zahl und Zeichen). Was in Normen und Standards steht, ist für uns eigentlich auch nur relevant, wenn der tatsächliche Gebrauch sich daran orientiert und wir das so wollen. Einen Zwang, diesen Standards zu folgen ergibt sich nur aus unseren eigenen Vorstellungen. Das heißt, wenn es in der Wikipedia einen Konsens gäbe, statt des Punktes etwas anderes zu verwenden, dann kann der auch dokumentiert werden. Den sehe ich aber bisher nicht als gegeben an: die Praxis in den Artikeln ist eine andere. sebmol ? ! 13:28, 21. Mär. 2008 (CET)
-
[Bearbeiten] Neue Möglichkeit
Ich möchte auf eine neue Möglichkeit der Tausendertrennung hinweisen. 123{{\ }}456{{\ }}789  123456789. Die Weißräume, erzeugt mit der Vorlage:\, sind schmal (1⁄6em), brechen nicht um und, wenn man die Zahl kopiert, befinden sich keine Leerzeichen mehr darin, was das Kopieren in eine Tabellenkalkulation oder Ähnliches erleichtert und die Barrierefreiheit verbessert. --Quilbert 問 20:26, 30. Mär. 2008 (CEST)
123456789. Die Weißräume, erzeugt mit der Vorlage:\, sind schmal (1⁄6em), brechen nicht um und, wenn man die Zahl kopiert, befinden sich keine Leerzeichen mehr darin, was das Kopieren in eine Tabellenkalkulation oder Ähnliches erleichtert und die Barrierefreiheit verbessert. --Quilbert 問 20:26, 30. Mär. 2008 (CEST)
- oh, das ist echt cool! auch bei starker browser-basierten vergroesserung sieht das noch gut aus.
- hat diese methode denn irgendwelche nachteile? (leicht schlechtere quellcode-lesbarkeit ist kein argument, sonst duerfte beispielsweise auch nicht
z. B.geschrieben werden.) - ach so, es gab doch auch mal eine art vorlage, die selbststaendig zahlen formatierte (siehe #mehr_als_drei_Nachkommastellen, also etwa {{formatnum:12345,67}}). evtl. waere solch eine syntax besser, weil flexibler und "sematischer". -- seth 22:53, 30. Mär. 2008 (CEST)
- Es hat den leichten Nachteil, dass man bei fetten, kursiven oder anderweitig ausgezeichneten Zahlen etwas aufpassen muss, siehe Vorlage:\. Ansonsten ist mir noch keiner in den Sinn gekommen.
- formatnum ist eine Parser-Funktion und verwendet Punkte als Tausendertrennzeichen. Über eine automatische Formatierung mit Zwischenräumen könnte ich mir mal Gedanken machen. --Quilbert 問 23:37, 30. Mär. 2008 (CEST)
- dass html-murks herauskommt, wenn man nicht das end-span-tag manuell setzt, ist auch meiner meinung nach ein nachteil. einen ausweg daraus koennte die besagte vorlage sein, die aehnlich wie formatnum wirkt, bloss eben mit whitespace statt den ollen punkten. ich habe aber vom vorlagen-basteln keine ahnung und weiss deshalb nicht, ob das geht oder ob man z.b. formatnum irgendwie umschreiben koennte. -- seth 00:14, 31. Mär. 2008 (CEST)
-
- Die "leicht schlechtere quellcode-lesbarkeit" ist sehr wohl ein Argument, da Zahlen erheblich häufiger vorkommen als "z. B.", das übrigens in der Regel auch ausgeschrieben werden sollte ("zum Beispiel"). Es wäre ein großer Schritt von einem gut zu überblickenden schreibmaschinenähnlichen Text hin zu einem schwer lesbaren Programmcode. --80.129.73.2 10:53, 31. Mär. 2008 (CEST)
- Das leuchtet mir nicht ein, der Quellcode ist ja nicht zum „Lesen“ da.
- Aber ich wollte eigentlich was anderes, und zwar habe ich jetzt nach einem längeren Kampf die Vorlage:Zahl fertiggestellt. Der Code ist ein Albtraum … aber er funktioniert. Nämlich so:
- {{Zahl|3.14159265359}} 3,14159265359.
- oder z.B.: 1234567890
- Es sind maximal 12 Stellen möglich. --Quilbert 問 11:36, 31. Mär. 2008 (CEST)
- Ach ja, und die span-Tags sind jetzt auch ausgeglichen: Jeden Tag sterben 1173406 Stechmücken an Arsenvergiftung. --Quilbert 問 11:49, 31. Mär. 2008 (CEST)
- Die "leicht schlechtere quellcode-lesbarkeit" ist sehr wohl ein Argument, da Zahlen erheblich häufiger vorkommen als "z. B.", das übrigens in der Regel auch ausgeschrieben werden sollte ("zum Beispiel"). Es wäre ein großer Schritt von einem gut zu überblickenden schreibmaschinenähnlichen Text hin zu einem schwer lesbaren Programmcode. --80.129.73.2 10:53, 31. Mär. 2008 (CEST)
-
-
-
- Aber sicher ist Quellcode auch zum Lesen da. Von mir aus kannst du gerne viel Zeit und Arbeit in eine vermeintliche Lösung für ein kleines, rein ästhetisches Problem investieren, die spätestens bei dem Versuch scheitern wird, sie an unzähligen Stellen in einem Großteil aller Artikel durchzusetzen. --80.129.73.2 12:20, 31. Mär. 2008 (CEST)
- Das Problem ist weder klein noch rein ästhetisch. Argumente, die sich auf die Ästhetik des Quelltexts beziehen, kann ich jedoch nicht nachvollziehen. Zumal die angegebene Variante durchaus gut lesbar ist. --Quilbert 問 13:24, 31. Mär. 2008 (CEST)
- Zum Beispiel tagesschau.de ("25.000 Euro"), spiegel.de ("150.000 Pakete"), zeit.de ("450.000 Quadratmeter", übrigens im Gegensatz zur gedruckten "Zeit"), faz.net ("55.000 Post-Beamten") usw. verwenden den Punkt. Das ist hier natürlich alles schon gesagt worden, nur noch nicht von allen. --80.129.82.103 09:42, 1. Apr. 2008 (CEST)
- wir sind keine zeitung. duden "tausend", brockhaus, meyers lexikon verwenden das leerzeichen zur zifferngruppierung. -- seth 10:10, 1. Apr. 2008 (CEST)
- Die sind alle falsch (breites Leerzeichen). Das könnte man mit nbsp bequem jetzt schon machen (so machen die es ja auch), aber es sieht unmöglich aus, dazu käme die Verschandelung des Quelltexts. Eine elegante Lösung würde ich sehr begrüßen, aber keine mit Pferdefuß: Weder eine "Lösung", die eine Variante mit geringfügigen Nachteilen durch eine andere solche ersetzt, noch eine, die jede größere Zahl in so ein Monster einbaut und nebenbei das Bearbeiten der Artikel wieder ein wenig schwieriger und weniger komfortabel macht. --80.129.82.103 10:55, 1. Apr. 2008 (CEST)
- Wen interessiert der Quelltext der Vorlage? Und was ist an deren Benutzung „schwierig“? --Quilbert 問 15:51, 5. Apr. 2008 (CEST)
- die genannten anderen nachschlagewerke gehen vermutlich den weg ueber normalbreite leerzeichen, da sie keine andere technische moeglichkeit kennen, die halbwegs browserinvariant ein geschuetztes schmales leerzeichen darstellt. Quilbert stellt eine solche moeglichkeit vor. der quellcode, der von autoren verwendet/gelesen wird, ist sehr simpel und imho leicht lesbar. das "monster" muss man ja weder lesen noch verstehen. und wenn es in zukunft mal ne bessere moeglichkeit geben sollte, wird eben einfach der vorlagenquellcode verbessert. -- seth 17:14, 5. Apr. 2008 (CEST)
- Die sind alle falsch (breites Leerzeichen). Das könnte man mit nbsp bequem jetzt schon machen (so machen die es ja auch), aber es sieht unmöglich aus, dazu käme die Verschandelung des Quelltexts. Eine elegante Lösung würde ich sehr begrüßen, aber keine mit Pferdefuß: Weder eine "Lösung", die eine Variante mit geringfügigen Nachteilen durch eine andere solche ersetzt, noch eine, die jede größere Zahl in so ein Monster einbaut und nebenbei das Bearbeiten der Artikel wieder ein wenig schwieriger und weniger komfortabel macht. --80.129.82.103 10:55, 1. Apr. 2008 (CEST)
- wir sind keine zeitung. duden "tausend", brockhaus, meyers lexikon verwenden das leerzeichen zur zifferngruppierung. -- seth 10:10, 1. Apr. 2008 (CEST)
- Zum Beispiel tagesschau.de ("25.000 Euro"), spiegel.de ("150.000 Pakete"), zeit.de ("450.000 Quadratmeter", übrigens im Gegensatz zur gedruckten "Zeit"), faz.net ("55.000 Post-Beamten") usw. verwenden den Punkt. Das ist hier natürlich alles schon gesagt worden, nur noch nicht von allen. --80.129.82.103 09:42, 1. Apr. 2008 (CEST)
- Das Problem ist weder klein noch rein ästhetisch. Argumente, die sich auf die Ästhetik des Quelltexts beziehen, kann ich jedoch nicht nachvollziehen. Zumal die angegebene Variante durchaus gut lesbar ist. --Quilbert 問 13:24, 31. Mär. 2008 (CEST)
- Aber sicher ist Quellcode auch zum Lesen da. Von mir aus kannst du gerne viel Zeit und Arbeit in eine vermeintliche Lösung für ein kleines, rein ästhetisches Problem investieren, die spätestens bei dem Versuch scheitern wird, sie an unzähligen Stellen in einem Großteil aller Artikel durchzusetzen. --80.129.73.2 12:20, 31. Mär. 2008 (CEST)
-
-
[Bearbeiten] verbessert
soeben habe ich gesehen, dass die zahlen-vorlage von Quilbert nun verbessert wurde und damit einsatzfaehig ist. was spricht nun noch gegen die verwendung dieser vorlage? wenn nichts wesentliches dagegen spricht, koennte sie naemlich imho dann in WP:SVZ explizit aufgenommen und deutlicher empfohlen werden. -- seth 15:04, 4. Mai 2008 (CEST)
[Bearbeiten] Revert der Änderung durch Benutzer:Debianux
Ich habe soeben die Änderung von Benutzer:Debianux [2], mit der dieser das geschützte schmale Leerzeichen als Trennzeichen einführen wollte, zurückgesetzt, da sie ohne Diskussion erfolgt und auf WP:FZW auf Ablehnung stieß. --jergen ? 18:01, 18. Jun. 2008 (CEST)
- So, nun meldet sich auch noch der böse Benutzer Debianux: Ich bin davon ausgegangen, dass es sich hier um Fehler handeln, deswegen habe ich den umstrittenen Edit vorgenommen. Diese Diskussionsseite habe ich übrigens vor meinem Edit besucht, jedoch nur den Schluss der Diskussion und nicht den Anfang… Außerdem wusste ich nicht, dass sich die WP bezüglich Typographie noch im Mittelalter befindet. --Debianux 20:51, 19. Jun. 2008 (CEST)
[Bearbeiten] Zehnerpotenzen
Mal was anderes als Tausendertrennzeichen, da ist ja nun wohl eine Lösung erreicht, die nicht jeden glücklich macht, die aber doch die Meisten akzeptieren können, die theoretisch vorzuziehende Variante einer Formatierung durch die Wikipedia-Software ist ja bei Zahlen, anders als bei der benutzerdefinierten Datumsformatierung in der englischen Wikipedia, mangels eindeutiger Erkennungskriterien leider kaum möglich. BTT: Sollten wir uns nicht noch eine Empfehlung zur Schreibweise von Zehnerpotenzen (wissenschaftliche Notation) überlegen, bevor die Schreibweise von Zahlen zum Tipp des Tages ausgwählt wird? Also 12.345.000.000.000.000.000.000.000 als
- 1,2345×1025
- 1,2345·1025
- 1,2345 E+25
Diese Überlegung ist sicherlich primär für einen wissenschaftlich interessierten Personenkreis interessant. Andererseits findet eine Diskussion dieser Frage auf einem so speziellen Forum, wie dem des Wikiprojekts Physik (siehe: Wikipedia:WikiProjekt Physik/Diskussionsforum#Schreibweise von Zahlen) nicht nur die wenigsten der interessierten Benutzer, denn nicht nur Physiker stoßen gelegentlich auf große Zahlen.
Um für diese Überlegung etwas Zeit zu gewinnen verschiebe ich den Tipp zur Schreibweise von Zahlen mal ans Ende der zu listenden Tagestipps, dann erscheint er voraussichtlich in einer Woche als Tipp des Tages auf dem Projektportal, und nicht schon morgen. --SteffenB 12:23, 2. Mai 2004 (CEST)
- Ich bin für Schreibweise 2, weil ich das auch handschriftlich immer so schreibe. Die meisten Leute (zumindest in Deutschland) dürften das so machen. Oder wer kritzelt ein x dahin? Über Schreibweise 3 brauchen wir wohl nicht zu diskutieren. Das ist was für Computer.--El 12:24, 4. Mai 2004 (CEST)
- 2. Natürlich, oder macht das jemand anders? Allerdings ist das richtige Entity ⋅ und nicht · -- Schnargel 02:52, 5. Mai 2004 (CEST)
- Eine ketzerische Frage: Was spricht eigentlich gegen die Computerschreibweise? Nicht umsonst hat sie sich bei Computern durchgesetzt. Auch handschriftlich ist sie am einfachsten, und in Mitschrieben verwende ich sie auch oft, eben weil es schneller & bequemer ist. 2e7 sind drei Zeichen, 2⋅107 sind handschriftlich schon 5, und in LaTeX – 2\cdot10^7 – sind es 10. Und für Exponenten aus mehr als einem Zeichen kommen nochmal zwei für die geschweiften Klammern hinzu. In eigenen Dokumenten verwende ich dafür Makros, aber bei Wikipedia ist das entweder nicht möglich (noch nicht getestet), oder aber in jedem Fall unökonomisch, erstmal mit renewcommand alles umdefinieren. In echtem LaTeX macht man das genau einmal im Header und gut is, in Wiki hilft nur copy&paste bei wiederholten Ausdrücken. Unterm Strich sehe ich nichts, aber auch wirklich gar nichts (abgesehen von der Gewohnheit und dem daraus resultierenden Herdendruck), was gegen die Computerschreibweise spricht. Ich wünschte mir, sie hätte sich längst typografisch durchgesetzt.--SiriusB 18:17, 4. Jul 2004 (CEST)
-
- Dagegen spricht, dass nicht jeder, der Wikipedia benutzt, Programmierer ist, und wer noch nie mit Programmierung zu tun hatte, dem erschließt sich nicht, was diese Darstellung bedeuten soll. Die Schreibweise mit der Potenz erschließt sich immerhin unmittelbar jedem, der weiß, was eine Potenz ist, und das sind signifikant mehr. Das bedeutet auch, dass jemand, der auch damit nichts anfangen kann, leichter jemanden findet, der ihm erklären kann, was das bedeuten soll. --Ce 08:48, 5. Jul 2004 (CEST)
-
-
- Einspruch. Was die hochgestellten Zahlen bedeuten, musste jeder von uns auch erstmal lernen. Ich sehe keinen qualitativen Unterschied, ob man nun hochgestellte Zahlen oder Zahlen mit vorangestelltem "e" als Potenz lernt. Und da die meisten schonmal einen Taschenrechner in der Hand hatten, und diese, bis auf die ganz neuen mit mehrzeiligem Display, AFAIK durchgehend die "e"-Notation benutzen (einige lassen AFAIR sogar das "e" ganz weg), sollte auch hinreichend bekannt sein, dass das "E" für "*10^" steht. Da es aufrecht geschrieben wird, kann es auch nicht mit dem e=2,71828... verwechselt werden, erst recht nicht, wenn man z.B. Großschreibung verlangt, oder statt "e" ein "d" (vgl. Fortran double precision). Es spricht ja nichts dagegen, beide Notationen gelten zu lassen, ebenso wie man 2 auch als 2,0 oder 2⋅100 schreiben kann. Zugegeben, das ist ein Problem, das man eher in einer Newsgruppe diskutieren sollte, weil es allgemein die Typografie und nicht speziell Wikipedia betrifft. Ein möglicher Workaroung wäre z.B. ein Wiki-Makro, mit dem sich Potenzen viel bequemer schreiben lassen. Wiki-TeX-Makros könnte man auch im Mathemodus Makros einbauen. Auch wenn die im Original-LaTeX fehlen, wäre das kein Problem, wenn sie auf der zugehörigen Hilfeseite sauber (etwa in LaTeX-\newcommand-Syntax) deklariert sind, so dass man sie per copy&paste in eigene (Wiki-unabhängige) .tex-Dokumente übernehmen kann. Z.B. ein Befehl \newcommand{\dex}[1]{\cdot10^{#1}} (dex = Dezimal-Exponent), wobei nn der Exponent ist: 2⋅107 = <math>2\dex{7}</math>. Zwar nicht annähernd so schön wie die E-Notation, aber immer noch einfacher, besonders für mehrstellige Exponenten. Neben der Bequemlichkeit käme auch die geringere Vertipperwahrscheinlichkeit dazu, die bekanntlich exponentiell mit der Komplexität des Ausdrucks ansteigt.--SiriusB 13:39, 5. Jul 2004 (CEST)
-
-
-
-
- bin gegen die Verwendung der E-Schreibweise. Das kennen nur Eingeweihte - der Schreibweise mit 10x dürfte wesentlich mehr Menschen im Laufe ihres Schullebens begegnet sein, deshalb bin ich für das Ausschreiben - apropos sdot und middot - bitte noch mal nach unten auf die Seite schauen ... (andere Frage)
-
-
-
-
-
-
- Ich bin dafür, die Schreibweise wenigstens für größere Tabellen zuzulassen. Generell kann ich dem Einwand "kennen nur Eingeweihte" nicht zustimmen, da die Schreibweise bei vielen Taschenrechnern verbreitet ist/war; ich kann mir daher sogar vorstellen, dass die E-Notation sogar mehr Menschen vertraut ist; allerdings ist die 10^-Notation selbsterklärend, das stimmt (setzt aber auch voraus, die Bedeutung hochgestellter Zeichen gelernt zu haben!). Aber wie gesagt, das ist kein Thema speziell in Wikipedia, sondern ein allgemeines. Wenn die E-Notation in den Schulen einheitlich z.B. als technische (neben der mathematischen, derzeit leider weltweit bevorzugten) Schreibweise gelehrt würde, wäre auch der Faktor "unschön" weg, denn "unschön" ist zumeist das, was man nicht gewohnt ist. Von der Ästhetik her finde ich beide Schreibweisen gleich gut, aber die E-Notation ist einfach praktischer, und es gibt wirklich keinen Grund, warum man sie nicht auch z.B. in Fachliteratur verwenden sollte (wurde sie ja auch in früheren Werken, als es mit komfortablen Satzsystemen noch nicht so weit her war). Klar, Wikipedia ist nicht dafür da, die Unzulänglichkeiten des Schulunterrichts auszubügeln, aber zur Allgemeinbildung sollten eigentlich beide Schreibweisen gehören.--SiriusB 16:39, 5. Jul 2004 (CEST)
-
-
-
-
-
-
-
-
- Ich bin eindeutig gegen die Schreibweise mit E (6,9 E+45), und zwar weil:
- weil es absolut unüblich ist. Als ich ein leichtes Programm in der 9. (Bayerisches Gymnasium, Mathematisch-Naturwissenschaftlicher Zweig) Informatik programmierte, war ich total Erschrekt, als mir der Computer 1,006587E+06 (o.s.ä.) anzeigte.
- weil man dann doch gleich statt ein ⋅ einsetzen könnte, das zusätzliche <sup> macht einen Quelltext auch nicht lesbarerer (schlechtes deutsch, ich weiß, mir isch wurscht!).
- weil ich die Potenzschreibweise in der 5. Klasse gelernt habe. Nun gut, es war ein bayerisches PISA-Studien-Sieger Gymnasium, aber ich glaube, dann kann es selbst in HH (oder wer war letzter? Ich weiß es schon nicht mehr) zu ähnlichen Zeiten drankommen. Wer's vergisst ist selbst schuld, genauso wie solch die nach der Schule (oder ab der 8., wo man (zumindest in Bayern) einen Taschenrechner verweden darf) das Kopfrechnen verlernen.
- Und die Schreibweise Nr. 1 fällt ganz aus dem Häuschen, die verwenden nur Engländer (und ehem. englische Kolonien, wie Australien) und solche, die gerade von Auslandsschuljahren dort herkommen (so wie ich). Noch irgendwelche Fragen? -- Ichs Meinung 18:51, 14. Jul 2004 (CEST)
-
-
-
-
-
-
-
-
-
- Noch ein Vorschlag: für die, die nicht Potenzen (besonders so Sachen wie 10-9, = 0,000000001) kennen (negative Exponenten sind dann doch relativ unbekannt), könnte man jede Potenz auf die Seite Potenz (Mathematik) verlinken, also 10-9.
-
-
-
-
-
-
-
-
-
-
- Wie gesagt, ich verstehe die Feindschaft gegenüber der logischen und zweckmäßigen E-Schreibweise nicht. Ich plädiere ja nicht für die exklusive Einführung, sondern für die zusätzliche Zulassung (genauso wie ich übrigens für dafür bin, die neue und die alte Rechtschreibung zuzulassen. Warum soll denn nur eine von beiden richtig sein dürfen?). Aber wie gesagt, das ist eine Grundsatzdiskussion, die sich nicht direkt auf Wikipedia bezieht, sondern auf die gesamte Literatur. Schließlich kann man ja auch sowohl ex als auch expx schreiben – beides ist richtig. Wenn man das E als Operator auffasst, wäre das ja auch kein Problem. Allerdings sollte man dann auf das große E oder auf das Fortran-Double-D bestehen, um jede Verwechslung mit der Zahl e zu vermeiden. Aber wie gesag, was Wikipedia selbst angeht, ist es wohl ein gutes Argument, sich den wissenschaftlichen Gepflogenheiten soweit nötig anzupasse – was aber nicht ausschließen sollte, dass Wikipedia selbst als sprachbildendes Organ an der Evolution der Sprache (allgemein und mathematisch) beteiligt sein kann.--SiriusB 21:16, 21. Aug 2004 (CEST)
-
-
-
-
-
Echt blöd ist doch nur, dass die Funktion #expr: 1.0E-6 dieses Format ausgibt, und weder von dieser Funktion selber akzeptiert wird noch formatiert werden kann. -- visi-on 21:00, 11. Apr. 2007 (CEST)
[Bearbeiten] Dezimaltrennzeichen
[Bearbeiten] Dezimaltrennzeichen
Also, eine Frage meinerseits - bin gerade darüber gestolpert, daß das Dezimaltrennzeichen (also das zwischen dem ganzzahligen und dem gebrochenen Teil einer Zahl (1,5 für anderthalb) in der Schweiz ein Punkt sein soll nach Wikipedia-Information. Wie sieht es da mit Österreich aus? Und dann stimmt der Text hier im Artikel nicht, denn wir haben hier ja keine deutsche Wikipedia, sondern eine deutschsprachige - ich möchte jedoch einen Standard für die ganze Wikipedia haben, wegen mir auch den Punkt als Dezimaltrennzeichen, aber Hauptsache, die Schreibweise zieht sich komplett durch. Sonst kommt man beim Lesen einfach durcheinander (ich bin bei den Chemischen Elementen auf Zahlen gestoßen, die einen Punkt als Tausendertrennzeichen und ebenfalls einen Punkt als Dezimaltrennzeichen hatten - in einer Zahl ...). Wollen wir abstimmen, gibt es konkrete Lösungsvorschläge? -- Schusch 17:37, 4. Jul 2004 (CEST)
- Mein Vorschlag: Ändere die Chemie-Artikel ;-) --DaB. 21:23, 4. Jul 2004 (CEST)
- ja, mache ich auch, und zwar auf das Komma als Dezimaltrennzeichen - mir ging es eher um eine langfristige Lösung ... anscheinend hat auch Österreich als Dezimaltrennzeichen ein Komma, damit sind die Schweizer natürlich deutlich in der Minderheit. Ich würde wie gesagt auch einen Punkt akzeptieren, aber dann eben auch für die ganze deutschsprachige Wikipedia - und da wäre erstens einiges zu ändern und zweitens würde da so mancher jammern -- Schusch 00:16, 5. Jul 2004 (CEST)
- Ich würde die jetzige Regelung (die ich auch so gelernt habe) beibehalten: Punkt aus Tausendertrennzeichen, Komma als Dezimaltrennzeichen. --DaB. 00:31, 5. Jul 2004 (CEST)
- Das Problem ist, dass AFAIK Deutschland und Österreich damit so ziemlich allein auf der Welt sind. Insbesondere im angelsächsischen Raum wird durchweg der Punkt verwendet. Man denke bitte auch an Leute, die Zahlen aus Wiki-Artikeln in Programme übernehmen; ich kenne keine Programmiersprache, die ein Komma als Dezimaltrennzeichen akzeptiert (war nicht ein solcher Tippfehler die Absturzursache der ersten Ariane 5?). Aus Gründen der Internationalität verwenden auch viele deutsche Bücher den Punkt statt des Kommas (z.B. Scheffler/Elsässer).--SiriusB 13:48, 5. Jul 2004 (CEST)
- Ich würde die jetzige Regelung (die ich auch so gelernt habe) beibehalten: Punkt aus Tausendertrennzeichen, Komma als Dezimaltrennzeichen. --DaB. 00:31, 5. Jul 2004 (CEST)
- ja, mache ich auch, und zwar auf das Komma als Dezimaltrennzeichen - mir ging es eher um eine langfristige Lösung ... anscheinend hat auch Österreich als Dezimaltrennzeichen ein Komma, damit sind die Schweizer natürlich deutlich in der Minderheit. Ich würde wie gesagt auch einen Punkt akzeptieren, aber dann eben auch für die ganze deutschsprachige Wikipedia - und da wäre erstens einiges zu ändern und zweitens würde da so mancher jammern -- Schusch 00:16, 5. Jul 2004 (CEST)
-
-
-
- ja, aber die Welt besteht nicht nur aus Programmierern und wir machen hier ein deutschsprachiges Lexikon (für die Allgemeinheit!) ... ich würde gerne ein paar Stimmen sammeln, wer sich vorstellen kann, ob der Punkt als Dezimaltrennzeichen ok ist, oder halt das Komma, und dann müßte das in eine große allgemeine Abstimmung - so wie es jetzt ist, ist es katastrophal - mir sind (mehr als einmal) in einem Artikel beide Schreibweisen begegnet (bei chemischen Elementen genauso wie bei Kochrezepten oder Archtikturartikeln), im Extremfall hatte ich schon so etwas: 3.404.45 kJ/(kg ⋅ m) ... aua! -- Schusch 13:54, 5. Jul 2004 (CEST)
-
-
-
-
-
-
- Das Problem ist: Soll Wikipedia die Abkapselung des deutschen Sprachraumes durch die Bevorzugung einer für den Rest der Welt exotischen Schreibweise noch fördern, obgleich die andere durchaus zulässig ist? Durch eine weltweite Vereinheitlichung könnten viele vermeidbare Fehler vermieden werden. Und zwar nicht nur für Programmierer, sondern auch für den normalen Leser. Es führt nunmal kein Weg an einer Internationalisierung vorbei, und wer – wie ich z.B. – von Klein an auf Komma getrimmt wurde, der liest dann aus englischen Quellen oft um 1000 falsche Werte ab, gerade beim zügigen Lesen. IMHO wird das deutsche Dezimalkomma langsam aber sicher aussterben. Und spätestens dann stehen wir vor einem Sisyphos-Berg an Arbeit...--SiriusB 16:47, 5. Jul 2004 (CEST)
-
-
-
-
-
-
- Hallo, wieso denn gleich so dramatisieren? Abkapselung des deutschen Sprachraumes, Bevorzugung einer für den Rest der Welt exotischen Schreibweise - soweit ich informiert bin, ist nach internationaler Norm (welcher?) neben der Schreibweise des Dezimaltrennzeichens als Komma für den englischsprachigen Raum auch noch der Punkt zugelassen. Und zwar in dieser Reihenfolge ... klar, im wissenschaftlichen und im internationalen Schriftverkehr dominiert das englische, und damit habe ich auch kein Problem - aber ich habe auch kein Problem damit, beim Lesen von englischen Texten umzuschalten und den Punkt als Dezimaltrennzeichen zu erkennen. Wenn du so argumentierst, dann kannst du ja auch gleich inch und °Fahrenheit hier einführen, bloß weil ein gewisser Teil der Welt zu stur ist, die internationalen Normen einzuführen ... war da nicht was mit einer Marssonde (irgendjemand bei der NASA hatte den Umrechnungsfaktor zwischen SI-Einheit und irgendeiner amerikanischen Einheit zu ungenau gewählt ...)? Also, wenn du ernsthaft den Punkt als Dezimaltrennzeichen möchtest, übergebe ich dir hiermit das Zepter und belade dich mit der Aufgabe, dies in der Wikipedia durchzusetzen ... mir ist das zu mühsam, mit zu wenig Erfolgsaussichten versehen, und bisher hat sich sonst niemand über meine Zahlenänderungen beschwert. Nicht vergessen, das betrifft dann auch Angaben in Artikeln wie Rauchen, Schokolade, Heinrich III. oder Buch - also ein bei weitem größerer Teil als die rein wissenschaftlichen Lemmata. Gruß, -- Schusch 18:41, 6. Jul 2004 (CEST)
-
-
Jetzt meld ich mich mal, als Schweizer *g*: In Deutschland wird der Punkt als Tausendertrennzeichen verwendet. Für uns ist dies natürlich höchst verwirrend, da wir diesen als Komma interpretieren. Als Tausendertrennzeichen verwenden wir entweder das Hochkommata (in Wikipedia so durchgezogen) oder einen Zwischenraum, z.B. 347'653.32 / 347 653.32 (für das "deutsche" 347.653,32). Ich weiss, dass bezüglich des Zwischenraums bereits heftige Diskussionen gab, doch IMO wäre dies der einzige Weg, allen gerecht zu sein. Wenn der Zwischenraum durchgesetzt wird, dann ist die Verwendung von Punkt bzw. Komma als Dezimaltrennzeichen nur noch "Nebensache", da es keine Verwirrung mehr gibt, ob der Punkt nun ein Tausendertrennzeichen oder das Dezimaltrennzeichen ist. BTW eine Frage aus Neugier: wenn man auf der deutschen Tastatur im Nummernblock auf das Dezimaltrennzeichen tippt, kommt da ein Komma (,) oder ein Punkt (.) raus? --Filzstift 09:46, 7. Jul 2004 (CEST)
- meinst du nicht, das es ein bißchen schwierig ist, dann schweizer und österreichische oder deutsche Artikel zu unterscheiden? Auch ein Österreicher möchte vielleicht etwas über die Schweiz erfahren ... und würde im Normalfall davon ausgehen, daß im gleichen Buch überall die gleichen Regeln gelten ... aber gut, nicht schön sondern lästig, aber erstmal nicht so dramatisch - ich bleibe nach allem, was auf dieser Seite steht, beim Komma als Dezimaltrennzeichen ... nicht aus Bosheit gegenüber den Schweizern, sondern einfach, da sich keiner bereit erklärt Deutschland und Österreich dem Rest der Welt (alle anderen haben ja einen Punkt als Dezimaltrennzeichen) anzupassen ... ich würde mich umstellen, wenn es denn Konsens wäre, oder jemand die PTB und wen auch immer überredet) - auch übrigens: es kommt ein Komma bei mir ... :-) -- Schusch (PS: Disclaimer: natürlich haben nicht alle anderen den Punkt als Dezimaltrennzeichen - nicht dass das jetzt jemand noch ernst nimmt)
-
- Das würde mich jetzt mal interessieren: Wo, außer deutschsprachigen Raum, ist das Komma sonst noch als Dezimaltrenner üblich? Meines Wissens ist das wirklich ein deutscher bzw. deutsch-österreichischer Sonderweg.--SiriusB 13:06, 7. Jul 2004 (CEST)
-
-
- nö, das machen wir andersrum oder gar nicht - nenne mir mal ein paar Länder außer den USA oder GB (ja, und der Schweiz), wo der Punkt üblich ist ... (ein Beispiel dagegen: Frankreich, guck dir die SI-Broschüre des BIPM an ...) - wie gesagt, irgendwo ist die Ausnahme "Punkt" extra für unsere englischsprechenden Freunde festgehalten, sobald ich wieder herausfinde wo, sage ich Bescheid -- Schusch 13:47, 7. Jul 2004 (CEST)
-
-
-
- Ein paar Datenpunkte: In der französischen Wikipedia scheinen Kommas üblich zu sein (vgl. http://fr.wikipedia.org/wiki/Wikip%C3%A9dia:Conventions_typographiques#Nombres ), und so wie ich die Franzosen einschätze, ist das kleine Anpassung an die deutschen Gepflogenheiten :-) In der spanischen Wikipedia habe ich auf Anhieb eine Zahl mit Komma auf der Hauptseite (es:Portada) gefunden (wo dort, falls überhaupt, die Regeln stehen, habe ich nicht herausgefunden). In der italienischen Wikipedia ist auf der Hauptseite (it:Pagina_principale die Artikelzahl mit Punkt formatiert, was auch ein deutlicher Hinweis ist, dass derselbe nicht auch für das Dezimalzeichen ist, und it:Pi_Greco bestätigt dies. Ok, mehr ausländische Wikipedias habe ich jetzt nicht angeschaut, aber bei einer Stichprobe von drei nichtenglischen Wikipedias dreimal Komma als Dezimaltrenner ist schon recht deutlich (und nein, ich habe die Gepflogenheiten bei keiner der drei Sprachen im Voraus gewusst!) --Ce 14:43, 7. Jul 2004 (CEST)
-
-
-
-
- Kleine Bestandsaufnahme meiner Recherche: (am Bsp. π)
- Schwedisch: 3.14
- Finnisch: 3,14
- Dänisch: 3,14
- Spanisch: 3,14
- Hebräisch: 3.14
- Slowenisch: 3,14
- Niederländisch: 3,14
- Chinesisch: 3,14
- Estisch: 3,14
- Japanisch: 3,14
- Katalanisch: 3.14
- Polnisch:3,14
- Esperanto: 3.14
- Isländisch: 3.14
- Portugisisch: 3,14
- Indonesisch: 3,14
- Koreanisch: 3,14
- Lettisch: 3.14
- Kroatisch: Der Punkt wird für Tausender verwendet, daher kann es nicht 3.14 sein.
-
- In der Hinsicht ist von einem „deutsch-österreichischem Alleingang“ nicht viel zu spüren: sogar die fernöstlichen Sprachen Koreanisch und Indonesisch verwenden das Komma. -- Ichs Meinung 19:35, 14. Jul 2004 (CEST)
- Das überrascht mich allerdings. Zumindest im naturwissenschaftlichen Bereich ist der Dezimalpunkt aber auch im Deutschen üblich, und als Tausendertrenner wird entweder ein kleiner Zwischenraum (\, in LaTeX) oder gleich der Dezimalexponent verwendet (d.h. große Zahlen nicht ausgeschrieben). Und bis auf modernere, wo man auswählen kann, oder ganz alte, die noch mit Dampf oder Fußpedal betrieben werden <g>, haben alle mir bekannten Taschenrechner einen Dezimalpunkt.--SiriusB 15:32, 7. Jul 2004 (CEST)
-
-
-
-
-
-
- Der Vergleich mit dem Taschenrechner hinkt, da eigentlich alle mir bekannten Taschenrechner in Japan, den USA, Korea oder China produziert werden, und diese sind allesamt "Punkt-Länder". Ein alter DDR-Taschenrechner verwendete übrigens ein Komma und ein ' als Tausendertrennzeichen, letztere aber nur vor dem Komma. --RokerHRO 10:22, 22. Dez. 2006 (CET)
-
-
-
-
-
-
- so, ich muß ja zugeben, mich interessiert das Thema ja schon lange, zumal z. B. im Meyers von 1888 die Zahlen mit Dezimalpunkt und als Tausendertrennzeichen mit Kommata (!) versehen sind ... also habe ich jetzt doch mal gewühlt: beim BIPM ist sicherlich folgendes Schriftstück interessant: [3], eine private Homepage zum Thema: [4] und einen Artikel zum Thema habe ich mir auch bestellt ... (Friedrich L. Bauer: Punkt und Komma. In: Informatik Spektrum, 19(2): 93{95, April 1996.) Die (scheinbare?) Dominanz des Punktes kommt halt dadurch, daß die Computer von Beginn an mit den englischsprachigen Gepflogenheiten versehen wurden. So weiteres zu einem späteren Zeitpunkt :-) -- Schusch 15:29, 7. Jul 2004 (CEST)
-
-
-
-
-
-
- eine kleine Recherche ergab einen Artikel Dezimaltrennzeichen - alles spricht ja eigentlich für den Punkt :-) -- Schusch 14:37, 26. Jul 2004 (CEST)
-
-
-
[Bearbeiten] Punkt oder Komma (ja wieder dieses Thema)
Bezüglich [5] --> Ich werde mich mal schlau machen --Filzstift ✑ 13:46, 13. Sep 2005 (CEST)
- Hey du! Vielleicht hast du Recht mit deiner Behauptung. Aber solange es nicht beweisbar ist, könnte jeder damit kommen und dies behaupten. Wenn es der Fall wäre, dass in der CH generell Kommas verwendet wird, dann wird es sicher irgendwo so amtlich festgelegt sein. Wenn du nämlich genau weisst, dass Kommas verwendet wird, dann wirst du sicher auch wissen, wo dies definiert ist!!! Ein Hinweis auf "Zeitungen" bringt nicht viel, da jede Zeitung manchmal ihr eigenes Regelwerk definiert (z.B. die NZZ benützt "placieren" statt "platzieren"). Das einzige, Was du bisher angezettelt hast ist ein Editwar. --Filzstift ✑ 07:28, 14. Sep 2005 (CEST)
- hmm, normierte festlegungen, wie z.b. vom DIN werden doch in der wikipedia fuer deutschland auch nicht als massgebend bzgl. der zifferngruppierung angesehen (siehe lange diskussionen weiter oben). wenn nun in der schweiz festgelegt worden waere, dass man leerzeichen zur zifferngruppierung nutzen solle, dann wuerde es doch jene festlegung auch wieder nicht beruecktsichtigt werden. (ja, ich weiss, es geht um bruchtrennung und nicht um zifferngruppierung, aber beides kann man unter den themenhut der normung stecken.)
- somit ist die angabe von zeitungen evtl. doch besser als die angabe eines amtlichen regelwerkes? ;-) --seth 10:19, 14. Sep 2005 (CEST)
Filzstift, deine Haltung ist etwas inkonsequent: Du forderst, dass eine Behauptung irgendwo gesetzlich gedeckt sein müsse - aber für den von dir verfochtenen Gebrauch genügt dir der Verweis auf die "bewährte" Praxis der Wikipedia. Auch die in der Schweiz nicht übliche Verwendung des "ß" ist ja nicht durch eine Verordnung so festgeschrieben, sondern hat sich einfach so als Praxis etabliert. Wir leben ja nicht in einem Staat, in dem alles verboten ist, was nicht irgendwo gesetzlich als erlaubt erklärt worden ist, sondern in einem Staat, in dem das erlaubt ist, was nicht ausdrücklich als verboten erlärt ist. Das ist ein wichtiger Unterschied und es wäre wünschenswert, wenn in der Wikipedia nicht das gegenteilige Prinzip eingerichtet würde.
Auch die Durchsicht der mir gerade zur Verfügung stehenden Schweizer Publikationen - nicht nur von Zeitungen - ergibt das bekannte Bild: es heißt meistens "15,3 %", aber nicht "15.3 %" und statt des Hochkommas kommen ja auch Leerschläge vor (vielleicht eine Praxis, die sich mit der Einführung des "non-breaking space" noch verbreitet hat, jetzt, wo man keine Angst mehr zu haben braucht, dass es einem eine Zahl im Umbruch zerreißt).
Und: für einen Editwar braucht es immer zwei! Wie wirst du es hinkünftig mit Zahlenangaben in CH-spezifischen Artikeln halten? --Seidl 16:26, 14. Sep 2005 (CEST)
- Wie ich es mache, hängt primär davon ab, was hier die übliche Praxis ist bzw. sein wird. Wenn alles beim bestehenden bleibt, dann bleib ich auch dabei. Wenn künftig das Komma als Dezimaltrennzeichen eingesetzt werden soll, dann wäre es für mich auch Ok. Jedenfalls habe ich mal bei der Duden-Sprachberatung angeklopft. Warte noch gespannt auf dessen Antwort (bisher gab es erst ein E-Mail-Hin und Her, bis ich als Gehörloser endlich durchkam; die bieten es nämlich nur telefonisch für über 3 Fr/min an. Ich "durfte" jetzt endlich meine Frage via Mail mitteilen).
- Zum Inkonsequenz-Vorwurf: Mich stört es einfach, dass "bewährtes" einfach ohne Diskussion plötzlich abgeändert werden soll. Daher reagierte ich etwas heftig. Ich sagte aber *nicht*, dass die Verwendung eines Kommas falsch wäre... Mich interessiert persönlich auch, ob es irgendwo festgelegt ist (in D ist es in einer DIN-Norm definiert). Okay? ;)
- Beim Thema Hochkommata/geschütztes Leerzeichen will ich mich nicht einmischen. Meine persönliche Meinung: Ich bevorzuge das , aber viele wären damit überfordert (und du siehst: da gebe ich mich klein bei *g*; bin aber froh, das als Tausendertrennzeichen nicht der Punkt oder das Komma verwendet wird). --Filzstift ✑ 08:00, 15. Sep 2005 (CEST)
-
- ich möchte an der Stelle mal Filzstift recht geben - der „oberschlaue“ Ton desjenigen, der da geändert hat, und hinterher der Verweis auf Zeitungen als maßgebliche Instanz, ist für mich auch eher ein Zeichen dafür, dass da ein Selbstvernarrter agiert. Ansonsten hätter er sich wohl etwas mehr Zeit dafür genommen, die Änderung mal nachvollziehbar zu begründen - bisher habe ich (als zugegeben Außenstehender) nichts gelesen, was mich überzeugen würde. Grüße, -- Schusch 10:24, 15. Sep 2005 (CEST)
[Bearbeiten] Antwort vom Duden-Verlag
______schnipp______
Sehr geehrter Herr xyz,
als Antwort auf Ihre Frage möchten wir gern aus dem Titel "Richtiges Deutsch" von Walter Heuer, Max Flückinger u. Peter Gallmann (23. Aufl., 1997) zitieren. Dort heißt es: "Dezimalstelen werden im deutschen Sprachraum mit dem Dezimalkomma getrennt. Abweichend von dieser Regel, wird in der Schweiz bei Währungsbeträgen meist der Dezimalpunkt gewählt. Sonst wird der Punkt (oder der Doppelpunkt) nur zur Abtrennung nichtdezimaler Untereinheiten gebraucht." Es folgen einige Beispiele, die dies verdeutlichen: "Bei dezimalen Untereinheiten: 4,35 m; 0,3 t; DM 48,25. Aber: Fr. 48.25. Bei nichtdezimalen Untereinheiten: Der Schnellzug fährt um 7.38 Uhr. Er gewann mit 6.48,59 min (üblicher: mit 6:48,59 min)."
Diese Aussage bestätigen auch andere Autoren, z. B. Max Sager und Georges Thiriet in "Regeln für das Maschinen- und Computerschreiben" (16. Aufl., 1997). Dort wird allerdings präzisiert, dass nur in der deutschen Schweiz der Punkt als Dezimalzeichen bei Währungsbeträgen bevorzugt wird, in der französischen Schweiz jedoch das Komma üblich ist.
Es handelt sich bei der Gestaltung des Dezimalzeichens in der Schweiz offenbar um eine Konvention, die allgemein befolgt wird, aber nirgends verbindlich festgelegt ist.
Wir hoffen, Ihre Anfrage damit ausreichend beantwortet zu haben und verbleiben
mit freundlichen Grüßen aus Mannheim xxx yyy
______schnapp______
Die Feststellungen von einigen euerseits stimmen also mit der Antwort des Dudens überein. Ein gaaaaanz anderes Theme ist, wie dies in der WP nun praktiziert werden soll? --Filzstift ✑ 15:37, 15. Sep 2005 (CEST)
[Bearbeiten] Dezimaltrennzeichen in der Schweiz Punkt oder Komma?
Hier steht:
- "In Artikeln mit Bezug zur Schweiz oder zu Liechtenstein ... Punkt als Dezimaltrennzeichen ... 34'034.9 Birnen ... Siehe auch: Schreibweise Schweiz"
Dort steht:
- "Als Dezimaltrennzeichen wird das Komma verwendet. Eine Ausnahme bilden Währungsbeträge: Franken und Rappen werden in der Schweiz durch einen Punkt getrennt."
Was nun? Seit wann sind Birnen eine Währung? --androl 20:07, 28. Jul 2006 (CEST)
- Ich habe mich mal etwas durch die grossen schweizer Zeitungen (NZZ, Blick, Tagesanzeiger, Mittellandzeitung, BAZ) und auch einen Verlag (Orell Füssli) gesucht, Google ist da hilfreich. Wenn man davon ausgeht, dass die genannten Vertreter von Printerzeugnissen sich an die geltenden Regeln halten, schreibt man in der Schweiz, wie in Deutschland, ein "," anstatt eines "." (Bsp: 120,34). Ausnahmen sind, wie verschiedentlich erwähnt, die Währung (1.20 CHF, neu ohne Punkt beim Währungszeichen) und Zahlen in Tabellen (Börsenkurse und ähnliches).
- Wo's dann aber interessant wird, ist bei den Tausendertrennzeichen, da herrscht das grosse pressefreiheitliche Chaos. Im Blick findet man alles (100'000, 100 000 und 100000), teilweise im selben Artikel. Und bei den anderen sieht es auch nicht viel besser aus (mindestens zwei der drei Varianten). Sogar die NZZ, mit einem Heer von Lektoren, ist nur in der englischen Ausgabe konsequent (100 000), in der deutschen Version findet man beide anderen Versionen (100'000 und 100000).
- Deshalb denke ich, wir sollten uns hier nicht zu fest versteiffen und keine Ressourcen verschwenden mit stundenlangem Zahlenumformatieren (was ich selber schon gemacht habe :-). Aber da die Schreibweise mit dem Komma als Dezimaltrennzeichen in der Schweiz anscheinend immer noch gilt, müsste das zumindest auf dieser Seite richtiggestellt werden. Und bei den Tausendertrennzeichen würde ich bei den schweizer Seiten nicht auf das Apostroph verzichten, dann gibt es keine Probleme mit Zeilenumbrüchen und der Punkt ist ja für Schweizer gar nicht geläufig. --Lukas Derendinger 09:52, 14. Nov. 2006 (CET)
Ich bin nicht dieser Ansicht. Wichtiger als die Printmedien ist doch, was in der Schule gelehrt wird. Und mindestens seit 1960, aber vermutlich noch viel weiter zurück, wird in der Schule der Dezimalpunkt unterrichtet. --Pelinot 15:35, 12. Feb. 2007 (CET)
- Welche Schule? Meine Schule in Deutschland hat mir 123.456,12 beigebracht. --Lutz 12:09, 21. Mär. 2008 (CET)
- Was an deutschen Schulen unterrichtet wurde/wird interessiert in der Schweiz nicht vv.
- Fakt Jahrzehnte wurde in der Schweiz der Dezimalpunkt gelehrt. Das Problem ist, dass diverse Länder Punkt oder Komma als Tausendertrenner verwendeten. Und insbesondere deutsche Schulabgänger an dieser Unsitte weiterhin festhalten. -- visi-on 18:45, 31. Mär. 2008 (CEST)
- Ausser bei Währungsangaben habe ich in der Schweiz noch nie einen Dezimalpunkt gesehn. Lukas hat bereits darauf verwiesen, dass alle grossen Schweizer Zeitungen es so halten und der Duden bestätigt es auch. Wenn niemand Belege für das Gegenteil liefern kann, sollten wir das im Artikel richtigstellen. --oreg 04:27, 16. Mai 2008 (CEST)
Da alle o.g. Quellen und auch der Wikipediaartikel über das Dezimaltrennzeichen bestätigen, dass in der Schweiz nur bei Währungen der Dezimalpunkt benutzt wird und sonst das Komma, werde ich den Artikel jetzt mal korrigieren. Hier noch eine Diskussion mit einer Bestätigung der Schweizer Bundeskanzlei Zentrale Sprachdienste für das Dezimalkomma: Diskussion:Schreibweise von Zahlen#Schweiz. Falls jemand doch noch eine gegenteilige Quelle findet, bitte hier melden. --oreg 19:24, 26. Mai 2008 (CEST)
- Welche Quellen belegen was? Dass neuerdings nur noch bei währungsbehafteten Zahlen ein Punkt geschrieben werden soll mag zwar neue Regel sein. Ist aber beim Schreibvolk noch nicht angekommen. Der Leitfaden zur deutschen Rechtschreibung 2008 schweigt sich zu diesem Thema aus. -- visi-on 19:51, 26. Mai 2008 (CEST)
- Siehe oben: Die grossen Schweizer Zeitungen und Verlage halten es so und die Bundeskanzlei Zentrale Sprachdienste hat es auf Anfrage bestätigt. Und das ist schon seit vielen Jahren so. Gegenteilige Quellen hat bisher niemand gefunden. Danke für den interessanten Link! --oreg 20:07, 26. Mai 2008 (CEST)
-
ich sehe auf dieser Tafel (Eigentum des Bundesbetriebs SBB) kein Komma ... das ist die bittere Realität. -- visi-on 20:30, 26. Mai 2008 (CEST)

- Bitter? Naja... ;-) Das ist immerhin mal ein Indiz. Ob es eine SBB-Dienstanweisung gibt, dass das konsequent so gehandhabt wird? Stärker wäre aber wohl wirklich eine Quelle von "Sprachprofis" wie die o.g., vielleicht auch Schulrichtlinien. En Gruess, --oreg 20:59, 26. Mai 2008 (CEST)
-
- Siehe oben: Die grossen Schweizer Zeitungen und Verlage halten es so und die Bundeskanzlei Zentrale Sprachdienste hat es auf Anfrage bestätigt. Und das ist schon seit vielen Jahren so. Gegenteilige Quellen hat bisher niemand gefunden. Danke für den interessanten Link! --oreg 20:07, 26. Mai 2008 (CEST)
Hier ist eine wirklich hochoffizielle Quelle: die "Weisungen der Bundeskanzlei zur Schreibung und zu Formulierungen in den deutschsprachigen amtlichen Texten des Bundes" vom 11. Februar 2008. Dort heisst es:
„Dezimalstellen werden durch das Dezimalkomma abgetrennt. Bei Geldbeträgen ist zwischen der Währungseinheit und der Untereinheit anstelle des Dezimalkommas der Dezimalpunkt zu setzen.“
– Schreibweisungen, Seite 80, Abschnitt 5.1.3, §514
--oreg 19:36, 27. Mai 2008 (CEST)
[Bearbeiten] malpunkt, cdot/middot/...
[Bearbeiten] cdot ist sdot oder middot?
Ja, die Frage auch hier nochmal: wird das \cdot von TeX in html dargestellt durch ⋅ oder · - und wenn wir schon dabei sind, sollte man auch gleich die Lage für Unicode klären. Insbesondere für Fälle wie: 12 ⋅ 1035 sollte das klargestellt werden; Gruß, -- Schusch 13:55, 5. Jul 2004 (CEST)
- sdot wird bei manchen Rechnern (Windows 2000 Professional, IE 5.5 - disclaimer: ich habe auf die Installation keinen Einfluss!) nicht dargestellt (leeres Rechteck), middot aber schon. Da sdot als dot operator tituliert ist, bei Zahlen aber genaugenommen kein exklusiver dot operator, sondern ein einfacher mittlerer Malpunkt vorhanden ist und cdot auch nur "centered dot heisst" (glaub ich jedenfalls), würde ich's bei middot (als middle dot tituliert) belassen. Folgendes hab ich gefunden:
-
- Tex: cdot - centered dot
- HTML-Entity: middot - middle dot (Georgian comma, Greek middle dot)
- HTML-Entity: sdot - dot operator
- also middot=cdot wg. centered dot=middledot. lg --Hubi 14:28, 5. Jul 2004 (CEST)
- so, jetzt - das Zeichen ist ja ein Operator, oder? Von daher wäre sdot eigentlich wohl eher das richtige Zeichen ...
- eine kleine irc-chat umfrage ergab folgendes Ergebnis (middot wurde immer angezeigt) (wer noch einen weiteren Fall hat, mag den ergänzen):
- sdot wird angezeigt:
- win xp + mozilla: sdot geht
- win xp + firefox: sdot geht
- win 9x + firefox: sdot geht
- linux + firefox 0.8: sdot geht
- linux + mozilla 1.5: sdot geht
- sdot wird nicht angezeigt:
- linux + konqueror: rechteck
- win xp + internet explorer: sdot
geht nichtgeht, wenn man Arial Unicode MS hat (Vielleicht liegt's aber doch an was anderem?) -- Ichs Meinung - win 9x + opera 7.5: sdot geht nicht
- sdot wird angezeigt:
- sdot und middot sind auf Wikipedia:Sonderzeichen zu finden - hier noch ein Vergleich:
- mit sdot: 12 ⋅ 1035
- mit middot: 12 · 1035
- math mit \cdot:

- die für mich optisch schönere Variante ist das/der sdot, vom Sinn her (mathematischer Operator) dürfte sdot auch richtiger sein - aber von der Kompatibilität sieht es ja eher besser für die middot-Variante aus ... -- Schusch 15:47, 5. Jul 2004 (CEST)

nachgetragen, so sieht es bei mir aus (meine Tabellenkenntnisse sind minimal, sorry) -- Schusch 17:06, 7. Jul 2004 (CEST) |
Die Frage ist hier eindeutig beantwortet W3C. Da kann man irgendwie nicht dran rütteln. Und was einzelne Programme machen ist mir eigentlich egal. Die Programme haben sich an dem W3C zu richten und nicht umgekehrt. IMHO liegt es ohnehin nur an der gewählten Schriftart?! --Paddy 16:20, 5. Jul 2004 (CEST)
- So wie sich auch alle Webseiten und alle Browser an die Vorgaben des w3c halten, und das seit jeher. Vor allem können die auch alle MathML, worauf du referenzierst. Oder irre ich mich da vielleicht. Und ich dachte immer, dass wir Informationen sammeln und verbreiten wollen. Und die PDAs und Kleinrechner können natürlich auch alle den vollen Unicode-Zeichensatz. Das Mathe-Zeichengestoppel mit HTML-Entities ist mMn sowieso ganz fürchterlich. Nichts für ungut, aber ich kann Aussagen wie "die Programme müssen's richten" irgendwie nicht ab. Insgesamt geht es doch nur um simple Zahlen, die lesbar dargestellt werden sollen. --Hubi 16:54, 5. Jul 2004 (CEST)
- Ob sdot die optisch schönere Variante (in welchem Zeichensatz?) ist, kann ich von hier aus nicht beurteilen, da sdot -leider leider- nicht angezeigt wird. --Hubi 16:54, 5. Jul 2004 (CEST)
- PS: Immerhin ist middot Bestandteil des ISO 8859-1 (Latin-1) Zeichensatzes, der meines Wissens schon sehr lange (seit Mitte der 1980er) Grundlage für westeuropäische X-Windows und M$Windows-Zeichensätze darstellt. Dass middot überall geht, ist also kein Wunder. --Hubi 17:05, 5. Jul 2004 (CEST)
Also sollen wir es falsch machen? Ist das Deine Forderung? --Paddy 17:25, 5. Jul 2004 (CEST)
-
- Zunächst einmal: ich fordere hier gar nichts. Ich bin lediglich für eine pragmatischere Sichtweise. Dann bewegen wir uns meiner Meinung nach nicht auf dem Terrain der Formatierung von mathematischen Formeln (MathML), sondern befassen uns mit der Schreibweise von Zahlen. Schließlich war die ursprüngliche Diskussion, ob TeXs cdot eher HMTLs middot oder sdot entspräche, was ich eindeutig mit middot gleichsetzen würde, siehe oben. Wenn TeX schon keinen dot operator mitbringt, brauchen wir in einfachen (!) Zahlen auch keinen. Endlich geht es hier nicht die Wahl zwischen falsch oder richtig, sondern um eine Festlegung, was mittel- bis langfristig als Konsens bei der Schreibweise von Zahlen empfohlen werden soll, und da bin ich nun mal für middot, unter anderem, weil das blöde W2000 hier sdot nicht darstellt. Eins noch: Wer braucht denn die ganzen anderen Mathe-HTML-Entity-Zeichen? Niemand, daher wird es auch in Zukunft viele Zeichensätze/Rechner geben, die dies nicht unterstützen werden.
-
- Also, sollen wir es falsch machen? Nein, natürlich nicht. Aber ich glaube einfach, dass sdot aus den genannten Gründen die falsche Alternative ist. Grüsse --Hubi 17:44, 5. Jul 2004 (CEST)
- nun polemisier mal nicht so Paddy :-) wir haben ja auch offiziell Punkte als Tausendertrennzeichen - ist ja auch nicht ganz korrekt ... Hubi, eigentlich ist es ja nicht korrekt, aber ich könnte mit dieser Variante leben (genauso wie mit einem Punkt als Dezimaltrennzeichen), aber das sollte dann auch mal schriftlich festgehalten werden - könnt ihr noch mal ein bißchen rumfragen, wer sich noch so dazu äußern möchte? Und wenn keine weiteren Argumente mehr kommen, machen wir vielleicht in einer Woche 'ne ordentliche Abstimmung? -- Schusch 17:46, 5. Jul 2004 (CEST)
-
- Meinst du jetzt typographisch korrekt, oder auszeichnungsmäßig korrekt? Irgendwie erschließt sich mir nicht ganz der Nutzen, wenn man für einfache Zahlen ein relativ exotisches Zeichen verwenden will bzw. soll. Typographie und HTML sind meines Erachtens zwei Welten. Und soll ich jetzt auch − (Zeichen-Nummer 8722) statt des einfachen Minuszeichens verwenden. Die Beschreibung ist hier minus sign, aber ist das jetzt ein Vorzeichenminus oder ein Subtraktionsminus oder beides? Das wird typographisch meines Wissens nach unterschieden, ich sollte mich also entscheiden. Aber ASCII besitzt doch schon ein Minuszeichen, genauso wie Latin-1 ein Malzeichen (middot) hat. Die MathML-Quelle lass ich nicht gelten. Wieso kann ich in normalen Texten nicht die normalen Zeichen verwenden? Das versteh ich noch nicht so ganz. Vielleicht könnt ihr mich ja mal noch etwas erleuchten :-) --Hubi 18:23, 5. Jul 2004 (CEST)
-
-
- hallo Hubi - hm ... das du es aber auch immer so genau nehmen mußt :-)
-
-
-
-
- zum cdot ist sdot oder middot - ich vermute mal, daß cdot eher dem sdot entspricht - das (der?) middot hat (bei meinem Zeichensatz hier (dürfte b&h-lucida-iso8859-15 sein) beim middot rechts und links wesentlich mehr Platz als das sdot, zusätzlich ist der Punkt größer. Von daher vermute ich eher auf das sdot als ähnliches Zeichen, weil es sich eben auch eher wie ein cdot verhält. Deine Quelle, die du anführst (Georgisches Komma und Griechischer Mittelpunkt?) scheint zu bestätigen, das es sich dort um Zeichen aus dem normalen Schriftsatz handelt, aber ich kenne mich weder im georgischen noch im griechischen aus ...
-
-
-
-
-
- zur Typographie - ich sag mal so: ich bin wohl etwas leichtfertig mit den Begriffen umgegangen :-) Natürlich haben wir hier schon eine Menge Kompromisse und mir macht ein weiterer auch nichts aus
-
-
-
-
-
- zum eigentlichen Thema, nämlich: was nehmen wir? - ich würde lieber sdot nehmen, da dort der Abstand links und rechts vom Punkt nicht so groß ist und ich, wie eigentlich üblich, ohne das es riesig aussieht, noch ein Leerzeichen rechts und links des Operators unterbringen kann; beim middot werden einige wieder kommen und jammern, daß es mit den Leerzeichen ganz grausam aussieht - aber die gehören nun mal um die Operatoren drumherum (5 = 2 + 3 und nicht 5=2+3) ... deswegen hätte ich das gerne von mehreren Menschen begutachtet und abgesegnet (ein Königreich für die Umstellung auf Unicode, oder wird es dann auch nicht besser?) - und dann setzen wir das auf die Artikelseite und es gibt zumindest eine Regel ... ich denke auch, daß man die typographischen Feinheiten auch auf einen Zeitpunkt in drei, vier oder fünf Jahren verschieben kann - jetzt muß es erstmal funktionieren, im Rahmen des funktionierenden möglichst korrekt sein, und evtl. in Hinsicht auf spätere Änderungen möglichst eindeutig sein, um Änderungen evtl. später durchführen zu können.
-
-
-
-
-
- und wofür würde ich stimmen: wenn denn sdot mit Windows wirklich nicht geht, so würde ich für middot stimmen - wenn dafür so eine Art Mehrheit zustande kommt, habe ich auch eine Verweismöglichkeit, wenn jemand jammert, daß der middot eine typographische Katastrophe ist ...
-
-
-
-
-
- noch als Info: ich habe die Frage hier an mehreren Stellen hinterlassen (versuche aber, alles auf diese Seite hier umzubiegen) - schau mal auf Wikipedia Diskussion:WikiProjekt Physik#cdot - sdot oder middot, dort hat SteffenB noch eine interessante Info hinterlassen
- lieber Gruß, -- Schusch 00:02, 6. Jul 2004 (CEST)
-
-
-
- Nur noch ein paar Anmerkungen:
- Webformatierung ist für mich wie eine Art Schreibmaschine. Moderne Maschinen können Proportionalschrift und Blocksatz. Für den Buchdruck fehlt aber noch sehr viel (Ligaturen, Silbentrennung usw.)
- Neulich haben wir eine Art Kugelkopfschreibmaschine bekommen, mit neuen Zeichensätzen (Unicode). Auch ein mathematischer Zeichensatz mit vielen Extrazeichen wie Σ ist dabei. Allerdings ist das nur ein Notbehelf, mathematischen Formelsatz kann man damit nicht machen, das sieht so aus: Σi=1n i2. Nicht grade das, was ich will. Aber dafür haben wir ja schon TeX.
- MathML ist neu in nicht sehr verbreitet und auch nur eine XML-Variante von TeX.
- Zahlen sind keine Formeln, auch wenn sie in wissenschaftlicher Darstellung auftreten. Sonst würde man sie ja tendenziell in TeX formatieren. Im Fließtext kann man sie aber normal formatieren.
- In wissenschaftlicher Darstellung braucht man für Zahlen einen Malpunkt. Eigentlich kein Problem, denn der Standardzeichensatz (Latin-1) hat den ja, nur auf der PC-Tastatur ist er nicht vorhanden. Aber über · kriegt man den ohne weiteres. Dann kann man also Zahlen wie 5·1023 schreiben. Das ist schön.
- In Formeln soll man aber nach neuesten Definitionen (MathML), die im Prinzip noch nirgends verfügbar sind, einen dot operator verwenden, der angeblich das Malzeichen darstellen soll, obwohl das doch eigentlich einfach multiplication sign und nicht hochgestochen dot operator heißt. Aber Zahlen sind keine Formeln, siehe oben. Vielleicht als doch das einfache Malzeichen (middot)?
- Leider ist der neue dot operator nicht überall vorhanden, zum Beipiel nicht unter Windows2000/XP und Internet Explorer (nicht die seltenste Kombination) und auch nicht unter Linux/Konqueror. Jedoch auch nicht auf PDAs etc. Dort sieht's dann so aus 5ࢮ1023. Die Software soll's richten, aber ob die Hersteller das hören. Und auf Rechnern, die mir nicht gehören, kann ich doch auch nicht einfach Mozilla installieren?
- Also werd ich in Zukunft wegen einer einfachen Zahl jedesmal den Kugelkopf (Zeichensatz) austauschen müssen, nur um einen blöden sdot-Klecks zu erzeugen, wo doch der middot-Klecks schon auf meinem normalen Kugelkopf...? Das ist aber unpraktisch. Der Malpunkt erscheint bei "meinen" Rechnern (größtenteils IE oder Konqueror) eh nicht, ich muss also warten, bis Micro$oft ein Einsehen hat und der Eigentümer dieses Schei..-Windows-PCs sich endlich bequemt, seine veraltete Software upzugraden und neue Kugelköpfe einzubinden. Auf Linux kann ich ja einen Extrabrowser (Mozilla) verwenden, obwohl ich doch sonst fast alles mit Konqueror mache. Und die PDA-Hersteller könnten auch mal endlich ihre Zeichensätze auf volle Unicode-Unterstützung aufbohren, damit wenigstens der Malpunkt funktioniert. Leider wird dann auf meinen 128 MB im PDA kein Platz mehr für Wikipedia sein, da ja der Speicher für die Zeichensätze gebraucht wird.
- Nur noch ein paar Anmerkungen:
-
- Obwohl die Tendenz nach sdot zu gehen scheint, bin ich nach wie vor für middot und - pfui pfui - halte das nicht einmal für einen Fehler. --Hubi 08:33, 6. Jul 2004 (CEST)
-
-
- nein Hubi, ich habe wirklich keine Probleme mit dem Kompromiss, ich ändere die chemischen Elemente nach einem Aussetzer von zwei oder drei jetzt wieder mit middot :-) ... lassen wir das mal ein paar Tage so stehen, und da ja offensichtlich nur minimalstes Interesse an dem Thema besteht, werden wir vielleicht auch ohne so eine Pseudoabstimmung eine Empfehlung für den middot formulieren - wie gesagt, für mich kein Beinbruch - und den IE verwenden ja doch ziemlich viele (ca. 65 % im Juni, wenn die Statistik [7] stimmt) ... -- Schusch 11:45, 6. Jul 2004 (CEST)
-
-
- nur dass ich es nicht als Kompromiss sehen würde. lg --Hubi 11:55, 6. Jul 2004 (CEST)
-
-
- Bin auch der Ansicht, dass wir die Kröte middot schlucken sollten. Sehr ärgerlich mal wieder, aber offizielle und im Prinzip sinnvolle Regeln durchzuboxen und dabei in Kauf zu nehmen, dass über die Hälfte der Leser eine Fehlanzeige habe, finde ich noch weniger akzeptabel. Wenn demnächst MS pleite geht, weil alle auf Linux umsteigen, können wir ja noch mal drüber reden ;-). Oben wird als Nachteil von middot aufgeführt, dass es Leerraum links und rechts davon gäbe. Verstehe ich nicht. Sehe keinen. --Wolfgangbeyer 12:36, 6. Jul 2004 (CEST)
- Jedenfalls nicht bei win98+IE5.5 (sorry) und 2·103. sdot liefert ein Quadrat. --Wolfgangbeyer 13:12, 6. Jul 2004 (CEST)
-
-
-
-
- Mozilla 1.6 [Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.6) Gecko/20040122 Debian/1.6-1] stellt den sdot ein wenig fetter dar, amsonsten siehe ich keinen Unterschied, auch nicht im Abstand links/rechts. Nun finde ich den etwas fetteren Punkt zwar in der Tat etwas schöner, aber das rechtfertigt m.E. nicht eine Inkompatibilität mit verbreiteten Browsern (inklusive dem verbreitetsten Browser überhaupt!) --Ce 17:00, 6. Jul 2004 (CEST)
-
-
-
-
-
- Mein IE mit MS xp (Schande über mich, ich unterstütze die noch...) stellt ⋅ auch nur ein wenig fetter dar, von „größerem Abstand“ sehe ich nix. Vielleicht sind's aber auch meine 16 Jahre alten, perfekten Augen (Dass sie perfekt sind, ist kein Scherz!). -- Ichs Meinung 16:05, 7. Jul 2004 (CEST)
-
-
-
-
-
-
- hab mal oben einen Screenshot gemacht für deine scharfen Augen :-) kommt wohl auf die Schrift an ... -- Schusch 17:06, 7. Jul 2004 (CEST)
-
-
-
[Bearbeiten] Sichtbarkeitstabelle
Also wer sieht jetzt eigentlich was? Hier die 3 relevanten Varianten:
- ⋅: 8⋅806
- ·: 8·806
- ×: 8×806
Bitte in dieser Reihenfolge in jeweils ein Feld untereinander eintragen, bzw. Tabelle erweitern:
| Linux | Mac OS X | Win9x | WinNT | Win2k | WinXP | Sun OS uraltversion | |
|---|---|---|---|---|---|---|---|
| Mozilla 1.4a | Ok Ok ?%-Kreuz |
||||||
| Mozilla 1.5 | Ok (dünner, rund) Ok (fetter, eckig) 50%-Kreuz (alle:Lucida) |
||||||
| Mozilla 1.6 | Ok Ok (etwas dünner) 65%-Kreuz |
Relativ klein Ok 50%-Kreuz |
|||||
| FireFox 0.9 | Punkt mit breitem Abstand Punkt mit kaum Abstand 50%-Kreuz |
Punkt mit wenig Abstand Punkt mit normalen Abstand Kreuz(mehr links als rechts) |
|||||
| Firefox 1.0.7 | Punkt, mittig, mit wenig Abstand (thin-space-mäßig) Punkt, mittig, „ohne“ Abstand (d. h. 2 px Abstand) Kreuz, mittig, „ohne“ Abstand (alle drei mit 8-8) |
||||||
| Opera 7.5 | kleinerer Punkt grösser (!) Punkt 60%-Kreuz |
||||||
| Konqueror/ Safari |
Quadrat Stern (*) 50%-Kreuz |
kleiner Punkt ok 50%-Kreuz |
|||||
| IE 5.5 | ok ok 80%-Kreuz (IE 5.2) |
Quadrat ok 50%-Kreuz |
ok zu fetter Punkt 80%-Kreuz |
Quadrat ok 50%-Kreuz |
|||
| IE 6.0 | Quadrat ok 50%-Kreuz |
ok 50%-Kreuz |
80%-Kreuz bedeutet, dass es 80% der Höhe einer Ziffer einnimmt. 50%- und 80%-Kreuze finde ich ok. --Wolfgangbeyer 17:26, 7. Jul 2004 (CEST)
- Kreuz (gleich welcher Größe) finde ich nicht so gut, wenn schon ein funktionierender Punkt existiert. --Ce 17:55, 7. Jul 2004 (CEST)
Ich weiß ja nicht ob es wichtig ist, aber im Mozilla Firefox 0.9.1 wird ⋅ (sdot) als Kreis und · (middot) als Quadrat dargestellt. Natürlich fällt das nicht bei normaler Schriftgröße auf, aber bei 5-mal strg++ sieht man diesen Unterschied. Jetzt gibt es nun auch in dieser Hinsicht die Frage, was den schöner aussieht. Ich find's runder schöner, da ich auch beim Schreiben selten einen Punkt in der Form eines winzigen Quadrats erzeuge. ;-) --Blaite 18:28, 7. Jul 2004 (CEST)
- Also, ich mußte die Vergrößerung ziemlich stark hinaufdrehen, um im Mozilla 1.6 überhaupt einen Unterschied zu sehen, aber hier ist middot rund und sdot eckig. --Ce 15:34, 8. Jul 2004 (CEST)
-
- ich weiß nicht, ob das so funktioniert ... die Aussehen der Zeichen werden ja nicht vom Browser und nicht vom Betriebssystem, sondern vom Schriftsatz festgelegt (bei mir zur Zeit Lucida) - wenn also weder Browser noch Betriebssystem prinzipielle Probleme haben, und das nehme ich für alle neueren Varianten mal großzügig an, so ist dass Problem (oder auch nicht :-) der Schriftsatz ... Gruß, -- Schusch 23:27, 8. Jul 2004 (CEST)
-
-
- Mag sein, aber wenn ich ein bestimmtes Betriebssystem installiere und eine bestimmten Browser und den Schriftsatz nicht mutwillig manipuliere, dann habe ich ja bestimmte typische Defaults. Aber Moment mal: Sitze eben wieder unter NT und IE 5.5 am PC, aber der früher gesichtet zu fette Punkt bei "·" ist wieder ganz normal. Und das bei allen Einstellungen unter Ansicht/Schriftgrad. Jetzt verstehe ich gar nichts mehr. Die engl. WP hat sich übrigens für "×" entschieden, soweit ich weiss. Gründe sind mir aber nicht bekannt. Bei dem Argument gegen "×", dass das niemand so schreibe, gebe ich zu bedenken, dass auch niemand das "a" so schreibt, wie es hier im Monobook erscheint, selbst wenn er Druckschrift schreibt ;-). Nicht dass ich damit ausdrücklich für "×" plädieren möchte, aber dagegen protestieren würde ich wohl auch nicht. --Wolfgangbeyer 02:06, 10. Jul 2004 (CEST)
-
-
-
-
- Dass sich die englische WP dafür entschieden hat, sollte keinen überraschen, × bzw. × ist in England, wie auch Australien u.a. englischsprechenden Ländern üblich. Bei Amerikanern würde ich aber denken, es wäre ein „*“, sonst hätte man den gleich aus ASCII rauslassen können und ein × reintun können. -- Ichs Meinung 16:06, 15. Jul 2004 (CEST)
-
-

-
-
- Damit die Diskussion nicht ganz einschläft ;-) hier screen shots vom "zu fetten Dot" bei ·, den ich unter NT mit IE5.5 gelegentlich (seltsammerweise nicht immer) sehe, und zwar mit Ansicht/Schriftgrad klein und mittel. Schön ist das nicht. Wenn das stimmt, dass es letztlich am Zeichensatz und nicht am Betriebssystem oder Browser liegt, dann sollte sowas evtl. auch bei anderen Konfigurationen vorkommen können. Hat das jemand schon mal so gesehen? Man sollte vielleicht auch mal nachsehen, was die engl. WP dazu bewogen hat, sich für × zu entscheiden. Besser als dieser fette Dot ist's schon, find' ich. --Wolfgangbeyer 16:57, 14. Jul 2004 (CEST)
-

-
-
-
- Ich glaube, dass das Kreuz im amerikanischen Sprachraum eher üblich ist als bei uns, daher konnten die sich leicht für × entscheiden. Bei mir (Win2000/IE5.5) ist · übrigens ein winziger Punkt, kein so'n hässlicher Tintenklecks. --Hubi 17:59, 14. Jul 2004 (CEST)
-
-
-
-
-
- Jetzt mal wie's bei mir ausschaut (Win2000/IE5.5). sdot ist unakzepabel. --Hubi 18:07, 14. Jul 2004 (CEST)
-
-
-
-
-
- hm, der Punkt ist so fett Wolfgang, dass ich lachen mußte :-) aber im Ernst ... ich denke · wäre schon eine gute Lösung, und zwar vor allem, weil das ×-Zeichen eher nach Kreuzprodukt aussieht ... Gruß, -- Schusch 16:10, 15. Jul 2004 (CEST)
-
-
Um mich ein wenig darüber lustig zu machen und meinem Sarkasmus darüber zu äussern habe ich mal hinzugefügt, wie es hier auf der uralten Sun (SunOS rosweisse 5.7 Generic_106541-23 sun4u sparc SUNW,Ultra-2) mit einem uraltten mozilla 1.4a aussieht. Und hier ist alles OK, wenn Microsoft das nicht hinbekommen hat dann muss ich ganz herzlich lachen ;-) --Paddy 16:51, 15. Jul 2004 (CEST)
- Vielleicht sollten wir zweigleisig vorgehen und im hiesigen Artikel trotz aller Bedenken erst mal · empfehlen, damit überhaupt mal was zum Thema Exponentialdarstellung dort steht (ich scheine ja der einzige zu sein, der manchmal bei · diesen komischen fetten Dot sieht). Und gleichzeitig kann dann, wer Lust hat sich Gedanken über eine längerfristige Lösung machen, für die wir die Entwickler benötigen. Nach meinen 3-4 Vorschlägen an die Entwickler habe ich die Befürchtung, dass sich so was ewig hinziehen kann (keiner meiner bisherigen Vorschläge wurde bisher umgesetzt - nicht mal dieser simple und wichtige). Was meint ihr? --Wolfgangbeyer 18:55, 26. Jul 2004 (CEST)
-
- gute Idee, laß uns das mal so machen! (da keine großen Gegenstimmen existieren, wäre es schön, wenn du es einfach auf der Seite einträgst ...) -- Schusch 19:02, 26. Jul 2004 (CEST)
Ich habe eine große Gegenstimme. Was soll den dieses Konstrukt darstellen? Ist es Konform mit der Norm? Wenn nicht, dann bin ich dagegen. --Paddy 19:10, 26. Jul 2004 (CEST)
-
- Paddy, mit welcher Norm? Du hast doch den ganzen Schmarrn :-) den wir oben schon geschrieben haben, gelesen ... da kann ich die Frage auch anders und natürlich provokativer stellen: willst du jetzt Windows-User ausschließen? Es sei denn Hubi hat sich völlig verhauen und es geht alles wunderbar ... aber das kann ich mir nicht vorstellen -- Schusch 19:34, 26. Jul 2004 (CEST)
-
-
- Hoppla, habe nicht mitbekommen, dass hier noch diskutiert wird, während ich den Vorschlages schon umgesetzt habe. @Paddy: Ich verstehe zwar Deine Bedenken aber angesichts der Fakten sehe keine akzeptabel Alternative (siehe mein Kommentar oben von 13:12, 6. Jul 2004). 90% aller User mit einem normgerechten Quadrat zu konfrontieren kanns jedenfalls nicht sein. Oder was wäre Deine normgerechte Alternative? Mit × wäre ich schon auch einverstanden. Aber da in dieser doch nicht ganz nebensächlichen Sache die Disskussion mal wieder für 10 Tage geruht hat, plädiere ich schon für eine baldige Entscheidung im Sinne einer Interimslösung, bevor das im Sande verläuft. Wenn mal eine bessere Lösung gefunden ist, kann man eine solche Interimslösung sicher nicht allzu schwierig per Skript ersetzen. --Wolfgangbeyer 20:08, 26. Jul 2004 (CEST)
-
-
-
- Nochmal hoppla - eine kleine Entscheidung müssen wir noch treffen: Setzen wir um den ·-Operator (oder welchen auch immer) geschützte Leerzeichen, wie es wohl korrekter wäre (oder?), oder ersparen wir dem User diese beiden ? Tendiere eher für ersteres, kann mich aber auch mit letzterem anfreunden. --Wolfgangbeyer 20:30, 26. Jul 2004 (CEST)
-
Jungs und Mädels, ihr müßt beim Vergleichen auch ein bisschen daran denken, dass es sich hier mehr um ein Problem der installierten und vom Browser verwendeten Zeichensätze als um das Betriebssystem handelt. Wer heute noch ohne Unicode-Zeichensatz arbeitet sollte das sowieso schnellstens ändern. Es ist besser, die Benutzer ihre Sachen auf einen aktuellen Stand bringen zu lassen als lauter falsche Workarounds einzuführen. Also: sdot. -- Schnargel 21:24, 27. Jul 2004 (CEST)
- Hast Du obige Diskussionsbeiträge gelesen? Wenn ja dann plädierst Du also dafür, dass 90% aller Leser mit einem Quadrat konfrontiert werden von denen wiederum >98% Null Ahnung haben, dass sie das ändern könnten. Die willst Du also mit Deinem Bestehen auf irgendwelchen Normen vor den Kopf stoßen. Die sehen doch die Schuld (eigentlich zu Recht!) nicht bei sich selbst sondern bei uns. Nicht mal ich habe eine Ahnung wie ich meinen PC auf Unicode-Zeichensatz umstellen könnte (wäre aber nett, wenn Du's mir verraten würdest ;-)). Die Programmierer und die Normen haben den Anwendern zu dienen und nicht umgekehrt! Vielleicht hilft das platzieren dieser Interimslösung, da etwas zu bewegen - wenigstens bei unseren Programmierern (bei Bill Gates sicher nicht, leider). Ich bin ja auch nicht glücklich über ·. Aber die Exponentialdarstellung im Artikel einfach wie bisher totzuschweigen ist auch keine Lösung und ⋅ noch weniger. --Wolfgangbeyer 23:23, 27. Jul 2004 (CEST)
- Lese gerade, dass wir auf UTF-8 umstellen. Heißt das, dass wir einfach ⋅ empfehlen können bzw. sollten? Bin ab sofort für mehrere Tage in Urlaub. --Wolfgangbeyer 08:33, 28. Jul 2004 (CEST)
- Nach der Umstellung auf UTF-8: ⋅ liefert unter IE 5.5 das gleiche Quadrat wie ⋅ statt einen Punkt - toll! Tja dann eben doch · - bis auf weiteres zumindest. --Wolfgangbeyer 21:40, 30. Jul 2004 (CEST)
-
- tja, das spricht dann für die richtige Interpretation von ⋅ und gegen eine gewisse Firma ... evtl. geht es aber einfach mit den richtigen Zeichensätzen, denn am Betriebssystem selber wird es wohl eher nicht liegen, oder ... - ist die Frage, ob wir dafür eine kurze Installationsanleitung liefern sollten ... -- Schusch 22:45, 30. Jul 2004 (CEST)
-
-
- Weiß nicht, ob ich das mit der Umstellung auf UTF-8 richtig verstanden habe. Es bedeutet ja offenbar nur, dass man so was wie ⋅ nicht mehr in dieser Weise verschlüsselt eingeben muss sondern statt dessen diese beiden Bytes direkt z. B. über die Zwischenablage aus einem Word-Text, wo das Zeichen richtig dargestellt wird. D. h. unser Problem ist gar nicht tangiert. An der falschen Darstellung von "⋅" oder "⋅" hat sich durch die Umstellung damit gar nichts verändert und damit eigentlich auch nichts an der Argumentation für bzw. gegen ⋅ oder ·. Wenn durch die Umstellung nun plötzlich alle Umlaute verstümmelt wären, könnte man wohl erwarten, dass die Leser irgendwelche Hinweise zur Rechnerkonfiguration befolgen (wäre auch schon eine Zumutung fände ich), aber angesichts der Seltenheit von Exponentialdarstellungen werden >90% der Betroffenen sich einfach mit dem Quadrat abfinden. Wir müssen dafür sorgen, dass es nicht auftritt. Wer hier kyrillisch oder arabisch lesen will, von dem kann man natürlich schon mehr erwarten. --Wolfgangbeyer 10:24, 31. Jul 2004 (CEST)
-
-
- klar, immer noch für · - sorry, daß das falsch rüberkam - ist halt offensichtlich die kompatibelste Variante - es war halt nur die Idee, ob jemand (sorry, ich habe hier kein Windows) einen kurzen Schriftinstallations für Windows-Benutzer zaubern kann. Es wird sicher einige geben, die sich über komische Quadrate in bestimmten Artikeln wundern und evtl. dieses beheben wollen. Aber ok, das ist ein anderes Thema. -- Schusch 13:16, 31. Jul 2004 (CEST)
-
-
- Die Anleitung zur Schrifteninstallation findet man unter Wikipedia:Browser-FAQ. Bei mir (Win98 und Office 2000) funktionierts aber nicht. Finde z. B. nicht den mit Office 2000 angeblich installierten Font Arial Unicode MS. Aber bei der Eingabe könnte man nun · direkt eingeben, so dass dieser Dot schon im Editorfenster zu sehen ist, nämlich unter Windows offenbar mit der Tastenkombination Alt 0183 (per Zifferntastenblock). Zwischen 2 sieht er aber dann auch ziemlich verloren aus, so dass ich nicht weiß, ob wir das wirklich empfehlen sollten. Vielleicht zusätzlich? · lässt sich auch leichter merken. Wie ich eben experimentell in der dänischen WP festelle, die wohl noch nicht umgestellt hat, geht Alt 0183 auch ohne UTF8-Umstellung. Damit sehen ich nun überhaupt keinen Bezug mehr zwischen der WP-Umstellung auf UTF8 und unserem Problem. --Wolfgangbeyer 14:18, 31. Jul 2004 (CEST)
-
Inzwischen ist ja schon etwas Zeit vergangen. Ist man inzwischen bereit, zum Standard überzugehen und den sdot aus utf-8 zu verwenden? Da ich aus beruflichen Gründen Sprachen mit middot häufiger verwende (Katalanisch, Okzitanisch), ist mir an einer sauberen Unterscheidung des mathematischen Zeichens und des orthografischen sehr gelegen. Da utf-8 nunmal Standard ist, sollte es eigentlich die hier doch sehr ausufernde Diskussion nicht geben. Und wie die Tabelle zeigt, geht es ja inzwischen auch beim Internet-Explorer. Als Open-Source-Anhänger halte ich das IE-Argument sowieso für vernachlässigbar. --maha 21:00, 1. Jan 2005 (CET)
[Bearbeiten] UTF8 und ·
Sorry, Paddy – ich fürchte wir brauchen · trotz UTF8. Auf meinen Windows XP mit IE wird Dein UTF-Zeichen sowohl im Artikel als auch im Quellkode als Quadrat dargestellt. Ganz abgesehen davon, dass ich nicht wüsste, wie ich das Ding überhaupt erzeugen soll, ohne mich mühsam hier her zu hangeln, um das Ding in die Zwischenablage zu bugsieren - wenn es denn funktionieren würde. Hier noch mal mit Nachdruck mein bereits oben erwähntes Credo zu dieser Sache: Die Programmierer und die Normen haben den Anwendern zu dienen und nicht umgekehrt! Habe den alten Zustand wieder hergestellt. --Wolfgangbeyer 19:31, 17. Nov 2004 (CET)
Also ich mach das ganz einfach mit moba.linuxfaqs.de und mit Windows kann man das über diese Zeichentabelle machen oder direkt über die Kodeeingabe. Mal aus Interesse gefragt: welche Zeichen kann der IE außerdem nicht? Ich bin ja nach wie vor der Ansicht, dass wir keine Browserschwachstellen ausbügeln müssen! Aber ich halte mich da ab jetzt raus. Die Diskussion wird mir zu langweilig ;-) IMHO und POV wer heute noch den IE verwendet, obwohl es viele bessere Alternativen gibt hat ohnehin schon verloren. Mehr sage ich dazu nicht mehr und mache meine Klappe zu. mfg --Paddy 21:37, 17. Nov 2004 (CET)
- Tja, wenn man bedenkt, dass dieses Zeichen im Latin-1 Supplement der Unicode Charts vorkommt. Also noch nicht einmal irgend etwas Exotisches. In der Tabelle auf [8] in der linken Spalte werden Unicode-Zeichen dargestellt. Da sollten keine Quadrate sein. :) Der IE ist halt ein wenig veraltet. Ich habe ja gehört, dass es eigentlich damit zu tun hat, dass die verwendete Schrift das Zeichen nicht enthält. Naja. Gruß. --Blaite 23:35, 17. Nov 2004 (CET)
Latin-1 wird also durch den IE nicht unterstützt? Super also ist es kein UTF-8 Problem. Wenn das nichts kommt werde ich den ganzen · durch ⋅ ersetzen. Für mich macht das sehr wohl einen Unterschied. Und ich liefer gerne screenshots nach. --Paddy 01:05, 18. Nov 2004 (CET)
- Habe es gerade mit Firefox 1.0 und IE 6.o unter Xp getestet. Der IE zeigt beim zweiten Punkt ein Kästchen an. Der IE zeigt aber korrekt an, dass die Seite UTF-8 kodiert ist. Heisst also, dass die UTF-8 Implementierung fehlerhaft ist IMHO. Ob wir darauf Rücksicht nehmen sollten ist zumindest sehr fraglich. Vielleicht ein Grund mehr den IE nicht mehr zu benutzen und vielleicht für MS ein Grund mehr seinen jetzt schon 3(?) Jahre alten Browser endlich grundzusanieren. Gruss --finanzer 01:30, 18. Nov 2004 (CET)
Das hat relativ wenig mit dem Browser zu tun, mehr mit dem Betriebssystem. Da aber Mozilla unter Windows XP das Zeichen findet, ist der MSIE nicht ganz unschuldig... Kurzum: fehlt das Zeichen bei vielen? Womöglich mit besseren Browsern? Wenn nein -> sch**** drauf. TheK(?!) 01:34, 18. Nov 2004 (CET)
- Hallo Paddy, wir sind uns ja sicher alle weitgehend einig hinsichtlich der Qualität einer gewissen leider weitverbreiteten Software. Und es tut mir auch weh, für das Ausbügeln von IE-Schwachstellen zu plädieren, aber wir müssen auch nicht die Erzieher der Surfer spielen. Es würde ja auch misslingen, da wohl kaum ein Laie den Fehler beim IE vermuten würde, der ja fast immer funktioniert, da die meisten Web-Designer sich auf seine Macken einstellen, sondern bei der Wikipedia. Hallo Thek, es scheint zumindest auch der Browser zu sein. Unter Firefox auf dem selben XP habe ich keine Probleme. Ob das Zeichen bei vielen fehlt? Nun, wohl bei über 90% aller Surfer - das ist ja wohl leider immer noch der Marktanteil der Kombination XP+IE. Da können wir schlecht einfach drauf sch****en. Würde uns schon rein biologisch überfordern ;-). --Wolfgangbeyer 23:09, 18. Nov 2004 (CET)
- Hallo Wolfgang. Ich will nicht sdot propagieren nur · wenigstens als Vorschlag der ersten Stelle haben (also ohne HTML entitäten). Auch wenn wenn mich die ganzen IE Leute nicht wirklich interessieren (die sollten sich bei M$ beschweren nicht hier) bin ich gegen unnötiges HTML-Entitäten in WP. Am Besten wäre noch ⋅ aber das werden wir wohl nie erzielen. Ist auch egal aber schade. --Paddy 23:46, 18. Nov 2004 (CET)
-
-
- "Auch wenn mich die ganzen IE Leute nicht wirklich interessieren ..." – Aber Paddy, das kannst Du doch nicht bringen. Das sind unsere Leser. Und das müssen überhaupt keine Deppen sein, sondern die haben sich einfach für die falsche Firma entschieden, weil sie sich nicht auskannten und daher naiv das gemacht haben, was die überwältigender Mehrheit macht. Man kann kaum jemandem vorwerfen, kein Computerspezialist zu sein, der es besser wissen müsste. Diese Leute haben mein volles Mitgefühl, und wir sollten es ihnen nicht noch schwerer machen, als sie es ohnehin schon haben. Welcher Laie käme denn auf die Idee, dass er z. B. mit Firefox dieses Problem nicht hätte? Die Werbung für bessere Software muss anders laufen. Und einen Vorschlag an erster Stelle zu haben und einen anderen an zweiter (?) – wie soll das in diesem Fall funktionieren? Ich fürchte, wie müssen diese Kröte einfach schlucken. --Wolfgangbeyer 00:07, 19. Nov 2004 (CET)
-
-
-
-
- Sorry, aber so wie Paddy es jetzt hingeschrieben hat, finde ich's absolut daneben. Der Leser interessiert sich nicht für die Feinheiten von UTF-8, IE, HTML usw. sondern er will wissen, wie er in der Wikipedia Zahlen in Exponentialdarstellung hinschreiben soll. Das erfährt er aber nicht. Kann doch nicht wahr sein, dass wir die ganze Diskussion, die wir früher hier schon mal geführt haben, für die Katz gewesen sein soll. Was meinen die anderen?? --Wolfgangbeyer 00:56, 19. Nov 2004 (CET)
-
-
-
-
-
-
- ich hab das noch nicht mal verstanden vorhin (irgendwie waren da ziemlich viele „&“ unterwegs) was da steht ... ich schau es mir morgen an und sage was dazu ... Schusch 00:59, 19. Nov 2004 (CET)
-
-
-
- Kurze Zusammenfassung des Themas:
- Man hat zwei Zeichen zu unterscheiden, die als sdots oder middots bezeichnet werden.
- Beide Zeichen können als Entity oder einfach als utf-8 Zeichen eingeben werden.
- sdots können vom IE weder als Entity noch als utf-8 Zeichen korrekt dargestellt werden.
- Middots können sowohl als Entity als auch als utf-8 Zeichen korrekt dargestellt werden.
- Konvertierung von middots (egal ob Entity oder utf-8 Zeichen) in sdots kommt somit nicht in Betracht.
- Konvertierung von middot-Entitys in middot-utf-8 Zeichen käme in Betracht. Die Eingabe von Middots erfolgt über die Tastatur mittels ALT-GR-<Punkttaste> recht einfach, sollte also kein Problem sein. Das würde immerhin die Quelltexte leserlicher machen.
- Ansonsten einfach mal 1-2 Jahre warten - bis dahin wird auch der IE sdots können, die zumindest als mathematische Zeichen die richtige Wahl wären. --Mkleine 01:48, 19. Nov 2004 (CET)
@Schusch und Wolfgangbeyer ihr hackt auf etwas rum, um was es mir gar nicht geht! Ich will die IE Leute nicht belehren · ist OK aber wir brauchen die Entität nicht mehr! Und ich finde wenn das gleich richtig gemacht wird auch nich verkehrt! --Paddy 01:59, 19. Nov 2004 (CET)
- Hallo Paddy, Was hast Du davon, wenn Du es "richtig" machst, es aber bei 90% der Leser falsch dargestellt wird? Hallo Mkleine, ich hätte ja nichts dagegen die HTML-Entität · durch das UTF-8-Zeichen zu ersetzen, wenn jemand dem Leser sagen kann, wie er es über die Tastatur eingeben kann. Das hat bisher aber seltsamerweise noch keiner geschafft. Auch Dein ALT-GR-<Punkttaste> funktioniert bei mir unter XP SP2 weder mit Firefox 1.0 noch mit IE 6.0. --Wolfgangbeyer 09:09, 19. Nov 2004 (CET)
- also gut, erstmal Fragen: Warum steht denn jetzt im Artikel vor jedem Punkt noch ein Kaufmanns-Und (Beispiel:
3 &⋅ 109das gibt:3 &⋅ 109)? Frage an Wolfgang: Wird denn bei dir im IE das per <Alt-Gr>-<Punkttaste> eingegebene Zeichen (hier: ·) genauso dargestellt wie der middot (hier: ·)? Da bin ich mir jetzt nicht mehr so sicher ... ich habe Wolfgang so verstanden, daß der IE nicht mal den uft-8-middot darstellen kann. Wenn das so ist und auch zu verallgemeinern, dann sollte der utf-8-middot erstmal ausfallen. Wir können nicht einfach einen Anteil an Lesern größer 50 Prozent ausschließen - die Wikipedia soll ja schließlich ein Elfenbeinturm werden (oder wie heißt dieser Turm noch mal?). -- Schusch 12:51, 19. Nov 2004 (CET)
[Bearbeiten] vorläufiger Abschluss der Diskussion
Hallo, nach Absprache mit Paddy kann - Einverständnis aller Seiten vorausgesetzt - folgender vorläufige Abschluss der Diskussion vereinbart werden: Da es den Benutzern offenbar nicht zuzumuten ist, einen utf-8 middot per Tastatur einzugeben (der entsprechende Shortcut scheint nicht bei allen Benutzern zu funktionieren), dürfte man um die Verwendung von Entities kaum herumkommen. Wunschkandidat für das hier im Blick stehende Zeichen wäre sdot als Entity. sdot wird jedoch vom Internet Explorer nicht korrekt dargestellt. Daher bleibt im Augenblick keine Alternative zur middot-Entity. Es bleibt allerdings zu hoffen, dass der angesprochene Bug des IE in 1-2 Jahren behoben sein wird. Sollte dies der Fall sein, so wird zu diesem späteren Zeitpunkt eine Konvertierung von middot-Entities in sdot-Entities vorzunehmen sein. Der middot ist nicht das für mathematische Symbole empfohlene Zeichen und daher nur eine vorläufige Behelfslösung, bis die Probleme des IE behoben sind.--Mkleine 23:36, 19. Nov 2004 (CET)
ACK. Aber wer es jetzt "richtig" macht soll keine prügel kassieren! mfg --Paddy 23:44, 19. Nov 2004 (CET)
- Die Eingabe des Mittelpunktes funktioniert mit Alt+0183. Ich hatte die „0“ vergessen – ist jetzt aber auch „unten“ korrigiert! Auf Entitäten darf getrost verzichtet werden. Selbst der IE macht da IMHO keinen Unterschied, ob das Zeichen im Quelltext als Entität oder als Unicodezeichen eingegeben wurde. Die Unicodecharts würde ich so deuten, dass man den Mittelpunkt nehmen soll, falls der Punktoperator nicht zur Verfügung steht. Gruß. --Blaite 01:11, 20. Nov 2004 (CET)
-
-
- Volle Zustimmung zu Benutzer:Mkleine. So hatte ich auch das Ergebnis der ellenlangen Diskussion im Juli 04 (s. o.) interpretiert. Habe mal einen entsprechenden Vorschlag für den Artikel formuliert in der Hoffung, dass sich alle damit anfreunden können. Mit der Tastenkombination, die Blaite netterweise gefunden hat, habe ich auch nichts mehr gegen einen Verzicht auf Entities einzuwenden. Das "richtig"-machen sollten wir aber einem Bot überlassen, wenn es soweit ist. --Wolfgangbeyer 01:46, 20. Nov 2004 (CET)
-
-
-
-
- Schöne Zusammenfassung von Mkleine – auch ich bin voll einverstanden!
- apropos, noch ein paar Zahlen [9] zum User-Anteil: wenn ich die Grafik richtig interpretiere (dunkelgraue Zeilen sind Hauptanteile, hellgraue gehören zu der darüberstehenden dunkelgrauen Zeile; haut auch nicht wirklich hin, ist aber der wahrscheinlichste Fall?! Wäre schön, wenn mal jemand die Tabelle aufschlüsseln könnte). Also, das lese ich daraus:
- Internet Explorer: 70 % (davon entfallen ganze 2,7 % auf Benutzer noch mit Windows 98)
- (hier könnte der Anteil auch noch mal wesentlich geringer ausfallen, weil evtl. ein ganzer Teil davon Mozilla-Browser sind, die sich nur aus Kompatibilitätsgründen als IE ausgeben?)
- Mozilla: 12 %
- (hier entsprechend mehr, wenn meine Vermutung stimmt)
- Opera: 9,18 %
- Internet Explorer: 70 % (davon entfallen ganze 2,7 % auf Benutzer noch mit Windows 98)
- -- Schusch 09:13, 20. Nov 2004 (CET)
- apropos, noch ein paar Zahlen [9] zum User-Anteil: wenn ich die Grafik richtig interpretiere (dunkelgraue Zeilen sind Hauptanteile, hellgraue gehören zu der darüberstehenden dunkelgrauen Zeile; haut auch nicht wirklich hin, ist aber der wahrscheinlichste Fall?! Wäre schön, wenn mal jemand die Tabelle aufschlüsseln könnte). Also, das lese ich daraus:
- Schöne Zusammenfassung von Mkleine – auch ich bin voll einverstanden!
-
-
-
-
-
-
-
-
- Interessant. Hatte kürzlich gelesen, dass trotz einer Verdoppelung des Anteils der Firefox-Surfer, der IE-Anteil immer noch über 90% liege. Vielleicht gehören Wikipedia-Leser zu den etwas aufgeklärteren Surfern, bei denen diese Verhältnisse anders aussehen. Das bedeutet aber auch, dass durch einen zunehmenden Bekanntheitsgrad der Wikipedia der IE-Anteil kurzfristig sogar ansteigen könnte ;-(. --Wolfgangbeyer 15:56, 20. Nov 2004 (CET)
-
-
-
-
-
-
-
-
-
-
-
-
- na, jetzt haben wir ja erstmal wieder einen schönen Kompromiss (hoffentlich hält der jetzt erstmal eine Weile) – wer weiß, wieviele Internet-Nutzer wir noch in die Fänge des Drachens treiben :-) -- Schusch 16:04, 20. Nov 2004 (CET)
-
-
-
-
-
-
[Bearbeiten] Internet Explorer kann Punktoperator – und mehr – als Unicodezeichen darstellen!
Den Mittelpunkt kann man unter Windows XP mit der Tastenkombination Alt+0183 eingeben. Der Punktoperator U+22C5 ist in der Schriftart Lucida Sans Unicode enthalten. Diese Schriftart enthält alle Zeichen der Unicode Chart 2200–22FF Mathematical Operators. Diese Zeichen kann man in Notepad und in Wordpad verwenden. Ich habe jetzt einfach mal im Internet Explorer gestartet und ein Testfile mit Punktoperatoren eingegeben. Nach Umstellung der Schriftart von Times New Roman auf Lucida Sans Unicode wurden keine Quadrate sondern Punkte angezeigt. Sie sehen kleiner (schmaller) aus als Mittelpunkte. :D Wir können also komplett umsteigen auf Punktoperatoren, wo Punktoperatoren hin sollen. Wer IE nutzt muss halt ein wenig frickeln. Wer jetzt noch das Totschlagargument einbringt, er könne es aber nicht direkt über die Tastatur oder mit irgendwelchen Tastenkombinationen eingeben, der sollte auf Unicode oder auf Windows verzichten. Viele Zeichen kann man halt nur via Charmap eingeben. Gruß. --Blaite 13:00, 19. Nov 2004 (CET)
- Hallo, kennt Ihre keine Leute, die gerne mal die Wikipedia benutzen möchten, aber reine User sind ohne Ahnung von den Innereien ihres Computers und als solche ihre volle Existenzberechtigung haben und wohl auch die überwältigende Mehrheit stellen? Ich kann Euch nicht recht verstehen: "Wer IE nutzt muss halt ein wenig frickeln." Wenn über jedem Quadrat, dass durch die IE-Macke erscheint eine Sprechblase zu sehen wäre, in der steht: "Sorry, Du musst jetzt leider etwas frickeln, wenn Du wissen willst wer ich bin. Installiere z. B. Firefox oder stelle die Schriftart xyz ein.", dann wäre Eure Position ja schon hart genug aber vielleicht noch diskutabel – aber so?? Diese 90% der Leser werden nicht frickeln, weil sie nämlich Null Ahnung haben, was sie tun müssten, sondern sie werden sich - völlig zu recht - über uns ärgern. Selbst ich komme mit Benutzer:Blaites obigen Tipps nicht weiter: Alt+183 liefert bei mir unter XP SP2 keinen Punkt, weder im IE noch in Firefox, Notepad oder Word. Weder mit den Ziffern oben auf der Tastatur noch auf dem rechten Zifferntastenfeld, weder mit Num ein oder aus und Alt Gr bringt auch nichts. Wenn sich überhaupt was tut, dann erhalte ich "À". Wäre auch nett, wenn mir jemand verrät, was Blaite unter die Schriftart umstellen versteht. Für welche Instanz überhaupt? XP oder IE oder was? Und wie? --Wolfgangbeyer 22:42, 19. Nov 2004 (CET)
- Ich hatte eine „0“ vergessen. Mit Alt+0183 kann man einen Mittelpunkt eingeben. Bei Windows funktioniert halt die Eingabe von Zeichen, die nicht auf der Tastatur zu finden sind, auf diese Weise. Weitere Zeichen finden sich in der Zeichentabelle (Startmenü\Programme\Zubehör\Systemprogramme). Der Umfang der Zeichen ist jedoch an die Schriftart gekoppelt. Unicode definiert nur die Stelle, an der sich ein Zeichen befinden soll. :)
- Mit „Schriftart umstellen“ meine ich die Umstellung in den Schriftarteinstellungen in den Internetoptionen. Erreichbar über Startmenü\Systemsteuerung\Internetoptionen oder über IE\Extras\Internetoptionen.
- Die Idee mit den Sprechblasen ist lustig. :D
- Die Wortwahl à la frickeln gehört wirklich nicht hier hin. Ich formuliere das mal neu: „Nutzer des IE müssen selbst dafür sorgen, dass ihre drei Jahre alte Software mit heutigen Technologien umgehen kann. Einen modernen Webbrowser zu benutzen ist da die einfachste Lösung.“
- Ich glaube, man muss wohl den Mittelpunkt benutzen, bis der IE weniger als 50 % Marktanteil hat oder 50 % der Windows-Nutzer über Longhorn verfügen. :(
- Falls noch Fragen offen sind, nur zu. Gruß. --Blaite 01:11, 20. Nov 2004 (CET)
-
- Stimmt der IE kann die Middots anzeigen. (Bei mir mit Arial Unicode MS) Ich würde das Problem so angehen, dass wir auf die Hauptseite einen Hinweis setzen à la »Eine weitgehend fehlerfreie Darstellung der Wikipedia kann nur gewährleistet werden wenn Sie einen Unicodefont für Ihren Browser einstellen. Wie das geht erfahren Sie hier«. Damit hätten wir dann Leute, die ⋅ (⋅) u.ä. lesen können. (Auf Diskussion:Devanāgarī hat sich jemand beschwert, man solle Bilder statt Unicodezeichen nehmen, damit alle es lesen können, ⋅ ist also das geringste Problem) – Ichs Meinung. ☏ 20:31, 23. Nov 2004 (CET)
-
-
- Dazu müssten wir aber erst mal wissen, wie man denn den IE 6 z. B. unter XP SP2 (wie bei mir) dazu bringt, Unicode richtig darzustellen. Die von Blaite oben angegebene Methode funktioniert bei mir jedenfalls nicht! Genauer: Im IE unter Extras/Internetoptionen/Allgemein/Schriftarten/Schriftart fürWebseiten: Lucida Sans Unicode einstellen. Habe es dummerweise erst jetzt mal ausprobiert. Wundert mich im Nachhinein eigentlich nicht schließlich heißt sans=ohne auf französisch ;-). Damit sind wir wieder mal so schlau wie schon im Juli, oder hat Blaite noch einen Trick auf Lager? --Wolfgangbeyer 00:09, 24. Nov 2004 (CET)
-
-
-
-
- Keine Ahnung wo das Problem liegt: bei mir ist der sdot (siehe Screenshot) einwandfrei zu sehen, wie gesagt, mit Arial Unicode MS. (Hab’s mal sehr klein gemacht.) – Ichs Meinung. ☏ 21:11, 24. Nov 2004 (CET)
-
-
-
-
-
-
- Kann sein, dass es mit Arial Unicode MS generell geht, aber das bietet mein IE 6 unter XP SP2 nicht an. Stellt sich die Frage, wie man sowas installiert. --Wolfgangbeyer 22:42, 24. Nov 2004 (CET)
-
-
-
-
-
-
-
-
- mal unter Wikipedia:Browser-FAQ#Windows_allgemein schauen? -- Schusch 23:57, 24. Nov 2004 (CET)
-
-
-
-
-
-
-
-
-
-
- Hab mal gerade nachgeschaut, was ich habe: Mein I. E. schreibt in Info einen großen Zeichensalat, an dessen Anfang 6.0 und an dessen Ende SP2 steht. Das Betriebssystem (Eigenschaften bei Arbeitsplatz) sagt mir es wäre ein Windows XP, Home Edition, Version 2002, Service Pack 2. Ich weiß nicht was ich wohl getan haben muss, aber die Versionen klingen sehr ähnlich, und wie gesagt, bei mir funktioniert’s – Ichs Meinung. ☏ 19:40, 25. Nov 2004 (CET)
-
-
-
-
-
-
-
-
-
-
-
-
- Habe alles ganz genauso wie Ichs Meinung bis auf Professional statt Home Edition und bei mir ist von Hause aus kein Arial Unicode MS installiert. Habe die Installation wie in Wikipedia:Browser-FAQ#Windows_allgemein beschrieben durchgeführt, ich kanns jetzt auch im IE einstellen, aber ich sehe trotzdem noch das Quadrat. Solange solche unverstandenen Sachen passieren, können wir's vergessen. Wir ärgern nur unsere Leser. --Wolfgangbeyer 22:15, 25. Nov 2004 (CET)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- Dieser Bill Gates scheint ja ein sehr seltsamer Mensch zu sein, dass in zwei gleichen Versionen des gleichen Programms unterschiedlich dargestellt wird; noch seltsamer ist ja das beide Versionen des Programms aus München kommen (ich unterstelle jetzt einfach mal, dass du da wohnst, wo du, laut Benutzerseite, arbeitest ;-)). Meins kommt von PC-Spezialist, deins vielleicht aus einem Anderen Stadtbezirk? (so wie ich das jetzt erahne, kommt deines entweder auch daher, oder von einem Kleinladen zwei Blocks weiter… ;-)) Hoffen wir doch, dass sich Firefox infolge des Stern-Artikels durchstetzt – Ichs Meinung. ☏ 21:42, 27. Nov 2004 (CET) (sch**ß Alzheimer…, was wollte ich jetzt noch? Ach ja …) P. S.: Wenn das Bild jetzt nicht mehr gebraucht wird (es ist ja nicht mehr nötig), tät ich’s zur Schnelllöschung freigeben. Einsprüche werden binnen 48 Stunden auf meiner Diskussionsseite angenommen – Ichs Meinung. ☏ 21:42, 27. Nov 2004 (CET)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- Oh man, das „Böser Bill“ kann ich nicht mehr hören. Der IE6 bzw. Windows bringen halt keine große Unicode-Schriftart mit, beide sind ja auch 3 Jahre alt, da war das noch nicht sonderlich aktuell. Trotzdem haben einige Arial Unicode MS, wie kommt das denn? Ganz einfach: auch andere Programme können Schriftarten mitbringen, in diesem Fall ist der „Schuldige“ Office, eines der Office-Programme (Word, Excel, Frontpage) oder Publisher. Diese Programme bringen mit Arial Unicode MS die meines Wissens größte Unicode-Schriftart überhaupt mit - böser Bill Gates, dass er Leute bezahlt, dass es überhaupt mal eine gute Unicode-Schriftart gibt... Download-Links für die Schriftart gibts übrigens unter Wikipedia:Lautschrift. Sorry, wenn ich bissl gereizt klinge, aber dieses ständige „Bill ist Schuld“ kann ich nicht mehr hören. MfG --APPER\☺☹ 23:14, 27. Nov 2004 (CET)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- Das Fehlen des Fonts ist das kleinere Problem. Dass er offenbar unter Home Edition funktioniert unter Professional aber nicht, ist das größere. --Wolfgangbeyer 11:19, 28. Nov 2004 (CET)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- Gut gut, Apper, nicht gleich in die Luft gehen: Ich habe den Bill in diesem Zusammenhang nur als „seltsam“ bezeichnet. Ich empfinde noch einen gewissen Unterschied zwischen „seltsam“ und „böse“… À propos: Ich hab Arial Unicode MS auch erst vor ca. 4 Monaten installiert, das System hat schon mindestens eine Weihnacht hinter sich – Ichs Meinung. ☏ 20:06, 30. Nov 2004 (CET)
-
-
-
-
-
-
-
-
-
[Bearbeiten] Multiplikationspunkt/-kreuz
Auf Anregung von Wolfgangbeyer möchte ich einen Diskussionspunkt hier einbringen, der sich für mich bei meiner Arbeit an Größenordnung (Masse) ergeben hat. Es dreht sich um die Frage des Multiplikationszeichens zwischen Zahlen, also zum Beispiel in Zusammensetzungen wie 1,5 × 10³. Zur Illustration möchte ich hier den entsprechenden Absatz der Diskussion:Größenordnung (Masse) zitieren:
Zitat Anfang
Ich zitiere: "Nach DIN V 820-2 ist als Multiplikationszeichen zwischen Zahlen nur das liegende Kreuz zulässig."
Aus DIN 1338:1996-08 (Formelschreibweise und Formelsatz), Anhang A (informativ), Erläuterungen, Zu Abschnitt 4.2 (Multiplikationspunkt), 4. Absatz.
Publiziert in: Eva-Maria Baxmann-Kraft, Gottfried Herzog (Hrsg.): Normen für Übersetzer und technische Autoren. Beuth, Berlin 1999, Seite 229, ISBN 3-410-14414-5. — Daniel FR ⇔ 21:38, 2. Mär 2005 (CET)
- Hallo Daniel, ich hatte kürzlich den Malpunkt überall in "Größenordnung (*)" eingesetzt, weil es laut Wikipedia:Schreibweise von Zahlen die wikipediainterne Empfehlung ist. Wenn du neue Argumente hast, solltest du die zuerst mal unter Wikipedia Diskussion:Schreibweise von Zahlen in die Diskussion werfen, denn es betrifft ja nicht nur die 3 Artikel. Auf dieser Diskussionsseite hatte man sich seinerzeit relativ rasch für den Punkt entschieden und dann ewig darüber diskutiert, über welches Zeichen er umzusetzen sei. Die Existenz von DIN-Normen dazu kam nicht zur Sprache. In machen anderen Diskussionen hier wurde aber auch schon die Ansicht vertreten, dass DIN-Normen nicht unbedingt immer für die Wikipedia sinnvoll seien. --Wolfgangbeyer 23:42, 2. Mär 2005 (CET)
- Hallo, Wolfgang: Abgesehen davon, ob DIN-Normen in der Wikipedia immer sinnvoll seien, sehe ich kein Argument dafür, warum hier abweichend von der Norm der Punkt sinnvoller sein sollte. Ich werde deine Anregung bzgl. der Wikipedia Diskussion:Schreibweise von Zahlen aufnehmen. (Das Kreuz × ist übrigens unter Windows mit Alt + 158 einzugeben.) MfG, Daniel FR ⇔ 14:51, 3. Mär 2005 (CET)
Zitat Ende
Mich interessiert natürlich, wie ihr das seht. Ich bin jedenfalls geneigt, die oben genannte Norm anzuwenden. Bei Bedarf kann ich auch den gesamten Kommentar zu Multiplikationspunkt und Liegendes Kreuz aus der o. g. Quelle zitieren (ca. 1000 Zeichen abzutippen).
— Daniel FR °∪° 12:24, 18. Mär 2005 (CET)
(Ergänzende Info: Alt + 0215 tut's auch und entspricht der HTML-Entität "×" [oder "×"])
- Hallo Daniel, das Zitat (entweder von dir, oder wenn es so kurz in dem Buch steht, dann vom Autor des Textes) verfehlt den Sinn, da es aus dem Zusammenhang reißt. In der Norm 1338:1996-08 (und nicht im Anhang) steht das anders. Unter "4.2 Mulitplikationszeichen", "4.2.1 Arten der Darstellung" steht: Produkte werden durch Nebeneinanderschreiben der Faktoren dargestellt. Falls diese Schreibeweise mißverständlich ist (z. B. bei Faktoren, die selbst aus mehreren Buchstaben bestehen), ist ein Ausschluß oder Multiplikationspunkt einzufügen. (was ist ein Ausschluß?) Weiter unten bei "4.2.2 Multiplikationspunkt" steht Will man Gruppen von Faktoren bilden oder führt ein einfaches Nebeneinanderschreiben der Faktoren zu Irrtümern (z. B. bei in Ziffern geschriebenen Zahlen), dann setzt man zwischen die Faktoren einen Multiplikationspunkt. Unter Punkt "4.2.3 Liegendes Kreuz" steht dann: Das liegende Kreuz wird in den Zahlenangaben für Flächenformate und für räumliche Abmessungen verwendet. Dabei steht hinter jedem Zahlenwert das Einheitenzeichen; siehe auch DIN V 820-2. [... Beipiele ausgelassen ...] Außerdem ist das liegende Kreuz für vektorielle Produkte zu verwenden. Der Anhang A ist als "informativ" gekennzeichnet, der von dir zitierte Abschnitt verteidigt die Verwendung des Multiplikationspunktes bis zum Schluß, wobei Multiplikationspunkte nach der DIN 1308 nur dann gesetzt werden sollen, wenn sie zur Klarheit dienen oder etwas verdeutlichen sollen. Nur im letzten Satz (als extra Absatz) weist dieser Abschnitt auf die abweichende Norm DIN V 820-2 hin (steht das V für "vorläufig"?).
- Anzumerken dazu habe ich noch, dass der Multiplikationspunkt in der deutschsprachigen Literatur (zumindest in der deutschen) üblich ist, während das liegende Kreuz eben in der englischsprachigen Literatur (zumindest in der amerikanischen) üblich ist. Das ist in meinen Augen ein gewichtigeres Argument als die Norm. Ich habe gerade testweise mehrere Bücher in die Hand genommen (Verlage Spektrum, Stöcker und Springer, Teubner Leipzig), alle verwenden den Multiplikationspunkt. Auch das könnte man natürlich vertiefend erforschen ;-) (ich hätte da vorzugsweise aber noch folgendes anzubieten: keine eckigen Klammern um Einheitenzeichen).
- -- Schusch 13:27, 18. Mär 2005 (CET)
Zu Normen generell: Beispielsweise gibt es wohl eine DIN-Norm, die vorgibt, dass der Bis-Strich mit Leerzeichen gesetzt werden soll, also etwa "1990 – 2005". Dies aber widerspricht der gängigen Typografie und auch etwa dem Duden, der es dort ohne Leerzeichen setzt ("1990–2005"), was auch in den meisten Büchern und Publikationen so gehandhabt wird. Das Beispiel soll zeigen, dass es gute Gründe gibt, manchmal von DIN-Normen abzuweichen. Beim Malzeichen würde mich mal die ISO-Norm interessieren, da gerade in Formeln doch die gängige internationale mathematische Handhabe eine Rolle spielt. Hat jemand eine solche ISO-Norm parat? Grundsätzlich habe ich den Eindruck, dass in mathematischen Publikationen doch eher der Malpunkt als das Kreuz verwendet wird. Das ist aber jetzt eine subjektive Beobachtung. Stern !? 13:39, 18. Mär 2005 (CET)
In der Frage ob Punkt oder Kreuz scheint sich noch nicht mal en:Wikipedia völlig einig zu sein: vgl. en:Multiplication. Mal wird der Punkt, mal das Kreuz genommen, und zwar im reinen Fließtext! – Ichs Meinung. ☏ 18:11, 28. Mai 2005 (CEST)
Richtig einig scheinen sich nur drei der interwikiverlinkten Wikipedias zu sein: Bei zweien verwenden sie ausschließlich den Punkt. Anders sind wieder die Holländer (die ja Niederländer heißen): Bei ihnen gilt das Kreuz anscheinend – Ichs Meinung. ☏ 18:39, 28. Mai 2005 (CEST)
- Das Kreuz wird doch beim Kreuzprodukt verwendet, wogegen beim Skalarprodukt der Punkt verwendet wird. Beim Spatprodukt werden beide kombiniert. So und jetzt nochmal die Frage? Nebenbei: ISOs, DINs und Dudenregeln können sich manchmal scheinbar wiedersprechen. Wenn man aber immer beachtet, wofür die Regeln im einzelnen gelten bzw. gelten sollen, dann wird’s manchmal klarer, oder nicht? --Blaite 18:41, 28. Mai 2005 (CEST)
-
- Wir sind hier nicht in einem n-dimensionalem Vektorraum (zum Glück, mit dem ärgere ich mich grad im Mathe-LK, da fällt mir ein, ich sollte mich mal langsam auf die bevorstehende Klausur vorbereiten), sondern in einem unendlich großen Körper (ℝ,+,·) und verwenden die ⊙-Verknüpfung, sprich die ·-Verknüpfung. (Oder auf bayerisch: Mir san bei de normalen Zoin und derna Malnemmæ) – Ichs Meinung. ☏ 21:52, 28. Mai 2005 (CEST)
[Bearbeiten] Geldbeträge?
Sorry, wenn ich woanders fragen sollte - gerade eben habe ich in einem Artikel 1,75 EUR, 7,50 EUR (mit einem Komma vor den Cents) geschrieben - wie auf den Websites des VRR. Ist das hier OK so?
-
- Da wird's doch bestimmt erlaubt sein mit ALT GR-E (€-Zeichen auf der Tastatur) oder €? Im Übrigen, das mit dem Komma, das wissen wir selbst nicht. -- Ichs Meinung 19:08, 14. Jul 2004 (CEST)
-
-
-
- Ist '€' Pflicht? Aus Erfahrung (z.B. in diversen Webforen) weiß ich, daß die Anzeige manchmal seltsam ist - deswegen habe ich mir 'EUR' angewöhnt. Weiß jemand mehr dazu? Yopohari 19:30, 14. Jul 2004 (CEST)
-
-
-
-
-
-
- Jetzt ist mir auch was eingefallen, € ist nicht in ISO 8859-1, sprich, man sollte es genausowenig verwenden wie ALT-0154 für š, da verschiedene Browser, die sich im Gegensatz zu WINDOWS-Programmen an ISO 8859-1 halten, darin ein Steuerzeichen sehen, und es zerschießen. D.h., weder ALT GR-E, noch ALT-128 verwenden (für €). -- Ichs Meinung 15:48, 15. Jul 2004 (CEST)
-
-
-
-
-
-
-
-
- Und nun, da die WP glücklicherweise auf UTF-8 umgestellt wurde, kann man sowohl den € direkt eingeben und ALT-0154 für š. Ist das nicht wunderbar? :-))) -- Ichs Meinung 将棋-Spieler 18:39, 6. Aug 2004 (CEST)
-
-
-
-
[Bearbeiten] Einheiten
[Bearbeiten] Schreibweise von Einheiten
Sorry, wenn ich das woanders hätte fragen sollen, aber im Online-Handbuch habe ich leider nichts dazu gefunden. Gibt es Übereinkünfte darüber, wann Einheiten ausgeschrieben und wann die üblichen Symbole benutzt werden sollten? In Diskussion:Atombombenexplosion wurde -- nach einer entsprechenden Änderung des Hauptartikels -- die Aussage gemacht, dass Einheiten, außer in Formeln oder besonders komplizierten Ausdrucken, immer als Wort ausgeschrieben werden sollten, also "Kilopascal" statt "kPa", selbst wenn sich mehrere Größenangaben im selben Absatz und sogar im selben Satz wiederholen. Dies fördere den Lesefluss. Dagegen würde ich einwenden, dass das wiederholte Ausschreiben viel eher als stilistisch ungünstige Wortwiederholung auffällt als wenn nur beim ersten Mal (sagen wir pro Absatz) ausgeschrieben und dann abgekürzt wird. Durch das fast durchgehende Ausschreiben wirken einige Abschnitte für meinen Geschmack ziemlich holprig. Besonders aufgefallen ist mir das im Unterabschnitt Atombombenexplosion#Ausbreitung der Druckwelle. Das Argument, der Text solle auch für Laien gut lesbar sein, steht damit meiner Ansicht nach in keinerlei Widerspruch. Bei allgemein gebräuchlichen Einheiten wie Kilometer sind auch in ihre Kürzel allgemein bekannt. Spezielle Einheiten sollten ohnehin mit Link und einmal ausgeschrieben eingeführt werden; aber bei ihnen ist sowohl das Kürzel als auch der Einheitenname dem Leser fremd, und ein Stocken im Lesefluss tritt so oder so auf.
Ich würde daher eher folgende Leitlinie vorschlagen: Einheiten sollten ausgeschrieben werden
- in Einleitungen (hier sollte mit Zahlen generell gespart werden),
- im Fließtext bei vereinzeltem Auftreten, sowie
- bei mehrfachem Vorkommen derselben Einheit nur beim ersten Mal pro Absatz oder Abschnitt,
und ansonsten sollte das gebräuchliche Einheitenkürzel benutzt werden. Bei kleinen Zahlen würde ich das Zahlwort nur dann benutzen, wenn es sich um Stückzahlen oder Angaben von Größenordnungen handelt; bei reellen Zahlen mit Einheit sollte unter Umständen die Ziffer benutzt werden, besonders wenn darunter auch gebrochene Zahlen sind, etwa "Die drei Monde haben Durchmesser von 3, 4,5 und 7 Kilometern". Wie sind die Meinungen dazu? Wie wirkt der Text besser und lesbarer?--SiriusB 19:05, 23. Aug 2004 (CEST)
- Ich finde, man sollte Einheiten ausschreiben. Da aber vielen, mich eingeschlossen, ganz einfach die Fähigkeit fehlt, mit Ungetümen wie „Kilometer“ stilistische Meisterwerke zu fabrizieren, fände ich eine Nutzung von „km“ nicht unangebracht. Jedoch sollte man immer versuchen die Abkürzung zu verhindern. Es sollte keine Maxime darstellen, worunter alles andere leiden muss. Das selbe gilt ja auch für die Anführungszeichen-Problematik. Nur sollte man dann „sechs km“ vermeiden, da es ganz einfach falsch, sehr falsch ist. Also „6 km“ oder eben „6 Kilometer“ oder „sechs Kilometer“ verwenden. Es hat sich ja in Zeitungen etabliert – so sehe ich das jedenfalls –, dass man in einem längeren Absatz (sie sollten immer lang genug sein!) am Anfang das Wort ausschreibt und dahinter in Klammern die Abkürzung setzt und nun im weiteren Verlauf nur die, dem Leser bekannte, Abkürzung verwendet. Bei Einheiten wäre das dann aber schon sehr extrem. Generell sollte man also einen Fließtext ohne Abkürzungen anstreben, es sei denn, diese haben sich schon extrem eingebürgert. ;-) --Blaite 18:39, 24. Aug 2004 (CEST)
-
- Hmm, mich würde eine nähere Begründung oder der Verweis auf typografische Artikel (am besten Online oder gar in Wikipedia selbst) interessieren – zumindest die Form, wie es im (mittlerweile wieder etwas "entschärften") angesprochenen Artikel geschah, wirkte auf mich, gelinde gesagt, ein wenig wie ein populäres Boulevardmagazin. Die Lesbarkeit wird IMHO durch Symbole statt ausgeschriebenen Einheiten eher erhöht. Ich denke, man kann das nicht mit klassischen Abkürzungen gleichsetzen; die Wirkung ist eine andere. Wenn zum Beispiel eine "exotische" Einheit wie Elektronenvolt eingeführt wird, dann macht es bezüglich der Lesbarkeit nur wenig Unterschied, da der Leser so oder so ins Stocken kommt. Einmal eingeführt, sollte dann IMHO aber, bei häufiger Verwendung im Abschnitt, "eV" verwendet werden, schon damit der Text nicht so aufgebläht wirkt. Naja, vielleicht ist das auch Geschmackssache, aber es scheint, im Gegensatz zu Abkürzungen, keine "offizielle" Wikipedia-Richtlinie zu geben (und über die würde es sicher ebenso lange Diskussionen wie über den Tausendertrenner geben).--SiriusB 19:27, 24. Aug 2004 (CEST)
-
-
- Als Physiker hätte ich auf Anhieb erst mal für Abkürzungen plädiert. Aber vielleicht bin ich da auch zu befangen. Irritiert hat mich jedenfalls die MS Encarta 2002, die durchweg alles voll ausschreibt. Andererseits habe ich ein paar kopierte Blätter einer über 50 Jahre alten Enzyklpädie (evtl. sogar Brockhaus), die nur abkürzt („Zeisig, bis zu 12 cm langer Singvogel ...“). Einen sehr zahlenlastigen Artikel ohne Abkürzungen fände ich schon merkwürdig. Gemischte Schreibung wirft das Problem auf, wo wir die Grenze ziehen. Die Link-Möglichkeit sehe ich schon als dickes Argument für Abkürzungen im Vergleich zu einem Buch. Was machen denn die anderen etablierten Nachschlagewerke? --Wolfgangbeyer 23:50, 24. Aug 2004 (CEST)
-
-
-
-
- Alle Abkürzungen von Einheiten sollten in der physikalisch korrekten Schreibweise erfolgen! Also 5,7 cm, 1046,45 hPa, 240 V, 50 Hz, … – Ichs Meinung. 将棋-Spieler 19:20, 11. Nov 2004 (CET)
- Meinst du „typografisch korrekte Schreibweise“? :) Darüber streitet ja auch niemand. Die Frage ist halt nur, wie, wann und warum man nun die „Normalform“ oder die Abkürzung nehmen sollte. Also „240 Volt“ oder „240 V“? Gruß. --Blaite 19:50, 11. Nov 2004 (CET)
- Alle Abkürzungen von Einheiten sollten in der physikalisch korrekten Schreibweise erfolgen! Also 5,7 cm, 1046,45 hPa, 240 V, 50 Hz, … – Ichs Meinung. 将棋-Spieler 19:20, 11. Nov 2004 (CET)
-
-
-
-
-
-
-
- Wenn ich „physikalisch“ schreibe, meine ich „physikalisch“‼ – Ichs Meinung. 将棋-Spieler 20:26, 12. Nov 2004 (CET)
- Damit wir weiterkommen wäre ein Beispiel für eine „physikalisch nicht korrekte Schreibweise“ hilfreich, damit ich verstehe, was du meinst. :) Gruß. --Blaite 22:18, 12. Nov 2004 (CET)
- Wenn ich „physikalisch“ schreibe, meine ich „physikalisch“‼ – Ichs Meinung. 将棋-Spieler 20:26, 12. Nov 2004 (CET)
-
-
-
-
-
-
-
-
-
-
-
- Ich meine damit, dass wir alle Einheitenkürzel als bekannt vorraussetzen. Bei sehr unbekannten Einheiten wie cd (Candela) kann man dann den Begriff beim ersten Auftauchen in Klammern setzen. Falsch wäre: „230 Volt“ – Ichs Meinung. 将棋-Spieler 11:32, 17. Nov 2004 (CET)
- Achso. Du willst also nur noch die Einheitenzeichen anstelle der Namen der Maßeinheiten verwenden. Gegen die Verwendung von Einheitenzeichen in Formeln habe ich ja nichts einzuwenden, ganz im Gegenteil befürworte ich dort Einheitenzeichen. :) Im Fließtext sollte man beim erstmaligen Auftauchen im Paragraphen jedoch den Namen schreiben. Wenn die Dichte derselben Maßeinheit jedoch sehr groß ist, wäre das Einheitenzeichen dagegen ein sinnvolles typografisches Hilfsmittel. Gruß. --Blaite 13:40, 17. Nov 2004 (CET)
- Ich meine damit, dass wir alle Einheitenkürzel als bekannt vorraussetzen. Bei sehr unbekannten Einheiten wie cd (Candela) kann man dann den Begriff beim ersten Auftauchen in Klammern setzen. Falsch wäre: „230 Volt“ – Ichs Meinung. 将棋-Spieler 11:32, 17. Nov 2004 (CET)
-
-
-
-
-
- kann mir mal jemand erklären, was an „230 Volt“ falsch ist? Sehe ich hier gerade den Wald vor lauter Bäumen nicht mehr? Selbstverständlich dürfen statt der Einheitenzeichen (die Abkürzung der eigentlichen Namen der Einheiten) auch die voll ausgeschriebenen Einheitennamen verwendet werden, ohne das der Ausdruck falsch wird ... insbesondere im Fließtext ist dies keinesfalls unüblich und meines Wissens nach nicht falsch. Ich bin da nicht ganz so festgelegt - manchmal sieht es halt mit ausgeschriebener Einheit (insbesondere bei der Pseudo-Einheit „Prozent“) besser aus, manchmal besser mit Abkürzung – in Formeln allerdings sollte man meiner Meinung nach, außer in ganz besonderen Fällen (mir fällt gerade kein passender ein), immer die Abkürzung verwenden -- Schusch 17:57, 17. Nov 2004 (CET)
- Genau. Mir fällt aber ein guter Grund ein, warum man manchmal den Namen der Maßeinheit und manchmal das Einheitenzeichen verwendet. Zwei Grundregeln, aber nur IMHO:
-
-
-
-
- Man sollte den Namen der Maßeinheit schreiben.
- Beispiel: „Das Stromnetz wird mit 230 Volt betrieben.“
- Das generelle Schreiben der Namen der Maßeinheit ist in zwei Fällen, öhm, nervig.
- In Formeln sollte das Einheitenzeichen verwendet werden, wenn man Platz sparen möchte oder muss. Also (fast) immer. Es sei denn, man führt eine Maßeinheit ein oder möchte sie betonen oder dem Laien näher bringen.
- Beispiel: „1 J = 1 Nm = 1 Ws = 107 erg = 0,2388 cal = 0,102 kpm = 0,2778·10-6 kWh“
- Im Fließtext sollte das Einheitenzeichen verwendet werden, wenn ansonsten die Menge an Maßeinheitennamen den Text verstopfen, der eigentliche Inhalt also untergeht. Dies geschieht vor allem, wenn eine einzige Maßeinheit viele Male hintereinander vorkommt.
- Beispiel: „Der Ort liegt 136 Meter über Normalnull. Der Nachbarort liegt 124 m ü. NN. Der Gipfel des Berges etwas weiter flussabwärts liegt in einer Höhe von 387 m ü. NN.“
- In Formeln sollte das Einheitenzeichen verwendet werden, wenn man Platz sparen möchte oder muss. Also (fast) immer. Es sei denn, man führt eine Maßeinheit ein oder möchte sie betonen oder dem Laien näher bringen.
- Man sollte den Namen der Maßeinheit schreiben.
-
-
-
-
- Naja, das waren vielleicht nicht die besten Beispiele, aber sie zeigen, dass es Unfug wäre, generell alles auszuschreiben oder generell alles abzukürzen. Man muss halt auch immer von Fall zu Fall unterscheiden und das ganze im stilistischen und typografischen Kontext betrachten. Gruß. --Blaite 00:49, 19. Nov 2004 (CET)
-
-
-
-
- na, das wäre ja schon fast ein Kapitel für Wikipedia:Typographie :-) -- Schusch 00:54, 19. Nov 2004 (CET)
-
-
[Bearbeiten] Geschütztes Leerzeichen auch bei ausgeschriebenen Einheiten?
So, wie ich Aglarech mal verstanden habe, sollte das geschützte Leerzeichen nur eingefügt werden, wenn das Einheitenzeichen verwendet wird (4,3 m)? --ChristianErtl 15:20, 19. Okt 2005 (CEST)
[Bearbeiten] Lieber Narrow no-break space statt zwischen Zahl und Einheit?
Zitat:
- Zwischen Zahl und Einheit sollte man, um unschöne Zeilenumbrüche zu vermeiden, ein
setzen (non breakable space).- Soweit ich weiß, wäre es typografisch korrekter bei Zahl mit Einheit stattdessen ein
 zu setzen. Dieses Zeichen wird auch nicht umgebrochen, sollte aber schmaler als das dargestellt werden. --Schmidbauer 15:56, 6. Feb 2006 (CET)- Das ist formal richtig, aber wenig praktikabel,
 ist wenig aussagekräftig und schwer zu merken.--Gunther 15:59, 6. Feb 2006 (CET)- Ach komm, wenn's jeder Autor auf Wikipedia:Schreibweise von Zahlen nachlesen könnte, wär's auch nicht weniger aussagekräftiger als vielen Anfängern unbekannte
. --Schmidbauer 16:09, 6. Feb 2006 (CET)- Es gab auch schon den Vorschlag einer Syntaxerweiterung, also dass z.B. _ durch das entsprechende Zeichen ersetzt wird. Mir ist auch nicht klar, wieviele Browser mit   klarkommen.--Gunther 16:42, 6. Feb 2006 (CET)
Vor allem kommt die Wikisoftware nicht damit klar. &#nnnn; geht nicht, man muss das Zeichen schon als Unicode eingeben. Das wird dann für die Autoren tatsächlich nicht mehr verständlich, lassen wir das ganze also einstweilen.--Schmidbauer 17:24, 6. Feb 2006 (CET)- Widerruf: Die Wikisoftware kommt sehrwohl damit klar, nicht aber mein Browser (Firefox). --Schmidbauer 11:30, 7. Feb 2006 (CET)
- Dann hätte ich noch das
 anzubieten, das scheint die gleiche Funktion zu haben, wird bei meinen Tests von Mozilla und Internet Explorer interpretiert. Beim IE 6 ist es aber leider nicht schmaler als das normale . Was spricht dagegen, kann ich den Satz auf der Seite umändern? --Schmidbauer 15:16, 7. Feb 2006 (CET)
- Es gab auch schon den Vorschlag einer Syntaxerweiterung, also dass z.B. _ durch das entsprechende Zeichen ersetzt wird. Mir ist auch nicht klar, wieviele Browser mit   klarkommen.--Gunther 16:42, 6. Feb 2006 (CET)
- Ach komm, wenn's jeder Autor auf Wikipedia:Schreibweise von Zahlen nachlesen könnte, wär's auch nicht weniger aussagekräftiger als vielen Anfängern unbekannte
- Das ist formal richtig, aber wenig praktikabel,
- Soweit ich weiß, wäre es typografisch korrekter bei Zahl mit Einheit stattdessen ein
Eine Möglichkeit für das unproblematische Einfügen eines schmalen Weißraums stelle ich hier vor. --Quilbert 問 18:05, 26. Mär. 2008 (CET)
[Bearbeiten] Leerzeichen vor °C (Grad Celsius)
Habe bisher nicht gefunden, wie die Schreibweise bei Temperaturangaben ist. Bei Gradangaben in Koordinaten wird das Leerzeichen weggelassen. Aber wie ist das bei Temperaturangaben wie °C oder °F? Leerzeichen davor oder nicht? -- Anhi 10:29, 8. Feb 2006 (CET)
- Nachdem bei Grad Celsius, Grad Fahrenheit, Grad Rankine, Grad Delisle ... usw. überall ein Leerzeichen - am Besten ein geschütztes
- vor °C; °F, °R, °D ... steht, würde ich mich danach richten. Grüße, ElRakı ?! 11:15, 8. Feb 2006 (CET)
-
- Danke für die schnelle Antwort. Spricht etwas dagegen, diese Erkenntnis auch in diesen Artikel einzuarbeiten? -- Anhi 12:32, 8. Feb 2006 (CET)
-
-
- Die Richtlinie zur Zusammenschreibung des Gradsymbols und der Angabe Celsius (Wikipedia:Schreibweise von Zahlen) richtet sich offensichtlich nach der Fachsprache. Ich orientiere mich (auch bei meiner Korrektur des Artikels Schichtvulkan) an der Schreibweise für "Laien" (Duden, Die Deutsche Rechtschreibung, 24. Aufl., S. 464). -- Siskotierer 17:35, 18. Mär. 2007 (CET)
-
[Bearbeiten] Prozent
Schreibt man im Fließtext eigentlich 90 % oder 90 Prozent ? Auch hier wäre eine einheitliche Regel wünschenswert. --J. Patrick Fischer 15:56, 10. Mär 2006 (CET)
- Das ist in der Tat ein ungeklärtes Thema, ebenso ob man km oder Kilometer usw. schreibt. Ich finde die angekürzten Maßeinheiten (%, m, km, kW, ...) bei rein technischen Angaben meist schöner/lesbarer als Prozent, Meter, Kilometer, Kilowatt, ... Bei eher "prosaischen" Texten hingegen nicht: So sollte man sicher nicht "mehrere km lang" schreiben. Auch gefallen mir die Abkürzungen umso besser, je größer die Zahl ist. Und wenn die Zahl ohnehin ausgeschrieben wird, dann muss natürlich auch die Einheit ausgeschrieben werden. Wäre aber in der Tat gut, wenn wir uns hier irgendwie auf eine Art Richtschnur einigen könnten, um einigermaßen Konsistenz zu erreichen. -- H00517:01, 10. Mär 2006 (CET)
Vorschlag: Bei Einheiten ohne Ziffern davor (Er ist Kilometer gelaufen) soll ie Einheit ausgeschrieben werden. Ebenso bei Einheiten, die auf Zahlen kleiner/gleich Zwölf folgen, da diese ebenfalls ausgeschrieben werdne (z.B. zwölf Prozent). Ausnahme: Zahlen mit Einheiten in Tabellen. Einheiten nach Zahlen >12 sollen abgekürzt werden (z.B. 13 %). Was meint Ihr ? --J. Patrick Fischer 22:18, 11. Mär 2006 (CET)
Bei Prozent bin ich auch unsicher. Oft sehe ich 12% und auch 12 %. Ich tendiere zu 12% da das % keine Einheit ist sondern zur Zahl gehört. Einheiten sollten bei Ziffern abgekürzt werden. 12 km oder zwei Meter. Die Aussage, dass Ziffern bis 12 ausgeschrieben werden, ist total veraltet und erschwert die Lesbarkeit oft. --Flea 14:33, 27. Jun 2006 (CEST)
- Das wurde an anderen Stellen schon intensiv diskutiert (ich finde sie gerade nicht). Der Duden ist hier eindeutig, vor das % gehört ein Leerzeichen und zwar mit der Begründung, dass „%“ lediglich eine andere Schreibweise für das Wort „Prozent“ ist. Die eigentliche Frage lautet also: Halten wir uns an den Duden (bzw. das zu Grunde liegende offizielle Regelwerk der deutschen Rechtschreibkommission)? --jpp ?! 20:46, 28. Jun 2006 (CEST)
- Flea, die Frage war nicht, ob man 90 % oder 90% (also mit oder ohne Leerzeichen) schreibt, sondern ob man das Wort ausschreiben soll. Die Frage nach dem Leerzeichen ist völlig eindeutig. Dass man es immer häufiger ohne Leerzeichen sieht, kommt aus dem Englischen; dort setzt man nämlich üblicherweise das Prozentzeichen direkt an die letzte Ziffer. -- H005 22:15, 28. Jun 2006 (CEST)
- Ich denke man sollte sich schon die verbreiteten Vorgaben halten, da es sonst zu unnötigen Diskussionen kommt. Ich halte % in den meisten Fällen besser als Prozent. Man sieht das Symbol und erfaßt sofort den Sinn. Ist aber nur meine Meinung. --Flea 12:31, 29. Jun 2006 (CEST)
-
- Meiner Meinung nach beschreibt das Prozentzeichen einen Bruch. Man schreibt auch nicht 1 / 2, wenn man 1/2 meint. Deswegen ist mein Vorschlag für die Wikipedia auch 19% anstelle von 19 % zu schreiben. Es erleichert den Lesefluss, da 19% als EIN Wort gesehen wird. Bei anderen Maßeinheiten gebe ich zu, dass ein Leerzeichen vor der Einheit hinzugefügt werden sollte. Wie kann dies offiziell genormt werden in der Wikipeida? Fakt ist, dass es in der Wikipedia mal so, mal anders verwendet wird und keiner weiß wie die korrekte Schreibweise ist. --Pietz 00:09, 22. Feb. 2008 (CET)
- In Printmedien üblich: Das Wort „Prozent“ ausschreiben, da leichter lesbar. --Dullnraamer 14:47, 9. Jan. 2007 (CET)
Ich sehe beim Verweisen im Bearbeitungskommentar gerade, dass das Ausschreiben von Prozent erst durch die Bearbeitung von Ra'ike in die Konventionen zur Schreibweise von Zahlen gelangt ist. Nicht, dass ich inhaltlich dagegen bin, aber nach diesem Edit ist eher unklar, welche der beiden Versionen, „15 %“ (in der Quelle: „15 %“) oder „15 Prozent“, nun dominierend sein soll. Kleines Beispiel von heute: Sollte im Artikel über den CDU-Politiker Christian Wulff die ausgeschriebene Variante verwendet werden oder nicht? Meine Bearbeitung hat die jetzige Formulierung dieser Konvention so interpretiert, aber ich finde trotzdem, wir sollten die Regel noch einmal genauer fassen. --Le petit prince ☎ messagerie 12:42, 5. Okt. 2007 (CEST)
[Bearbeiten] Maßeinheiten mit Leerzeichen durchkoppeln?
Wenn es 5 % heißt, heißt es dann Die 5 %-Hürde oder nach deutscher Durchkopplungsregel Die 5-%-Hürde? --androl 20:11, 28. Jul 2006 (CEST)
- Letzteres. Siehe § 44 der Amtlichen Regelung. --jpp ?! 16:47, 29. Jul 2006 (CEST)
Wie sieht das denn mit 50%ig aus? 50-%-ig? 50-%ig? 50 %ig? 50 %-ig? -- Anhi 23:44, 26. Dez. 2006 (CET)
- na, da schaust du einfach in das oben verlinkte Dokument - da steht die Antwort drin. -- Schusch 02:29, 27. Dez. 2006 (CET)
- Damit es nicht jeder selbst suchen muss: § 41, "100%ig" ohne Leerzeichen oder Bindestrich. --oreg 19:51, 29. Mai 2008 (CEST)
[Bearbeiten] Si-Einheiten
Ich erlebe immer wieder einmal Meinungsverschiedenheiten, ob bei Leistungsangaben PS oder kW angegeben werden sollen. Insbesondere Autofreaks argumentieren immer, dass "kein Mensch" kW benutze - ein Argument, für das ich der erste Gegenbeweis bin, denn ich bin ein Mensch und benutze immer nur kW. Ich habe keine Ahnung, wieviel PS genau mein Auto hat, es sind 85 kW - ca. 120 PS, schätze ich, aber es interessiert mich auch nicht. Für mich als Ingenieur ist PS eine Einheit aus den Anfängen der Wissenschaft, in heutige tagen etwa so hilfreich wie Kilopond oder Fuß. Es ist zwar richtig, dass Autofans und Populärliteratur wie "AutoBild" und "auto motor sport" vornehmlich von PS schreiben. Aber die Wikipedia als Enzyklopädie sollte sich meines Erachtens nach wissenschaftlichen Standards und gesetzlichen Normen richten und nicht nach dem, was man sich unter Freunden und Kollegen erzählt.
Ähnliche Uneinigkeiten sehe ich bei Kalorien vs. Kilojoule sowie in der Schifffahrt, wo oft noch von Knoten und Seemeilen geredet wird. (Damit können übrigens auch die meisten Laien nichts anfangen.)
Leider finde ich jedoch in der deutschen Wikipedia keine Hinweise, wie damit verfahren werden soll. Aus Gründen der Einheitlichkeit denke ich, dass wir uns hier auf ein paar Richtlinien einigen sollten.
Meine persönliche Meinung dazu ist, dass immer und überall die SI-Einheiten Standard sein sollten. Verbreitete alternative Einheiten sollten allenfalls als Ergänzung in Klammern hinzugefügt werden.
Wie seht ihr das? -- H005 10:22, 22. Nov. 2006 (CET)
- Das muss man im Einzelfall entscheiden. Bei den von Dir angegebenen Beispielen gebe ich Dir Recht – mit Ausnahme der Schifffahrt. Wenn die International Hydrographic Organisation anfängt, Karten nicht mehr in Seemeilen zu beschriften, ist der Zeitpunkt gekommen, auch hierbei nochmal nachzudenken. -- Pemu 02:55, 27. Dez. 2006 (CET)
-
- Beim Editieren des Artikels Noble (Auto) bin ich auch wieder mal auf viele PS-Angaben gestoßen - ich bin auch dafür, in der Regel nur SI-Einheiten zu schreiben, bei kW/PS die PS-Angabe eben in Klammern zusätzlich für die ewig-gestrigen. --AFranK99 [Disk.] 12:01, 3. Jan. 2007 (CET)
[Bearbeiten] Hoch- und Tiefstellungen von Zahlen
Nachdem dies schon einmal auf Wikipedia Diskussion:Typografie angesprochen, dort jedoch nicht wirklich ausdiskutiert worden ist, möchte ich hier auch einmal die Frage stellen, wie in der Wikipedia Hoch- und Tiefstellungen (insbesondere von Zahlen) zu handhaben sind. Es geht darum, ob sie mit <sub> </sub> bzw. <sup> </sup> gemacht werden sollen, oder ob die entsprechenden Unicode-Zeichen für hoch- und tiefgestellte Zahlen verwendet werden sollen/dürfen.
Ich poste hier noch einmal meinen Standpunkt über die Unicode-Zeichen für hoch/tiefgestellte Zahlen/Zeichen:
- PRO: Angaben wie km² und cm³ sind einfacher zu lesen und zu schreiben, besonders im Wiki-Quelltext.
- PRO: Hochgestellte 1, 2 und 3 werden – da sie in ISO-8859-1 definiert sind und somit in den meisten aktuellen Fonts als Glyph enthalten sind – auf fast allen Ausgabemedien "anständig" dargestellt.
- CONTRA: Screen-Reader können mit den HTML-Tags sinnvollere Ausgaben erzeugen als mit den doch eher exotischen Unicode-Zeichen.
- CONTRA: Andere hochgestellte Zahlen und Symbole, sowie tiefgestellte Zahlen und Symbole sind nur in Unicode-Fonts enthalten und fehlen dort oftmals sogar. Damit ist eine "anständige" Darstellung dieser Zeichen auf vielen Ausgabemedien nicht mehr gewährleistet.
- CONTRA: Unicode besitzt nur wenige Symbole in hoch- und tiefgestellter Form (0 bis 9, n, +, -, =, ( und )). Komplexere Ausdrücke können nicht dargestellt werden. z.B. geht CO2, aber NOx geht schon nicht mehr. (NOn ist doch eher unüblich, und bei CxHy braucht man 2 Variablen, was in tiefgestellten Unicodezeichen ebenfalls nicht geht.
Mein Kompromissvorschlag: ¹, ² und ³ dürfen verwendet werden, die anderen Zeichen sollten vermieden werden und durch <sub> </sub> bzw. <sup> </sup> ersetzt werden.
Was haltet ihr davon? --RokerHRO 15:38, 11. Dez 2005 (CET)
- Ergänzung: ¹ ² ³ sollten nicht mit <sub> und <sup> gemischt werden, da das Ergebnis extrem hässlich aussieht. Also nicht x²2 oder x2² sondern x22 oder besser gleich TeX
 benutzen. --RokerHRO 15:46, 11. Dez 2005 (CET)
benutzen. --RokerHRO 15:46, 11. Dez 2005 (CET)
-
- Für mathematische Texte nur TeX; wozu man ¹ braucht, ist mir nicht klar; bei "feststehenden Ausdrücken" wie km² spricht aus meiner Sicht nichts gegen ² oder ³.--Gunther 19:11, 11. Dez 2005 (CET)
[Bearbeiten] Schreibweise von Hitparadenplatzierungen
Hallo!
Eigentlich sollen ja Zahlen von eins bis zwölf in Fließtexten ausgeschrieben werden. Bei Hitparadenplatzierungen kommt mir diese Konvention aber sehr komisch vor. Beispielsweise würde ich eher „Diese Single erreichte Platz 1 der Charts.“ schreiben als „Diese Single erreichte Platz eins der Charts.“. Letzteres ist meiner Meinung nach unüblich. Sieht das eine Mehrheit auch so wie ich? Rechtfertigt so etwas eine Ausnahmeregelung für den Absatz „Zahlen null bis zwölf als Fließtext“? --SteBo 08:15, 10. Feb 2006 (CET)
- Diese Zahl qualifiziert kein Substantiv wie in normalem Fließtext, sondern ist eine Referenz auf eine Zahl. Ebenso "siehe Kapitel 3" (nicht "Kapitel drei") oder "Wir sitzen in Reihe 5, Plätze 11 und 12". Sollte man evtl. ergänzen, aber ich glaube nicht, dass nennenswerte Anzahlen von Autoren hier Fehler begehen.
- Ich finde die Regel "eins bis zwölf" aber ohnehin fragwürdig. Meines Erachtens geht es hier um Lesbarkeit. Ich würde es eher so formulieren: Grundsätzlich sind alle Zahlen auszuschreiben, sofern dies nicht die Lesbarkeit erschwert. Also z. B.: "Ich habe dir hundert mal gesagt, ...", nicht "ich habe dir 100 mal gesagt, dass ..." In Verbindung mit Einheiten finde ich Zahlen oft besser, also etwa "Entenhausen liegt 7 km nördlich von Gnudorf.", nicht "liegt sieben Kilometer nördlich von ..." Meines Erachtens hilft bei dem ganzen Thema Fingerspitzengefühl weiter als in Stein gemeißelte Regeln. -- H005 09:13, 10. Feb 2006 (CET)
[Bearbeiten] Zahlen von Null bis zwölf als Fließtext
Ein Jahr ist was anderes als 1 Jahr. Wenn es mir auf die genaue Zahl ankommt, dann nehme ich Ziffern. Dafür sind sie da. Fünfe kann man mal gerade sein lassen, 5 nicht. Fingalo 18:41, 9. Mai 2006 (CEST)
- Ich halte das für eine reine Stilfrage. Was ist an „1 Jahr“ präziser als an „ein Jahr“? Das ist doch wirklich Geschmackssache. Ziffern sind hauptsächlich dazu da, um damit zu rechnen, nicht, um damit zu schreiben. --jpp ?! 20:49, 9. Mai 2006 (CEST)
"ein" ist auch ein unbestimmter Artikel, daher mehrdeutig. Aber ich möchten den Nuancenreichtum erhalten und schreibe daher: "Ein Domkapitel hatte in der Regel in Anlehnung an die Zwölf Apostel 12 Chorherren." oder: "Wegen Krankheit eines Mitglieds hatte der Elferrat bei dieser Karnevalsveranstaltung nur 10 Mitglieder auf dem Podium." Fließtext würde mich da stören. Aber wenn's Geschmackssache ist, dann ist die Aufforderung von 0 - 12 Fließtext zu verwenden unverbindlich. Fingalo 11:35, 10. Mai 2006 (CEST)
- Es ist lediglich mehrdeutig, um welches Exemplar es sich handelt, wenn ich „ein Exemplar“ schreibe. Eindeutig ist die Anzahl der bezeichneten Exemplare, nämlich genau eines, nicht zwei, nicht drei und auch kein halbes. Die von dir unterstellte Unterscheidung in der Semantik existiert nicht. --jpp ?! 12:20, 10. Mai 2006 (CEST)
Das "mehrdeutig" bezog sich auf die Aussageabsicht. "Ein Mann steigt in den Zug ..." Da will ich nicht sagen, dass es genau einer war, sondern dass es irgendeiner war, auf dessen Identität es nicht ankommt. Darüberhinaus können durchaus noch mehr Männer in den Zug steigen, die aber für den Fortgang der Geschichte nicht von Belang sind. Schreibe ich "1 Mann steigt in den Zug ...", dann will ich zum Ausdruck bringen, dass es mir darauf ankommt, dass da nicht mehrere Männer einsteigen. Das ist eben ein Unterschied. Ob der "semantisch" ist oder nicht, ist mir dabei wurscht! Fingalo 14:58, 10. Mai 2006 (CEST)
[Bearbeiten] Schreibweise von Zahlwörtern
Die Million wird nach DIN 5008 mit „Mio.“ abgekürzt. Im Lemma City-Tunnel (Leipzig) hat Benutzer:La Sarre meine dementsprechende Änderung rückgängig gemacht (anscheinend hat er/sie sich vorgenommen, mich zu nerven wo immer möglich) mit dem Hinweis Enzyklopädie, da wird wenig abgek., siehe WP:NK - aber dort gab's natürlich nix zu dem Thema! Hat er/sie mal wieder schlecht recherchiert - oder ganz einfach mal wieder Müll erzählt! Sei's drum, hier bin ich dann doch wohl jetzt richtig, aber trotzdem gibt's hier bislang nichts zu dem Thema. Also: „571,62 Millionen Euro“ oder das etwas kürzere und damit m.E. besser lesbare „571,62 Mio. €“ ...?!? Axpde 15:07, 1. Mär. 2007 (CET)
Wir schreiben eine Enzyklopädie und da schreibt man Zahlen und Maße im Fließtext aus. Warum bist du so schwierig? --Held des Wissens 20:44, 1. Mär. 2007 (CET)
- Wer sagt denn, dass man in einer Enzyklopädie Zahlen und Maße im Fließtext ausschreibt? Ich habe dazu jedenfalls keine Regel gefunden! Im Übrigen finde ich es doch schon seltsam, dass der selbsternannte '„Held des Wissens“ meint, mich neuerdings überall kritisieren zu müssen und dann auch noch behauptet, ich sei schwierig ... Axpde 23:31, 4. Mär. 2007 (CET)
- Warum tauchst du überall auf wo es was mit Benutzer:La Sarre zu tun hat? Schon komisch. --BLueFiSH ✉ (Klick mich!) 21:27, 1. Mär. 2007 (CET) Gern geschehen für die Vorlage, die ich dir jetzt zum Worte-im-Mund-umdrehen wieder gegegeben hab.
- Die Antwort hast du selbst gegeben. ist schon komisch, wo du nämlich immer auftauschst, passt echt zum Hobby und einfach Newbies nicht in Ruhe lassen kannst, sondern wieder mit Verdächtigungen unter Umgehung des Daten- und Persönlichkeitssschutzes überziehen willst, siehe hier. Wird Zeit dass Herr Dix von [10]
- ein Schreiben erhält zur Stellungnahme. Es geht dich alles ein Scheiß an, weil keiner von denen, die du misstraust, außer einer, dauerhaft gesperrt ist, der oder die können schreiben unter einem neuem Nick, wie er oder sie immer wollen, ob es ein oder zwei Personen oder wer auch immer ist. Man braucht ja mehrere Nicks oder eine IP damit du mit deinen Internetstalking (oder der von jcornelius!) gegenüber einer Person, wo du anscheinend auch völlig Fremde reinziehst, endlich mal aufhörst. Und mindestens einen Nutzer hast du ja damit schon eh vertrieben. Wieviel Opfer willst du noch haben für deinen Privatkrieg gegen einen längst freiwillig abgemeldeten Accounts? Was hat das mit dem Neutralitätsgebot eines Admins noch zu tun? Hör auf damit oder gib die Knöpfe ab. Was du machst hat mit dem Erstellen einer Enzyklopädie nichts mehr zu tun. --88.134.164.106 00:56, 5. Mär. 2007 (CET)
-
- Mit dem Nachsatz spielst Du wohl auf die Tatsache an, dass La Sarre – der/die unter diesem Namen erst seit neuestem existiert – gerade stets an den Stellen auftaucht, an denen ich bereits etwas geschrieben habt? In der Tat, seltsam, aber es reicht ein Blick in die Versionsliste, um festzustellen, dass La Sarre mich verfolgt und nicht umgekehrt! Axpde 23:31, 4. Mär. 2007 (CET)
-
-
- Axpde, beachte bitte die Einrückung, ich meinte nicht Dich, sondern in diesem Fall Held des Wissens. --BLueFiSH ✉ (Klick mich!) 05:56, 5. Mär. 2007 (CET)
-
-
-
-
- Oh, 'tschuldigung, die Einrückerei hat mich tatsächlich ein wenig verwirrt, trotzdem war es bestimmt nicht verkehrt, mal auf Ursache und Wirkung hinzuweisen ... Die ganze Diskussion entzieht sich so lang meinem Verständnis, was das ganze eigentlich soll :( Axpde 07:59, 5. Mär. 2007 (CET)
-
-
[Bearbeiten] formatnum
Muss, soll oder kann hier diskutiert werden:
- Dass die Funktion
{{formatnum:}}mindestens alle WP Schreibweisen abdecken muss? Dass Komma Null eine Genauigkeitsangabe ist und zur Ausgabe gehört?Ursache wo anders-- visi-on 10:13, 22. Mär. 2007 (CET)
-- visi-on 09:35, 22. Mär. 2007 (CET)
- Kannst du konkreter werden, wo du zur Zeit Probleme siehst und wie sie zu beheben sind? sebmol ? ! 10:00, 22. Mär. 2007 (CET)
- unschön ist wenn ich mit Runden relevante Stellen verliere
{{formatnum:{{#expr:1.001round2}}}}ergibt 1 statt 1,00. Könnte man durch einen Rundungsparameter in der Funktion beheben. - Tausendertrennzeichen sollten erst ab fünf Stellen verwendet werden, ausser bei Vergleichen. Auch hier könnte ein Parameter abhelfen.
-- visi-on 10:30, 22. Mär. 2007 (CET)
Beispiel: {{formatnum:12345|TTZ='|DTZ=.|round=2}} für 12'345.00 CHF -- visi-on 10:42, 22. Mär. 2007 (CET)
[Bearbeiten] Änderungen zur Abkürzungen und geschützten Leerzeichen
Ich habe nach Bestätigung durch einer Schnellumfrage im Chat folgende Änderung rückgängig gemacht: [11].
Begründung:
- Die Erkenntnis das bekannte und geläufige Abkürzungen schlechter lesbar seien als die ausgeschrieben Variante bezweifle ich und würde sogar das Gegenteil behaupten, denn km/h wird schneller gelesen als Kilometer pro Stunde. Gibt es dazu vielleicht wissenschaftliche Erkennisse? Des weiteren wäre zu berücksichtigen, dass diese Änderung der Vorgaben eine Vielzahl von Kleinstediten nach sich ziehen würde, also sollte es vorher auch von der Mehrheit getragen werden.
- Die Aussage zu den geschützten Leerzeichen teile ich nicht, denn die Lesbarkeit der Artikel geht doch eindeutig vor der Lesbarkeit des Quelltextes. Für die Bearbeitung wird den Autoren durch die Mediawiki-Syntax sowieso schon einiges abverlangt (ich sage nur Vorlagen), so dass es an einem nicht liegen kann.
--Revvar (D Tools) 11:25, 10. Mai 2007 (CEST)
- Wie schon im Chat gesagt, bin ich deiner Meinung. Abgekürzte Einheiten sind für mich die normalste Sache der Welt, und die Lesbarkeit eines Textes wird durch ausgeschriebene Einheiten auch nicht besser. --Raymond Disk. Bew. 11:38, 10. Mai 2007 (CEST)
-
- Nichts gegen abgekürzte Einheiten, aber eben nur dort, wo es auch notwendig ist. km/h kann zum Beispiel weiterhin abgekürzt werden, aber bei km und % ist das etwas anderes – warum sollte man das nicht ausschreiben? Ausgeschrieben sind derartige Abkürzungen a) besser zu lesen und passen b) besser in einen Fließtext (in Tabellen ist es wieder etwas anderes). Zum geschützten Leerzeichen: Wenn man eure Richtlinie umsetzen würde, wären die Artikel nachher mit derartigen Dingern vollkommen durchsetzt. Aber der Schaden ist hier größer als der zu erwartende Nutzen: Die Abschreckung durch geschützte Leerzeichen ist weitaus größer als jener durch ein, zwei falsche Zeilenumbrüche, die ansonsten zustande kommen. Wir sollten bei diesem Problem auf eine softwareseitige Lösung warten, eh wir ganz Wikipedia mit zuplfastern. --Tolanor 11:55, 10. Mai 2007 (CEST)
Ich schlage vor, die Empfehlungen der PTB [12] (Kapitel 4, S. 14) zu diskutieren und ggf. als Grundlage zu verwenden. --80.129.116.52 11:51, 10. Mai 2007 (CEST)
- Gerade beim %-Zeichen würde diese neue Handhabe eine Lawine an Änderungen auslösen, wenn ich nur die ganzen Werkstoffe denke. Meiner Meinung nach lässt sich die Ausschreibung der beiden Abkürzungen eher selten umsetzen. Mir fehlt grad ein Beispiel, wo dies machbar wäre, ohne den Lesefluss zu unterbrechen, aber auch bei Länderartikeln (rausgegriffen Alaska und nachfolgende) werden beispielsweise durchgehend die Abkürzungen verwendet. Nach Beispielen mit Ausschreibung muss man wirklich suchen. Also, für mich steht der Arbeitsaufwand in keinem Verhältnis zum eventuellen Nutzen. -- Ra'ike D C B 12:40, 10. Mai 2007 (CEST)
Ich denke, ob eine Einheit abgekürzt oder ausgeschrieben wird, ist eine stilistische Frage und kann getrost den einzelnen Autorinnen und Autoren überlassen werden. Wenn die Einheit aber abgekürzt wird, dann sollte auf jeden Fall auch das „ “ verwendet werden, weil Umbrüche zwischen Zahl und Einheit den Lesefluss sehr stören. Hier ist mir die Lesbarkeit für Leser deutlich wichtiger als die Lesbarkeit des Quelltextes. --jpp ?! 12:53, 10. Mai 2007 (CEST) PS: Das ist jetzt zu 100
% mein Senf. ;-)
Von den Empfehlungen der PTB würde ich die Sachen übernehmen, welche beschreiben was man nicht machen sollte. Der Rest wird dort ja auch offengelassen. Also keine "drei km", bei zusammgesetzte Einheiten und in Gleichungen immer kurz, keine Kombinationen wie "Kilogramm/s". Aber eigentlich macht man dies doch automatisch nicht, also bräuchte es auch keine expliziten Regeln dazu. --Revvar (D Tools) 13:14, 10. Mai 2007 (CEST)
- Dort heißt es (erster Satz): "Innerhalb vollständiger Sätze sollten Einheitennamen ausgeschrieben werden, wenn es sich um einzelne Größenwerte handelt und um Einheiten mit eigenen Namen." Klar, das, was sowieso niemand macht, kann man hier weglassen. --80.129.116.52 13:24, 10. Mai 2007 (CEST)
- Und so, als Empfehlung, nicht als Gesetz, könnte man es hier übernehmen. Die Abkürzung "cm" bezieht sich übrigens auf die veraltete Schreibweise, vielleicht wird deswegen weniger gern "Zentimeter" geschrieben. --80.129.116.52 13:52, 10. Mai 2007 (CEST)
Wer sagt denn, dass wenn eine Empfehlung (denn darum handelt es sich hier) geändert wird, sofort alle Artikel damit übereinstimmen müssen? Ich handhabe es auch heute schon so, dass ich diese rausnehme, wenn ich einen Artikel sowieso schon editiere und etwa km in vollständigen Sätzen in Kilometer abändere. Es geht hier erstmal um die Änderung einer Empfehlung, alles weitere wird sich schon von alleine ändern. Obwohl bzw. gerade weil sich früher beispielsweise niemand an irgendwelche Typografie-Regeln gehalten hat, hat jemand die Empfehlung Wikipedia:Typografie ins Leben gerufen, die heute auch meist umgesetzt wird. --Tolanor 17:20, 10. Mai 2007 (CEST)
- Und ich beispielsweise setze das „ “ ein, wann immer ich es aus Layout-technischen Gründen für sinnvoll halte. So arbeiten wir denn beide fröhlich gegeneinander. Ist aber m. E. nicht tragisch, solange wir das nur nebenbei erledigen und keine eigenen Bearbeitungen dafür durchführen. --jpp ?! 17:30, 10. Mai 2007 (CEST)
-
- Dann wäre es jetzt vielleicht mal sinnvoll, sich zu einigen. Zwei sich widersprechende Richtlinien sind nicht wirklich toll. Mein Vorschlag: Ein technikbegabter Benutzer arbeitet einen Vorschlag für eine softwareseitige Lösung aus und schlägt sie auf Bugzilla vor (bzw. gibt’s da schon was?). --Tolanor 17:35, 10. Mai 2007 (CEST)
-
-
- Es gibt schon was, ziemlich lange: Bug 3461: Syntax extensions: special character for non-breaking space ( ). --Raymond Disk. Bew. 17:50, 10. Mai 2007 (CEST)
-
-
-
-
- Hm, der Vorschlag dort scheint eher problematisch zu sein, wenn ich es richtig verstehe. Kann man die Diskussion dort irgendwie wieder in Gang bringen? --Tolanor 18:04, 10. Mai 2007 (CEST)
-
-
Als Verursacher der Diskussion stelle ich fest, dass die von mir als auch anderen Nutzern vorgenommene Änderungen von Abkürzungen in Vollwörter auch im betreffenden Artikel richtig war und die IP-Sperre als auch die Reverts dafür weniger bis nicht rechtens. --193.17.243.3 19:03, 10. Mai 2007 (CEST)
- Was war denn der betreffende Artikel? Sorry, hab das nicht mitgekriegt. --Tolanor 19:23, 10. Mai 2007 (CEST)
Bremen und Bremen (Land). Da habe ich die Abk. ersetzt, das wurde revertiert; später entdeckte ich, dass ein anderer schon vorher die gleichen Verbesserungen vornahm, was auch schon revertiert wurde. Ich habe es dann auch wiedeBei anderen Artikeln hatte ich damit nie Probleme erlebt. --193.17.243.3 19:45, 10. Mai 2007 (CEST)
- Hab das mal zurückgesetzt, so geht es natürlich nicht. Ich denke, mittlerweile dürften wir uns hier einig sein, die Empfehlungen des PTB was das Ausschreiben von Einheiten angeht zu benutzen. --Tolanor 21:41, 10. Mai 2007 (CEST)
-
- Wie kommst du darauf? Es sind dort nur Kann-Vorschläge, für uns nicht bindend. Letztlich zählt nur, dass es bisher hier nach Ermessen des Autors gehandhabt wurde. Warum sollte man das ändern? Es gibt hier kein eindeutiges Bild, was von den beiden Varianten nun lesbarer wäre. Ich sehe weder was solch eine Kovention rechtfertigt, noch das sie mehrheitsfähig ist. Sämtliche Kleinstedits die nur sowas ändern sind unerwünscht. Deshalb war auch der Revert der Edits der Pöbel-IP aus dem Bundestag korrekt. Warum du die nun wieder einfügen musstest verstehe ich nicht. --Revvar (D Tools) 22:14, 10. Mai 2007 (CEST)
-
-
- Wörter wie „Pöbel-IP“ sollte man optimalerweise mit Links belegen, zum Glück hab ich es auch selbst gefunden. Das ändert jedoch nichts daran, dass die IP Recht hatte. Warum sollte man den Empfehlungen der PTB denn nicht folgen? Wir haben hier eine objektive Quelle, die zufälligerweise deine Meinung nicht bestätigt, also wird sie natürlich einfach ignoriert. So kommen wir weiter. Ich bin übrigens meist auch der Meinung, man solle möglichst viel den Autoren überlassen, aber es hat einfach nicht jeder Artikel einen Hauptautor, und allgemeine Empfehlungen gibt es für alles in der Wikipedia – warum also nicht auch hierfür? „Sämtliche Kleinstedits die nur sowas ändern sind unerwünscht“ – Zustimmung. Aber eigentlich richtige Edits zurückzusetzen und einen Artikel deswegen zu sperren ist genauso überflüssig. --Tolanor 23:31, 10. Mai 2007 (CEST)
- Ich ignoriere die PTB nicht, wie kommst du darauf? Oben bin ich doch bereits darauf eingegangen. Deine Begründung der Ablehung der Argumente von jpp und Ra'ike finde ich hingegen nirgends. Mir ist noch immer unklar auf welcher Grundlage wir hier Empfehlungen aussprechen sollen, die der bisherigen Praxis dermaßen widersprechen. Die PTB formuliert es selbst schwammig und die paar klar formulierten Sachen sind Selbstverständlichkeiten. Zumal die Vergangenheit doch gelehrt hat, dass es hier darauf nicht ankommt ob es Empfehlungen oder Regeln sind. Sobald hier etwas steht wird es genutzt um solche Kleinsteditwars durchzuführen. Ich persönlich hätte kein Problem mich daran zu halten, aber ich sehe keine Mehrheiten und ein Haufen Ärger wegen solcher Korrekturen, der Editwar heute hat dies doch bestätigt. --Revvar (D Tools) 00:02, 11. Mai 2007 (CEST)
- Wörter wie „Pöbel-IP“ sollte man optimalerweise mit Links belegen, zum Glück hab ich es auch selbst gefunden. Das ändert jedoch nichts daran, dass die IP Recht hatte. Warum sollte man den Empfehlungen der PTB denn nicht folgen? Wir haben hier eine objektive Quelle, die zufälligerweise deine Meinung nicht bestätigt, also wird sie natürlich einfach ignoriert. So kommen wir weiter. Ich bin übrigens meist auch der Meinung, man solle möglichst viel den Autoren überlassen, aber es hat einfach nicht jeder Artikel einen Hauptautor, und allgemeine Empfehlungen gibt es für alles in der Wikipedia – warum also nicht auch hierfür? „Sämtliche Kleinstedits die nur sowas ändern sind unerwünscht“ – Zustimmung. Aber eigentlich richtige Edits zurückzusetzen und einen Artikel deswegen zu sperren ist genauso überflüssig. --Tolanor 23:31, 10. Mai 2007 (CEST)
-
-
-
-
-
- Was verstehst du bitte unter Mehrheiten? Müssen hier erst 80 Prozent der Abertausend Wikipedia-Nutzer abgestimmt haben, damit wir eine nebensächliche Regelung ändern können? Und ich habe meine Begründung gegen jpps und Raikes Argumente doch geliefert, du musst sie nur lesen. Wo formuliert die PTB in Bezug auf die Ausschreibung von Einheiten irgendwas schwammig? Nur weil da „sollten“ steht? Natürlich kann die PTB derart Nebensächliches nicht zum Gesetz erheben und womöglich alle bestrafen, die es anders machen. Und den Ärger gab es nur, weil die Richtlinien eben momentan falsch sind und sich gegenseitig widersprechen. --Tolanor 00:11, 11. Mai 2007 (CEST)
- Ach bitte nicht so viel Überspitzung, da fehlt mir die Lust zu. Ich sehe wirklich deine Gegenargumente zu Ra'ike und jpp nicht. Wäre nett wenn du mir da auf Sprünge helfen könntest. Einen Widerspruch in der Richtlinien sehe ich bei den geschützten Leerzeichen ebenfalls nicht. Gibt es da noch weitere? --Revvar (D Tools) 00:50, 11. Mai 2007 (CEST)
- Was verstehst du bitte unter Mehrheiten? Müssen hier erst 80 Prozent der Abertausend Wikipedia-Nutzer abgestimmt haben, damit wir eine nebensächliche Regelung ändern können? Und ich habe meine Begründung gegen jpps und Raikes Argumente doch geliefert, du musst sie nur lesen. Wo formuliert die PTB in Bezug auf die Ausschreibung von Einheiten irgendwas schwammig? Nur weil da „sollten“ steht? Natürlich kann die PTB derart Nebensächliches nicht zum Gesetz erheben und womöglich alle bestrafen, die es anders machen. Und den Ärger gab es nur, weil die Richtlinien eben momentan falsch sind und sich gegenseitig widersprechen. --Tolanor 00:11, 11. Mai 2007 (CEST)
-
-
-
-
-
-
-
-
-
- Rai'kes Argument war der Arbeitsaufwand, dagegen argumentierte ich hier. Jpp meinte, dass man sowas dem Hauptautor überlassen solle, dazu ich: „Ich bin übrigens meist auch der Meinung, man solle möglichst viel den Autoren überlassen, aber es hat einfach nicht jeder Artikel einen Hauptautor, und allgemeine Empfehlungen gibt es für alles in der Wikipedia – warum also nicht auch hierfür?“ Und ja, es gibt noch die Richtlinie Wikipedia:Wie gute Artikel aussehen#Quelltext, die dem hier widerspricht. --Tolanor 15:33, 12. Mai 2007 (CEST)
-
-
-
-
-
-
-
-
-
-
-
-
-
- Das hat aber erstmal nichts mit dem Ausschreiben von Einheiten zu tun, denn da braucht man geschützte Leerzeichen imho sowieso nicht. Natürlich ist die Lesbarkeit des Artikels im Endeffekt wichtiger als die Lesbarkeit des Quelltextes. Darum unterstütze ich auch Richtlinien wie etwa Wikipedia:Typografie – sie verbessern das Aussehen des Artikels, ohne dabei den Quelltext zu belasten. Wir sollten uns aber bewusst sein, dass nur ein sehr geringer Teil unserer Leser solche marginalen Änderungen überhaupt wahrnimmt. Darum richten die komplizierten im Quelltext mehr Schaden als Nutzen an, zumal sowieso bereits softwareseitige Lösungen in Arbeit sind. --Tolanor 17:15, 12. Mai 2007 (CEST)
-
-
-
-
-
-
-
[Bearbeiten] Kompromissvorschlag
- Meine Sorge bezüglich des Arbeitsaufwandes beruht ja vor allem auf die vielfache Verwendung der Abkürzungen bei technischen und werkstoffkundlichen Artikeln. Ich denke, bei solchen Artikeln macht es wirklich wenig Sinn, die Einheiten auch im Fließtext auszuschreiben. In Länder- oder Stadtartikeln werden sich in der Regel nur wenige Maße und Prozentangaben finden. Man könnte also die Ausschreibung der Abkürzung auf nichttechnische Artikel beschränken.
- Ebenfalls erwähnt werden sollte auch (wie in der o.g. PDF beschrieben) die Art der Schreibweise bei zusammengesetzten Abkürzungen (m/s, kg/dm3 immer abgekürzt), die strikte Vermeidung von gemischten Einheiten/Formelzeichen (drei km, Kilometer/Stunde, Kilogramm/m3 u.ä.), sowie die Ausschreibung kleiner Zahlen bis Zwölf.
- Auf die geschützten Leerzeichen sollte bei Abkürzungen und in Formeln wirklich nicht verzichtet werden, zumindest nicht, solange es keine andere technische Lösung gibt (und die scheint es ja in absehbarer Zeit nicht zu geben). Es stört den Lesefluss und sieht zudem albern aus, wenn Zahl und Einheit beim Zeilenumbruch voneinander getrennt werden.
Soweit mein Kompromissvorschlag. Gruß -- Ra'ike D C B 02:29, 13. Mai 2007 (CEST)
- @Tolanor: Bei geschützten Leerzeichen sind unsere Meinungen wohl nicht vereinbar. Eine softwareseitige Lösung wäre sicher das Beste,ich glaube da kaum an Fortschritte in nächster Zeit. Sollte es soweit sein, kann ein Bot oder MediaWiki selbst problemlos die Dinger wieder entfernen. Geschützte Leerzeichen benötigt man übrigens auch bei ausgeschriebenen Einheiten, oder bei mehrteiligen Abkürzungen (sofern die nicht sowieso ausgeschrieben werden sollten).
- Meine Befürchtung ist, dass ein solcher Gestaltungsvorschlag wieder mit einer "gegen alle Widerstände durchzusetzenden Regel" verwechselt wird. Ich hoffe die hier beteiligten Admins sind sich dessen bewusst und gebieten solchen Treiben dann konsequent Einhalt. Ich würde mich Ra'ikes Vorschlag deshalb anschließen, es scheint mir ein gangbarer Kompromiss. --Revvar (D Tools) 13:20, 13. Mai 2007 (CEST)
-
- Ich würde dem Kompromissvorschlag ebenfalls zustimmen, allerdings mit einer Einschränkung: Da wir uns bezüglich der geschützten Leerzeichen offensichtlich nicht einig werden (ich bin übrigens nicht der einzige, der diese Dinger lieber aus seinen Artikeln rauslassen möchte), sollten wir in dieser Frage hier vielleicht möglichst keine Empfehlung aussprechen. Das würde auch der Forderung nach Autorenautonomie entsprechen, die oben geäußert wurde. --Tolanor 17:51, 13. Mai 2007 (CEST)
- Der Vorschlag ist diskussionswürdig, neben den geschützten Leerzeichen halte ich lediglich die Ausschreibung von Zahlen bis 12 für fragwürdig. Dass diese Zahlen immer ausgeschrieben werden müssen, würde ich als urban legend verbuchen, auch bei diesen Zahlen kommt es auf den Zusammenhang an. -- Carbidfischer Kaffee? 20:44, 13. Mai 2007 (CEST)
-
- Hab's aus dem Absatz Maßeinheiten wieder rausgenommen, weil doppelt gemoppelt (siehe auch Zahlen von null bis 12 als Fließtext). Die Ausschreibung kleiner Zahlen wird aber auch im gleichnamigen Artikel behandelt. Da müsste man sich gegebenenfalls im Lexikon der deutschen Sprachlehre schlaumachen.
- Wegen der geschützten Leerzeichen und der geforderten Autorenautonomie ist aus dem sollte jetzt ein kann geworden. Ich selbst setze das geschützte Leerzeichen auch nicht immer, wenn z.B. die Wahrscheinlichkeit, dass Zahl und Einheit im Text durch Zeilenumbruch getrennt werden, gering ist. Bei Formeln, vor allem chemischen Formeln ist dies in meinen Augen aber unumgänglich. Gruß -- Ra'ike D C B 21:44, 13. Mai 2007 (CEST)
In dem Lexikon, das vor allem grammatische Fragen ausführlich behandelt, steht hierzu einfach nur "Schreibung in Buchstaben (Zahlen von 1 bis 12 werden meist in Buchstaben gedruckt)." Meine Ausgabe ist von 1986 (94 Seiten), vielleicht steht in der neueren, nochmals erweiterten Ausgabe von 1997 (108 Seiten) mehr dazu. --80.129.107.20 23:52, 13. Mai 2007 (CEST)
Hier ist eine ausführliche Arbeit über Graphische Elemente der geschriebenen Sprache von Peter Gallmann (übrigens einer der Schweizer für die Zwischenstaatliche Kommission für die deutsche Rechtschreibung). In § 1000 auf Seite 224 werden Regeln zur Frage „Ziffern oder Buchstaben?“ vorgeschlagen. --80.129.107.20 00:31, 14. Mai 2007 (CEST)
- Danke für den Hinweis, das klingt doch sehr vernünftig, was Peter Gallmann dort vorschlägt. Insbesondere sagt er erfreulicherweise nicht, dass genau die Zahlen 1–12 immer ausgeschrieben werden. Weitere Meinungen dazu? -- Carbidfischer Kaffee? 08:02, 14. Mai 2007 (CEST)
-
- Dem kann ich nur beipflichten. Klingt jedenfalls logischer als die starre Regel "Nur kleine Ziffern".
- Der Absatz Wikipedia:Schreibweise von Zahlen#Zahlen null bis zwölf im Fließtext müsste also folgendermaßen umgeschrieben werden:
- Ziffern oder Buchstaben?
- Da die Regeln, wann im Fließtext Ziffern und wann Buchstaben zu schreiben sind, in den "Richtlinien für den Schriftsatz" des Dudens nur unzureichend festgelegt sind, hält sich die Wikipedia an die von Peter Gallmann in seiner Publikation Graphische Elemente der geschriebenen Sprache vorgeschlagenen Grundregeln [1]; Zitat:
- 1) Ein- und zweisilbige Zahlen (vor allem eins bis zwölf, aber auch sechzehn, vierzig, hundert) werden in allgemeinen Texten in Buchstaben gesetzt.
- ''Was drei wissen, wissen bald dreißig. Wenn zwei sich streiten, freut sich der Dritte. Die Bilanz der hundert Tage nach dem Regierungswechsel ist wenig erfreulich. Beate wird dieses Jahr fünfzehn Jahre alt
- Gelegentlich werden - etwa in belletristischen Werken - auch längere Zahlen in Buchstaben gesetzt.
- Sie ist vor ein paar Tagen siebenundfünfzig Jahre alt geworden.
- 2) Alle übrigen Zahlen werden in Ziffern gesetzt.
- Im Jahre 1985 (nicht: im Jahre neunzehnhundertfünfundachtzig)
- Eine Ausnahme bildet die Buchstabenschreibung auf Formularen im Banken- und Postwesen, hier als Sicherheitsmaßnahme neben der Ziffernschreibung.
- 3) Ziffernschreibung und die Verwendung gewisser Abkürzungen und Sonderzeichen bedingen sich zum Teil; die folgenden Kombinationen sind erlaubt:
- 12 km, 25 %, 40 $
- 12 Kilometer, 25 Prozent, 40 Dollar
- zwölf Kilometer, fünfundzwanzig Prozent, vierzig Dollar
- Aber nicht die vierte denkbare Kombination:
- zwölf km, fünundzwanzig %, vierzig $
- 4) Auch kurze Zahlen werden in Ziffern gesetzt, wenn sie mit längeren im gleichen Kontext stehen oder wenn die Zahlen Vergleichswert haben.
- Die Vorlage wurde mit 24 gegen 5 Stimmen (nicht: mit 24 gegen fünf Stimmen) abgelehnt. Der FCS hat 3:5 Toren gewonnen. (Inventar:) Es fehlen 2 Schraubenzieher und 1 Beißzange.
- Ziffernschreibung ist ferner allein üblich in Listen und Tabellen.
- 5) Wenn Grundzahlen eine Position, einen Rang, eine Reihenfolge oder eine Nummer ausdrücken, werden sie meist in Ziffern gesetzt, ebenso die Ordnungszahlen beim Datum und bei Herrschernamen.
- Sie nahm die Straßenbahnlinie 14. Er wohnt an der Hauptstraße 25. Obwohl sie die Startnummer 46 hatte, landete sie auf Platz 1. Bei diesem Lexikon enthält der Band VI das Register. Ihre Kundennummer ist 24645. Wir treffen uns wieder am 5. April 1986. Die letzte Kalenderreform geschah unter Papst Gregor XIII.
- Gruß und auch von mir ein Dank an die IP -- Ra'ike D C B 21:56, 14. Mai 2007 (CEST)
Ich habe hier im Duden-Newsletter einige Hinweise gefunden: http://www.duden.de/deutsche_sprache/newsletter/archiv.php?id=173#was Ich zitiere mal:
„Was die Schreibung von Zahlen betrifft, so herrscht oft Verwirrung darüber, ob und wann man sie nun in Ziffern oder in Buchstaben schreiben muss. Hier können wir allgemein Entwarnung geben: Eine früher gültige Buchdruckerregel, nach der generell die Zahlen von 1 bis 12 in Buchstaben und die Zahlen ab 13 in Ziffern zu schreiben sind, gilt heute nicht mehr! Es gibt jedoch nach wie vor einige Gepflogenheiten, an die man sich halten kann:
Die Zahlen von 1 bis 12 werden überwiegend dann in Ziffern geschrieben, wenn sie – z. B. in Statistiken oder wissenschaftlichen Texten – zusammen mit dem dazugehörigen Substantiv die Aufmerksamkeit auf sich lenken sollen: Kurbel mit 2 Wellen; Zahnrad mit 2 Spindeln.
Auch vor Zeichen, Abkürzungen von Maßen, Gewichten, Geldsorten usw. ist die Zahl in Ziffern zu schreiben: 3 km; 7,4 kg; 6 EUR.
Steht statt der Abkürzung die entsprechende Vollform, kann man sowohl in Ziffern als auch in Buchstaben schreiben: 11 Kilometer/elf Kilometer; 2 Euro/zwei Euro.
Andererseits können die Zahlen von 13 an, sofern sie übersichtlich sind, auch ausgeschrieben werden, wie es z. B. in erzählenden Texten (Roman, Brief o. Ä.) geschieht: Sie wurde siebenundsiebzig Jahre alt. Zu Ihrem fünfzigsten Geburtstag gratuliere ich Ihnen herzlich.
Ansonsten werden nur ein- und zweisilbige Zahlwörter ausgeschrieben: Über hundert Teilnehmer sind schon angemeldet. Sie besitzt fünfzehn Katzen. Hab tausend Dank!“– Duden Sprachberatung
-- Gkai 00:22, 24. Jun. 2007 (CEST)
[Bearbeiten] Exponentialdarstellung: ² und ³
Die Unicodezeichen ² und ³ aus der Sonderzeichenleiste unter dem Bearbeitungsfenster sollen nicht verwendet werden, da diese in Kombination mit anderen hochgestellten Zahlen oder Minuszeichen unschön sind.
Dem kann ich so pauschal nicht zustimmen. In vielen Artikeln steht nur einmal mm² oder m³ drin. Ein hoch 4 etc. ist da nicht zu erwarten. Die Schreibweise m<sup>3</sup>, also m3, verursacht da nicht nur schwerer lesbaren Wiki-Quelltext, sondern in den meisten Browsern auch eine unschöne Vergrößerung der Zeilenhöhe.
Ich will jetzt gar nicht unbedingt fordern, dass überall die Unicode-Sonderzeichen ⁰⁴⁵⁶⁷⁸⁹ und ₀₁₂₃₄₅₆₇₈₉ verwendet werden. Die sind recht schwierig einzugeben, und ob die überall richtig angezeigt werden, weiß ich auch nicht. Aber ² und ³ funktionieren definitiv überall, sind auf der deutschen Tastatur einzugeben und sehen besser aus. Ich würde deshalb vorschlagen, den obigen Satz zu streichen oder zumindest zu relativieren. --Head 15:27, 6. Sep. 2007 (CEST)
- Die Diskussion dazu war diese hier: Wikipedia:Fragen zur Wikipedia/Archiv/2007/Woche 25#Format hochgestellter Zahlen --80.129.76.26 16:06, 6. Sep. 2007 (CEST)
[Bearbeiten] einheitliche Schreibweise Nicht-Dezimalzahlen?
In vielen Artikeln werden andere Basen genommen, etwa 2 oder 16. Wie sollten diese Zahlen formatiert werden? Die Schreibweise mit dem Präfix 0x mag ja für C- und Javaprogrammierer verständlich sein, aber außerhalb der Programmiererwelt ist das sicher keine allgemeinverständliche Notation. Ich habe in einigen Artikeln die 0x1234 in 1234hex geändert, weiß aber nun nicht, ob Nicht-Informatiker oder Nicht-Mathematiker mit dieser Kennzeichnung mehr anfangen können. Eine unter Mathematikern recht übliche Notation ist meines Wissens wohl 1234(16), welche den Vorteil hat, beliebige Basen zu unterstützen.
Was haltet ihr davon, eine einigermaßen einheitliche Notation in der Wikipedia anzustreben? Artikel, die eindeutig zu einem Fachbereich gehören, wo es bereits eine übliche Notation gibt (etwa oben genannte Programmiersprachen-Bereiche), sind davon natürlich freigestellt. --RokerHRO 00:02, 19. Dez. 2007 (CET)
- Ich verwende immer die Variante 123416, also ohne die Klammern, weil ich die im Informatik-Studium so kennengelernt habe. Zur Not könnte ich mich wohl auch an die Klammern gewöhnen, obwohl ich im Zweifelsfall immer die kürzeste Variante bevorzuge. Aber, nebenbei bemerkt, haben wir eigentlich schon irgendwo einen Artikel, der sich zum Thema Schreibweise von Zahlen mit unterschiedlichen Basen auslässt? Falls ja, könnte man ja mal lesen, was dort so steht. Stellenwertsystem schweigt sich zur Notation aus. --jpp ?! 11:12, 19. Dez. 2007 (CET)
-
- Es gibt eben bisher keine Konvention in der Wikipedia dafür. Darum stelle ich das Thema hier ja zur Diskussion. Die tiefgestellte Basis an der Zahl ist in gedruckten Vorlesungsskripten und Büchern gut erkennbar, aber im Webbrowser so eine Sache, da z.B. die Erkennbarkeit als Basis/Tiefstellung nicht so ausgeprägt wie im Druck/PDF ist, daher die Klammerschreibweise, die selbst auf Textmodus-Browsern noch einigermaßen entzifferbar ist.
- Das von mir in der Wikipedia (und anderswo) verwendete tiefgestellte hex hat IMHO den Vorteil, dass es sofort - für jemanden, der Hexadezimalzahlen kennt - verständlich ist, was gemeint ist. Andere Basen außer 2 und 16 kommen ja auch nur sehr selten vor; Binärzahlen meines Wissens auch nur in Artikeln, die explizit im Text erwähnen, dass es sich um Binärzahlen handelt, wohingegen Hexadezimalzahlen in sehr vielen Artikeln aus dem Bereich Informatik/Technik vorkommen, ohne gesondert als solche erwähnt zu werden. Daher würde ich in diesen Artikeln eine möglichst laienkompatible Notation bevorzugen.
- Laienkompatibel meint, dass etwa gutgemeinte Verschlimmbesserungen von
<sub>16</sub>in<sup>16</sup>oder Ähnliches möglichst unterbleiben. --RokerHRO 11:28, 19. Dez. 2007 (CET)
-
-
- Diese Art von Verschlimmbesserungen habe ich bisher noch nicht erlebt und halte sie für kein ernsthaftes Problem. Das „hex“ ist meiner Meinung nach für jemanden, der mit der x-Notation („0x1234“) nix anfangen kann, ebenso unverständlich wie diese. Außerdem hilft es bei anderen Systemen (zur Basis 2, 8 oder 12) nicht weiter. Vielleicht wäre es ja hilfreich, die tiefgestellte Zahl beim ersten Auftreten innerhalb eines Artikels mit einem Link auf das passende Zahlsystem zu versehen? Also beispielsweise „123416“. --jpp ?! 12:38, 19. Dez. 2007 (CET)
-
-
-
-
- Verlinken ist auf jeden Fall eine sehr gute Idee. Hilft bei den Binärpräfixen zwar auch oft nur bedingt, aber vielleicht werden einige unfreiwillige Vandalen dann abgehalten. :-) --RokerHRO 13:47, 19. Dez. 2007 (CET)
-
-
-
-
-
-
- Ich halte es im allgemeinen für keine gute Idee hier Hexadezimalzahlen zu verwenden. Als Informatiker ist man gewohnt damit zu arbeiten. Aber damit gehört man einfach einer Minderheit an. Der Grossteil der Leser wird mit den Zahlen nichts anfangen können. Eine andere Notation würde zwar erreichen, dass der Leser weiß mit welchem Zahlensystem er es zu tun hat, doch er würde immer noch zum Taschenrechner greifen müssen um die Werte in ein ihm bekanntes Zahlensystem umzuwandeln. --Stefan2 00:07, 2. Feb. 2008 (CET)
-
-
-
[Bearbeiten] Rufnummern und Einleitungstext
Abschnitt "Rufnummern" eingefügt. Einleitungstext angepasst. -- Cristof 03:10, 27. Mai 2008 (CEST)
- Und wozu? In das Lexikon gehört ausdrücklich keine einzige Rufnummer (außer "112" in Notruf), siehe WP:WWNI Punkt 7.2: "Bei Artikeln über Institutionen, Unternehmen oder Gesellschaften sind die Angabe von Postanschrift, Telefonnummer, E-Mail-Adressen oder Ansprechpartnern unerwünscht." Das gilt natürlich erst recht für andere Personen. --80.129.72.244 10:38, 27. Mai 2008 (CEST)
-
- Du hast natürlich vollkommen Recht. War wohl ein Schnellschuss von mir, man sollte so spät nichts mehr ändern. Rufnummernbezogenes habe ich wieder entfernt. Nebenbei: Warum vesteckst du dich hinter einer IP? -- Cristof 22:23, 27. Mai 2008 (CEST)
-
-
- Das sehe ich nicht als "Verstecken" – im Ernstfall lässt sich die IP zurückverfolgen. Ich schreibe nicht gleichzeitig angemeldet, es ist also kein Doppelspiel von meiner Seite. Es ist keine tiefe Überzeugung, aber zur Zeit bin ich der Ansicht, dass die Gründe dafür leicht überwiegen und es der von mir angestrebten mehr inhaltlichen als administrativen Verantwortung besser entspricht (kritischeres Gegenlesen durch andere, Auseinandersetzungen etwas weniger persönlich). --80.129.121.26 10:21, 28. Mai 2008 (CEST)
-


{kind=link}